 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for Unsupervised Image-to-Image Translation
Paper and Code
May 07, 2021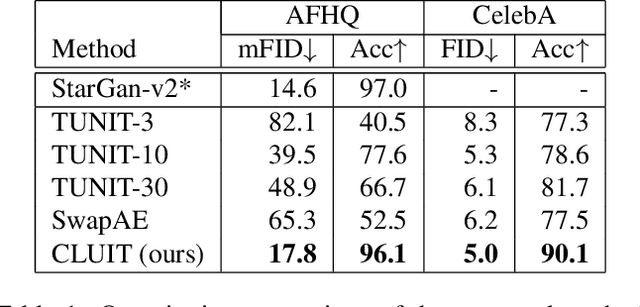

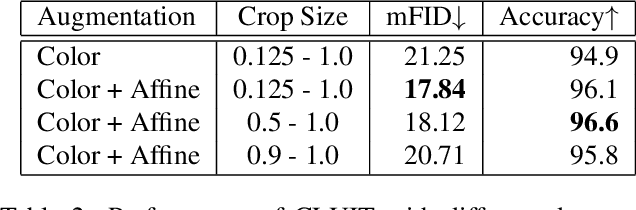

Image-to-image translation aims to learn a mapping between different groups of visually distinguishable images. While recent methods have shown impressive ability to change even intricate appearance of images, they still rely on domain labels in training a model to distinguish between distinct visual features. Such dependency on labels often significantly limits the scope of applications since consistent and high-quality labels are expensive. Instead, we wish to capture visual features from images themselves and apply them to enable realistic translation without human-generated labels. To this end, we propose an unsupervised image-to-image translation method based on contrastive learning. The key idea is to learn a discriminator that differentiates between distinctive styles and let the discriminator supervise a generator to transfer those styles across images. During training, we randomly sample a pair of images and train the generator to change the appearance of one towards another while keeping the original structure. Experimental results show that our method outperforms the leading unsupervised baselines in terms of visual quality and translation accuracy.