 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Linear Attention
Jun 09, 2026The scalability of Large Language Models (LLMs) to long contexts is fundamentally constrained by the quadratic complexity of standard attention, motivating the adoption of linear attention mechanisms with sub-quadratic cost. To improve representation capacity under long contexts, recent approaches organize memory in a multi-state manner. However, existing multi-state linear attention methods rely on fixed state merging policies that cannot adapt to dynamically varying token importance, irreversibly obscuring critical tokens and causing severe error accumulation over long sequences. To address this limitation, we propose DLA, a dynamic memory modeling framework for multi-state linear attention. DLA introduces (i) Information-Aware Dynamic State Merging, which adaptively determines state boundaries based on token-level information variation, preserving high-resolution representations around semantic transitions while aggressively summarizing stable regions, and (ii) Capacity-Bounded Memory Modeling, which maintains a fixed-size, chronologically ordered state cache by selectively merging adjacent low-information states to control memory growth with minimal information loss. We pre-train DLA on two different linear attention models and evaluate on 16 datasets across three categories. Experimental results demonstrate the superiority of DLA over state-of-the-art.
MARS: Harmonizing Multimodal Convergence via Adaptive Rank Search
Feb 28, 2026Fine-tuning Multimodal Large Language Models (MLLMs) with parameter-efficient methods like Low-Rank Adaptation (LoRA) is crucial for task adaptation. However, imbalanced training dynamics across modalities often lead to suboptimal accuracy due to negative interference, a challenge typically addressed with inefficient heuristic methods such as manually tuning separate learning rates. To overcome this, we introduce MARS (Multimodal Adaptive Rank Search), an approach to discover optimal rank pairs that balance training dynamics while maximizing performance. Our key innovation, a proposed framework of dual scaling laws, enables this search: one law models module-specific convergence time to prune the search space to candidates with aligned dynamics, while the other predicts final task performance to select the optimal pair from the pruned set. By re-purposing the LoRA rank as a controller for modality-specific convergence speed, MARS outperforms baseline methods and provides a robust, automated strategy for optimizing MLLM fine-tuning.
TC-LoRA: Temporally Modulated Conditional LoRA for Adaptive Diffusion Control
Oct 10, 2025
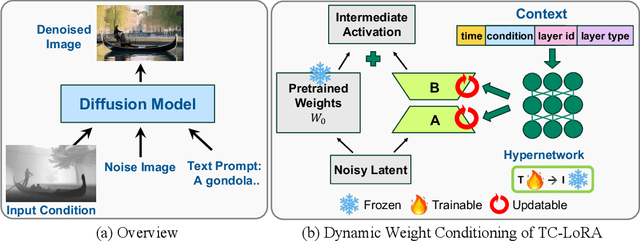


Current controllable diffusion models typically rely on fixed architectures that modify intermediate activations to inject guidance conditioned on a new modality. This approach uses a static conditioning strategy for a dynamic, multi-stage denoising process, limiting the model's ability to adapt its response as the generation evolves from coarse structure to fine detail. We introduce TC-LoRA (Temporally Modulated Conditional LoRA), a new paradigm that enables dynamic, context-aware control by conditioning the model's weights directly. Our framework uses a hypernetwork to generate LoRA adapters on-the-fly, tailoring weight modifications for the frozen backbone at each diffusion step based on time and the user's condition. This mechanism enables the model to learn and execute an explicit, adaptive strategy for applying conditional guidance throughout the entire generation process. Through experiments on various data domains, we demonstrate that this dynamic, parametric control significantly enhances generative fidelity and adherence to spatial conditions compared to static, activation-based methods. TC-LoRA establishes an alternative approach in which the model's conditioning strategy is modified through a deeper functional adaptation of its weights, allowing control to align with the dynamic demands of the task and generative stage.
Cocoon: Robust Multi-Modal Perception with Uncertainty-Aware Sensor Fusion
Oct 16, 2024
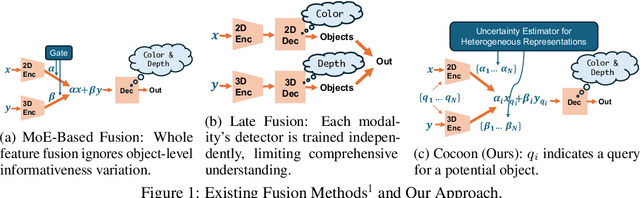
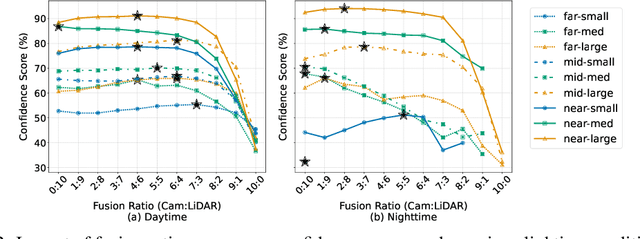
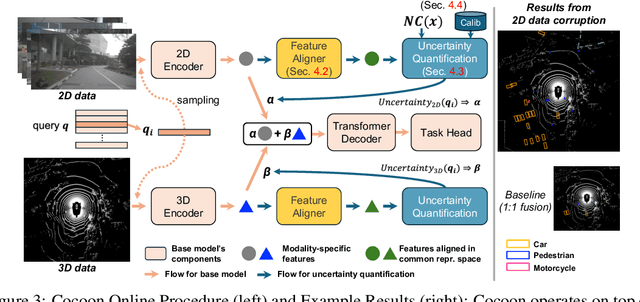
An important paradigm in 3D object detection is the use of multiple modalities to enhance accuracy in both normal and challenging conditions, particularly for long-tail scenarios. To address this, recent studies have explored two directions of adaptive approaches: MoE-based adaptive fusion, which struggles with uncertainties arising from distinct object configurations, and late fusion for output-level adaptive fusion, which relies on separate detection pipelines and limits comprehensive understanding. In this work, we introduce Cocoon, an object- and feature-level uncertainty-aware fusion framework. The key innovation lies in uncertainty quantification for heterogeneous representations, enabling fair comparison across modalities through the introduction of a feature aligner and a learnable surrogate ground truth, termed feature impression. We also define a training objective to ensure that their relationship provides a valid metric for uncertainty quantification. Cocoon consistently outperforms existing static and adaptive methods in both normal and challenging conditions, including those with natural and artificial corruptions. Furthermore, we show the validity and efficacy of our uncertainty metric across diverse datasets.
Achieving the Safety and Security of the End-to-End AV Pipeline
Sep 05, 2024
In the current landscape of autonomous vehicle (AV) safety and security research, there are multiple isolated problems being tackled by the community at large. Due to the lack of common evaluation criteria, several important research questions are at odds with one another. For instance, while much research has been conducted on physical attacks deceiving AV perception systems, there is often inadequate investigations on working defenses and on the downstream effects of safe vehicle control. This paper provides a thorough description of the current state of AV safety and security research. We provide individual sections for the primary research questions that concern this research area, including AV surveillance, sensor system reliability, security of the AV stack, algorithmic robustness, and safe environment interaction. We wrap up the paper with a discussion of the issues that concern the interactions of these separate problems. At the conclusion of each section, we propose future research questions that still lack conclusive answers. This position article will serve as an entry point to novice and veteran researchers seeking to partake in this research domain.
ADoPT: LiDAR Spoofing Attack Detection Based on Point-Level Temporal Consistency
Oct 23, 2023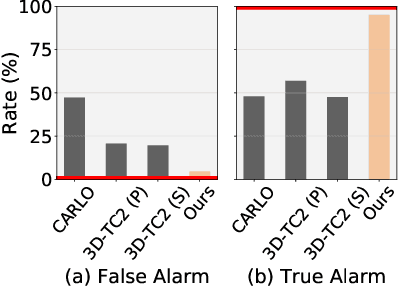



Deep neural networks (DNNs) are increasingly integrated into LiDAR (Light Detection and Ranging)-based perception systems for autonomous vehicles (AVs), requiring robust performance under adversarial conditions. We aim to address the challenge of LiDAR spoofing attacks, where attackers inject fake objects into LiDAR data and fool AVs to misinterpret their environment and make erroneous decisions. However, current defense algorithms predominantly depend on perception outputs (i.e., bounding boxes) thus face limitations in detecting attackers given the bounding boxes are generated by imperfect perception models processing limited points, acquired based on the ego vehicle's viewpoint. To overcome these limitations, we propose a novel framework, named ADoPT (Anomaly Detection based on Point-level Temporal consistency), which quantitatively measures temporal consistency across consecutive frames and identifies abnormal objects based on the coherency of point clusters. In our evaluation using the nuScenes dataset, our algorithm effectively counters various LiDAR spoofing attacks, achieving a low (< 10%) false positive ratio (FPR) and high (> 85%) true positive ratio (TPR), outperforming existing state-of-the-art defense methods, CARLO and 3D-TC2. Furthermore, our evaluation demonstrates the promising potential for accurate attack detection across various road environments.
DynaMIX: Resource Optimization for DNN-Based Real-Time Applications on a Multi-Tasking System
Feb 03, 2023As deep neural networks (DNNs) prove their importance and feasibility, more and more DNN-based apps, such as detection and classification of objects, have been developed and deployed on autonomous vehicles (AVs). To meet their growing expectations and requirements, AVs should "optimize" use of their limited onboard computing resources for multiple concurrent in-vehicle apps while satisfying their timing requirements (especially for safety). That is, real-time AV apps should share the limited on-board resources with other concurrent apps without missing their deadlines dictated by the frame rate of a camera that generates and provides input images to the apps. However, most, if not all, of existing DNN solutions focus on enhancing the concurrency of their specific hardware without dynamically optimizing/modifying the DNN apps' resource requirements, subject to the number of running apps, owing to their high computational cost. To mitigate this limitation, we propose DynaMIX (Dynamic MIXed-precision model construction), which optimizes the resource requirement of concurrent apps and aims to maximize execution accuracy. To realize a real-time resource optimization, we formulate an optimization problem using app performance profiles to consider both the accuracy and worst-case latency of each app. We also propose dynamic model reconfiguration by lazy loading only the selected layers at runtime to reduce the overhead of loading the entire model. DynaMIX is evaluated in terms of constraint satisfaction and inference accuracy for a multi-tasking system and compared against state-of-the-art solutions, demonstrating its effectiveness and feasibility under various environmental/operating conditions.
Data-free mixed-precision quantization using novel sensitivity metric
Mar 18, 2021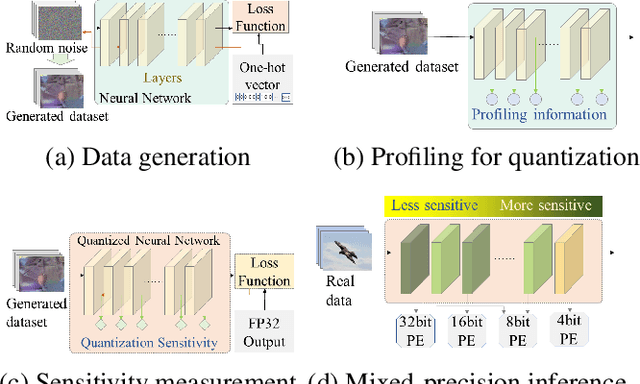
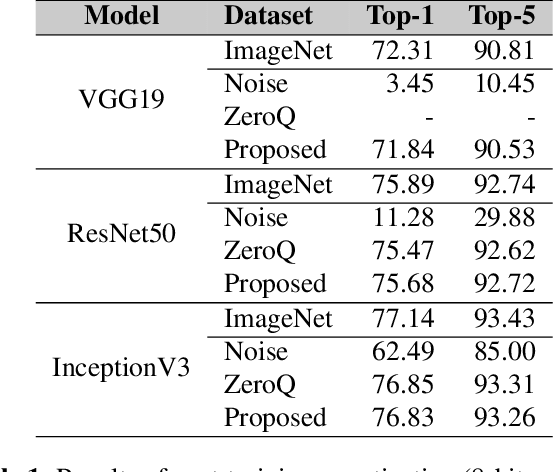
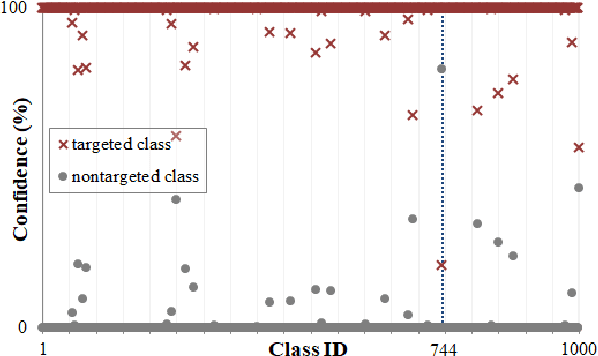
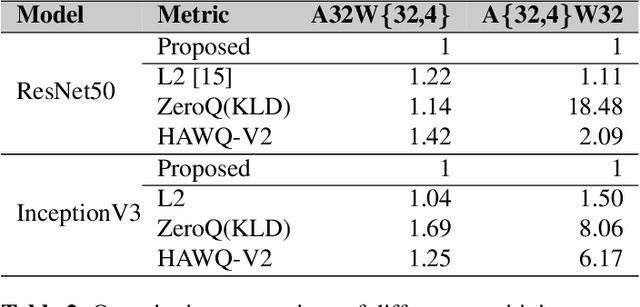
Post-training quantization is a representative technique for compressing neural networks, making them smaller and more efficient for deployment on edge devices. However, an inaccessible user dataset often makes it difficult to ensure the quality of the quantized neural network in practice. In addition, existing approaches may use a single uniform bit-width across the network, resulting in significant accuracy degradation at extremely low bit-widths. To utilize multiple bit-width, sensitivity metric plays a key role in balancing accuracy and compression. In this paper, we propose a novel sensitivity metric that considers the effect of quantization error on task loss and interaction with other layers. Moreover, we develop labeled data generation methods that are not dependent on a specific operation of the neural network. Our experiments show that the proposed metric better represents quantization sensitivity, and generated data are more feasible to be applied to mixed-precision quantization.
Contextual Relationship-based Activity Segmentation on an Event Stream in the IoT Environment with Multi-user Activities
Sep 20, 2016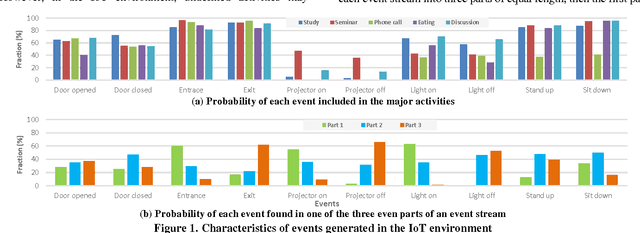
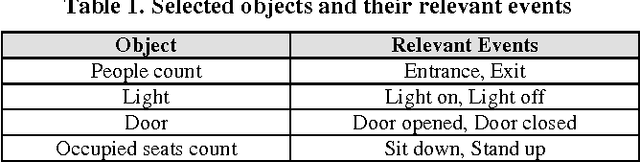
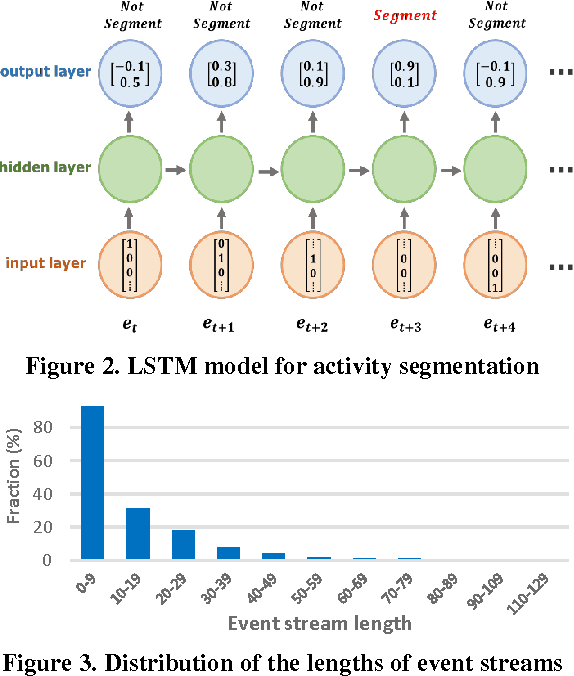
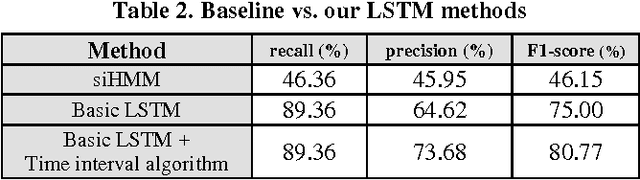
The human activity recognition in the IoT environment plays the central role in the ambient assisted living, where the human activities can be represented as a concatenated event stream generated from various smart objects. From the concatenated event stream, each activity should be distinguished separately for the human activity recognition to provide services that users may need. In this regard, accurately segmenting the entire stream at the precise boundary of each activity is indispensable high priority task to realize the activity recognition. Multiple human activities in an IoT environment generate varying event stream patterns, and the unpredictability of these patterns makes them include redundant or missing events. In dealing with this complex segmentation problem, we figured out that the dynamic and confusing patterns cause major problems due to: inclusive event stream, redundant events, and shared events. To address these problems, we exploited the contextual relationships associated with the activity status about either ongoing or terminated/started. To discover the intrinsic relationships between the events in a stream, we utilized the LSTM model by rendering it for the activity segmentation. Then, the inferred boundaries were revised by our validation algorithm for a bit shifted boundaries. Our experiments show the surprising result of high accuracy above 95%, on our own testbed with various smart objects. This is superior to the prior works that even do not assume the environment with multi-user activities, where their accuracies are slightly above 80% in their test environment. It proves that our work is feasible enough to be applied in the IoT environment.