 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNPNet: A Non-Parametric Network with Adaptive Gaussian-Fourier Positional Encoding for 3D Classification and Segmentation
Jan 31, 2026We present NPNet, a fully non-parametric approach for 3D point-cloud classification and part segmentation. NPNet contains no learned weights; instead, it builds point features using deterministic operators such as farthest point sampling, k-nearest neighbors, and pooling. Our key idea is an adaptive Gaussian-Fourier positional encoding whose bandwidth and Gaussian-cosine mixing are chosen from the input geometry, helping the method remain stable across different scales and sampling densities. For segmentation, we additionally incorporate fixed-frequency Fourier features to provide global context alongside the adaptive encoding. Across ModelNet40/ModelNet-R, ScanObjectNN, and ShapeNetPart, NPNet achieves strong performance among non-parametric baselines, and it is particularly effective in few-shot settings on ModelNet40. NPNet also offers favorable memory use and inference time compared to prior non-parametric methods
FlexMap: Generalized HD Map Construction from Flexible Camera Configurations
Jan 29, 2026High-definition (HD) maps provide essential semantic information of road structures for autonomous driving systems, yet current HD map construction methods require calibrated multi-camera setups and either implicit or explicit 2D-to-BEV transformations, making them fragile when sensors fail or camera configurations vary across vehicle fleets. We introduce FlexMap, unlike prior methods that are fixed to a specific N-camera rig, our approach adapts to variable camera configurations without any architectural changes or per-configuration retraining. Our key innovation eliminates explicit geometric projections by using a geometry-aware foundation model with cross-frame attention to implicitly encode 3D scene understanding in feature space. FlexMap features two core components: a spatial-temporal enhancement module that separates cross-view spatial reasoning from temporal dynamics, and a camera-aware decoder with latent camera tokens, enabling view-adaptive attention without the need for projection matrices. Experiments demonstrate that FlexMap outperforms existing methods across multiple configurations while maintaining robustness to missing views and sensor variations, enabling more practical real-world deployment.
David vs. Goliath: A comparative study of different-sized LLMs for code generation in the domain of automotive scenario generation
Oct 15, 2025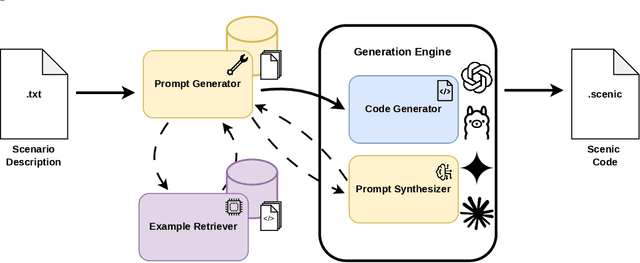



Scenario simulation is central to testing autonomous driving systems. Scenic, a domain-specific language (DSL) for CARLA, enables precise and reproducible scenarios, but NL-to-Scenic generation with large language models (LLMs) suffers from scarce data, limited reproducibility, and inconsistent metrics. We introduce NL2Scenic, an open dataset and framework with 146 NL/Scenic pairs, a difficulty-stratified 30-case test split, an Example Retriever, and 14 prompting variants (ZS, FS, CoT, SP, MoT). We evaluate 13 models: four proprietary (GPT-4o, GPT-5, Claude-Sonnet-4, Gemini-2.5-pro) and nine open-source code models (Qwen2.5Coder 0.5B-32B; CodeLlama 7B/13B/34B), using text metrics (BLEU, ChrF, EDIT-SIM, CrystalBLEU) and execution metrics (compilation and generation), and compare them with an expert study (n=11). EDIT-SIM correlates best with human judgments; we also propose EDIT-COMP (F1 of EDIT-SIM and compilation) as a robust dataset-level proxy that improves ranking fidelity. GPT-4o performs best overall, while Qwen2.5Coder-14B reaches about 88 percent of its expert score on local hardware. Retrieval-augmented prompting, Few-Shot with Example Retriever (FSER), consistently boosts smaller models, and scaling shows diminishing returns beyond mid-size, with Qwen2.5Coder outperforming CodeLlama at comparable scales. NL2Scenic and EDIT-COMP offer a standardized, reproducible basis for evaluating Scenic code generation and indicate that mid-size open-source models are practical, cost-effective options for autonomous-driving scenario programming.
On the Natural Robustness of Vision-Language Models Against Visual Perception Attacks in Autonomous Driving
Jun 13, 2025Autonomous vehicles (AVs) rely on deep neural networks (DNNs) for critical tasks such as traffic sign recognition (TSR), automated lane centering (ALC), and vehicle detection (VD). However, these models are vulnerable to attacks that can cause misclassifications and compromise safety. Traditional defense mechanisms, including adversarial training, often degrade benign accuracy and fail to generalize against unseen attacks. In this work, we introduce Vehicle Vision Language Models (V2LMs), fine-tuned vision-language models specialized for AV perception. Our findings demonstrate that V2LMs inherently exhibit superior robustness against unseen attacks without requiring adversarial training, maintaining significantly higher accuracy than conventional DNNs under adversarial conditions. We evaluate two deployment strategies: Solo Mode, where individual V2LMs handle specific perception tasks, and Tandem Mode, where a single unified V2LM is fine-tuned for multiple tasks simultaneously. Experimental results reveal that DNNs suffer performance drops of 33% to 46% under attacks, whereas V2LMs maintain adversarial accuracy with reductions of less than 8% on average. The Tandem Mode further offers a memory-efficient alternative while achieving comparable robustness to Solo Mode. We also explore integrating V2LMs as parallel components to AV perception to enhance resilience against adversarial threats. Our results suggest that V2LMs offer a promising path toward more secure and resilient AV perception systems.
Achieving the Safety and Security of the End-to-End AV Pipeline
Sep 05, 2024In the current landscape of autonomous vehicle (AV) safety and security research, there are multiple isolated problems being tackled by the community at large. Due to the lack of common evaluation criteria, several important research questions are at odds with one another. For instance, while much research has been conducted on physical attacks deceiving AV perception systems, there is often inadequate investigations on working defenses and on the downstream effects of safe vehicle control. This paper provides a thorough description of the current state of AV safety and security research. We provide individual sections for the primary research questions that concern this research area, including AV surveillance, sensor system reliability, security of the AV stack, algorithmic robustness, and safe environment interaction. We wrap up the paper with a discussion of the issues that concern the interactions of these separate problems. At the conclusion of each section, we propose future research questions that still lack conclusive answers. This position article will serve as an entry point to novice and veteran researchers seeking to partake in this research domain.