 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantization for Rapid Deployment of Deep Neural Networks
Oct 12, 2018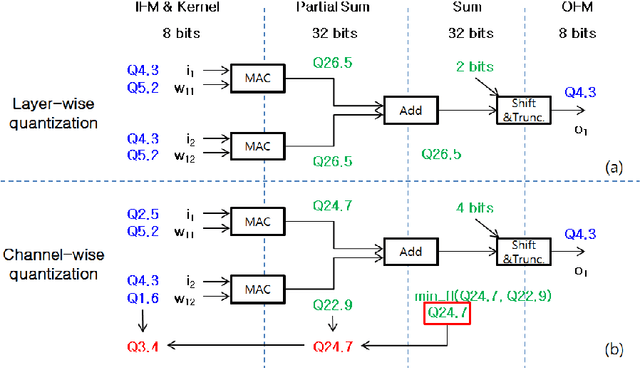
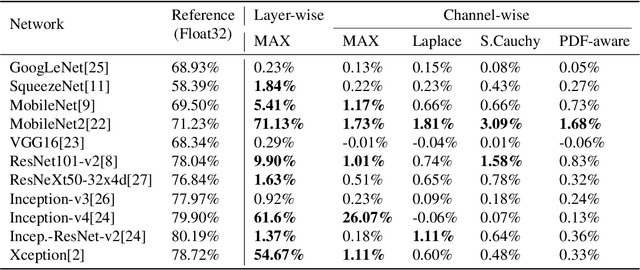
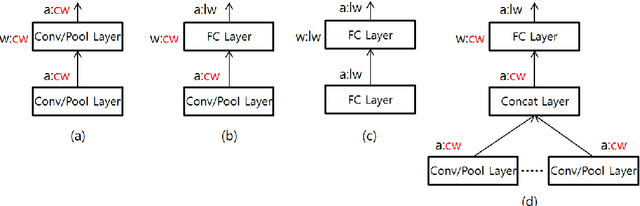

This paper aims at rapid deployment of the state-of-the-art deep neural networks (DNNs) to energy efficient accelerators without time-consuming fine tuning or the availability of the full datasets. Converting DNNs in full precision to limited precision is essential in taking advantage of the accelerators with reduced memory footprint and computation power. However, such a task is not trivial since it often requires the full training and validation datasets for profiling the network statistics and fine tuning the networks to recover the accuracy lost after quantization. To address these issues, we propose a simple method recognizing channel-level distribution to reduce the quantization-induced accuracy loss and minimize the required image samples for profiling. We evaluated our method on eleven networks trained on the ImageNet classification benchmark and a network trained on the Pascal VOC object detection benchmark. The results prove that the networks can be quantized into 8-bit integer precision without fine tuning.