 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2M: Converting Single-Turn to Multi-Turn Datasets for Conversational Question Answering
Dec 27, 2023Supplying data augmentation to conversational question answering (CQA) can effectively improve model performance. However, there is less improvement from single-turn datasets in CQA due to the distribution gap between single-turn and multi-turn datasets. On the other hand, while numerous single-turn datasets are available, we have not utilized them effectively. To solve this problem, we propose a novel method to convert single-turn datasets to multi-turn datasets. The proposed method consists of three parts, namely, a QA pair Generator, a QA pair Reassembler, and a question Rewriter. Given a sample consisting of context and single-turn QA pairs, the Generator obtains candidate QA pairs and a knowledge graph based on the context. The Reassembler utilizes the knowledge graph to get sequential QA pairs, and the Rewriter rewrites questions from a conversational perspective to obtain a multi-turn dataset S2M. Our experiments show that our method can synthesize effective training resources for CQA. Notably, S2M ranks 1st place on the QuAC leaderboard at the time of submission (Aug 24th, 2022).
Exploiting Contrastive Learning and Numerical Evidence for Improving Confusing Legal Judgment Prediction
Nov 15, 2022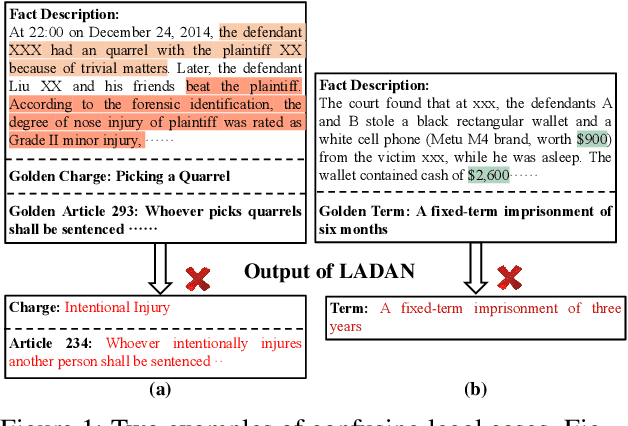
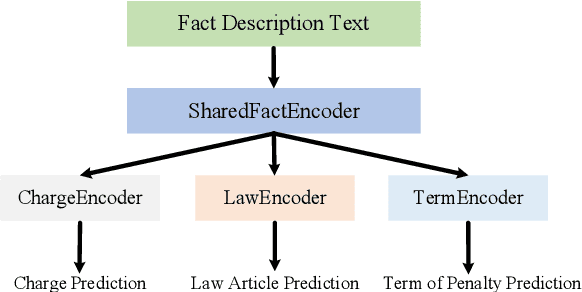

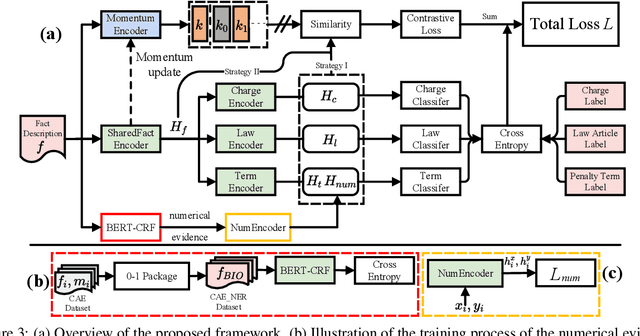
Given the fact description text of a legal case, legal judgment prediction (LJP) aims to predict the case's charge, law article and penalty term. A core problem of LJP is how to distinguish confusing legal cases, where only subtle text differences exist. Previous studies fail to distinguish different classification errors with a standard cross-entropy classification loss, and ignore the numbers in the fact description for predicting the term of penalty. To tackle these issues, in this work, first, we propose a moco-based supervised contrastive learning to learn distinguishable representations, and explore the best strategy to construct positive example pairs to benefit all three subtasks of LJP simultaneously. Second, in order to exploit the numbers in legal cases for predicting the penalty terms of certain cases, we further enhance the representation of the fact description with extracted crime amounts which are encoded by a pre-trained numeracy model. Extensive experiments on public benchmarks show that the proposed method achieves new state-of-the-art results, especially on confusing legal cases. Ablation studies also demonstrate the effectiveness of each component.