 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-hallucination Synthetic Captions for Large-Scale Vision-Language Model Pre-training
Apr 17, 2025In recent years, the field of vision-language model pre-training has experienced rapid advancements, driven primarily by the continuous enhancement of textual capabilities in large language models. However, existing training paradigms for multimodal large language models heavily rely on high-quality image-text pairs. As models and data scales grow exponentially, the availability of such meticulously curated data has become increasingly scarce and saturated, thereby severely limiting further advancements in this domain. This study investigates scalable caption generation techniques for vision-language model pre-training and demonstrates that large-scale low-hallucination synthetic captions can serve dual purposes: 1) acting as a viable alternative to real-world data for pre-training paradigms and 2) achieving superior performance enhancement when integrated into vision-language models through empirical validation. This paper presents three key contributions: 1) a novel pipeline for generating high-quality, low-hallucination, and knowledge-rich synthetic captions. Our continuous DPO methodology yields remarkable results in reducing hallucinations. Specifically, the non-hallucination caption rate on a held-out test set increases from 48.2% to 77.9% for a 7B-size model. 2) Comprehensive empirical validation reveals that our synthetic captions confer superior pre-training advantages over their counterparts. Across 35 vision language tasks, the model trained with our data achieves a significant performance gain of at least 6.2% compared to alt-text pairs and other previous work. Meanwhile, it also offers considerable support in the text-to-image domain. With our dataset, the FID score is reduced by 17.1 on a real-world validation benchmark and 13.3 on the MSCOCO validation benchmark. 3) We will release Hunyuan-Recap100M, a low-hallucination and knowledge-intensive synthetic caption dataset.
Power Line Aerial Image Restoration under dverse Weather: Datasets and Baselines
Sep 07, 2024



Power Line Autonomous Inspection (PLAI) plays a crucial role in the construction of smart grids due to its great advantages of low cost, high efficiency, and safe operation. PLAI is completed by accurately detecting the electrical components and defects in the aerial images captured by Unmanned Aerial Vehicles (UAVs). However, the visible quality of aerial images is inevitably degraded by adverse weather like haze, rain, or snow, which are found to drastically decrease the detection accuracy in our research. To circumvent this problem, we propose a new task of Power Line Aerial Image Restoration under Adverse Weather (PLAIR-AW), which aims to recover clean and high-quality images from degraded images with bad weather thus improving detection performance for PLAI. In this context, we are the first to release numerous corresponding datasets, namely, HazeCPLID, HazeTTPLA, HazeInsPLAD for power line aerial image dehazing, RainCPLID, RainTTPLA, RainInsPLAD for power line aerial image deraining, SnowCPLID, SnowInsPLAD for power line aerial image desnowing, which are synthesized upon the public power line aerial image datasets of CPLID, TTPLA, InsPLAD following the mathematical models. Meanwhile, we select numerous state-of-the-art methods from image restoration community as the baseline methods for PLAIR-AW. At last, we conduct large-scale empirical experiments to evaluate the performance of baseline methods on the proposed datasets. The proposed datasets and trained models are available at https://github.com/ntuhubin/PLAIR-AW.
Toward Building General Foundation Models for Language, Vision, and Vision-Language Understanding Tasks
Jan 12, 2023Foundation models or pre-trained models have substantially improved the performance of various language, vision, and vision-language understanding tasks. However, existing foundation models can only perform the best in one type of tasks, namely language, vision, or vision-language. It is still an open question whether it is possible to construct a foundation model performing the best for all the understanding tasks, which we call a general foundation model. In this paper, we propose a new general foundation model, X-FM (the X-Foundation Model). X-FM has one language encoder, one vision encoder, and one fusion encoder, as well as a new training method. The training method includes two new techniques for learning X-FM from text, image, and image-text pair data. One is to stop gradients from the vision-language training when learning the language encoder. The other is to leverage the vision-language training to guide the learning of the vision encoder. Extensive experiments on benchmark datasets show that X-FM can significantly outperform existing general foundation models and perform better than or comparable to existing foundation models specifically for language, vision, or vision-language understanding.
X$^2$-VLM: All-In-One Pre-trained Model For Vision-Language Tasks
Nov 22, 2022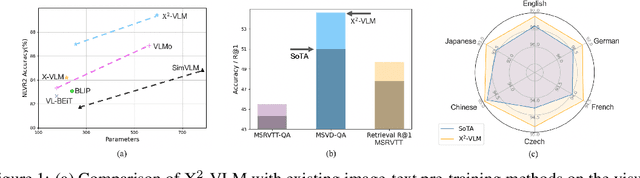
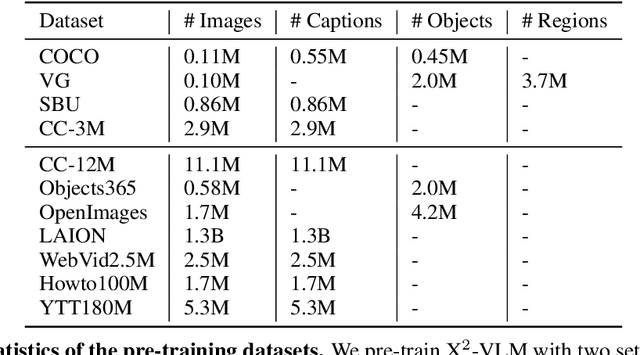
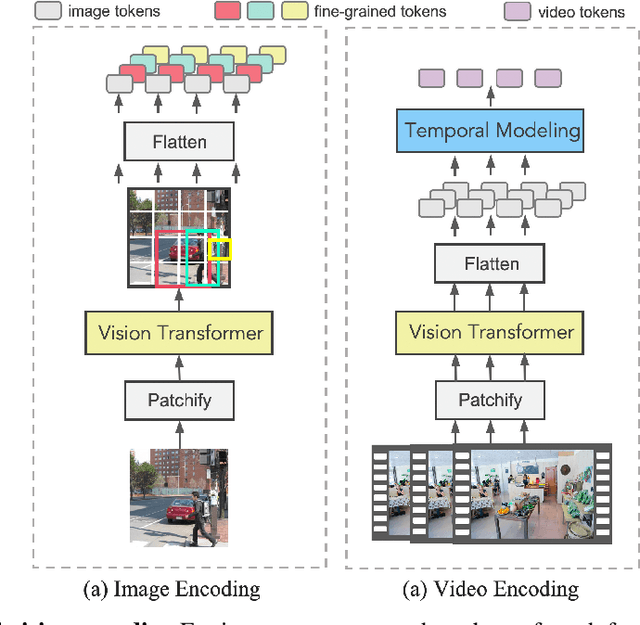

Vision language pre-training aims to learn alignments between vision and language from a large amount of data. We proposed multi-grained vision language pre-training, a unified approach which can learn vision language alignments in multiple granularity. This paper advances the proposed method by unifying image and video encoding in one model and scaling up the model with large-scale data. We present X$^2$-VLM, a pre-trained VLM with a modular architecture for both image-text tasks and video-text tasks. Experiment results show that X$^2$-VLM performs the best on base and large scale for both image-text and video-text tasks, making a good trade-off between performance and model scale. Moreover, we show that the modular design of X$^2$-VLM results in high transferability for X$^2$-VLM to be utilized in any language or domain. For example, by simply replacing the text encoder with XLM-R, X$^2$-VLM outperforms state-of-the-art multilingual multi-modal pre-trained models without any multilingual pre-training. The code and pre-trained models will be available at github.com/zengyan-97/X2-VLM.
EfficientVLM: Fast and Accurate Vision-Language Models via Knowledge Distillation and Modal-adaptive Pruning
Oct 14, 2022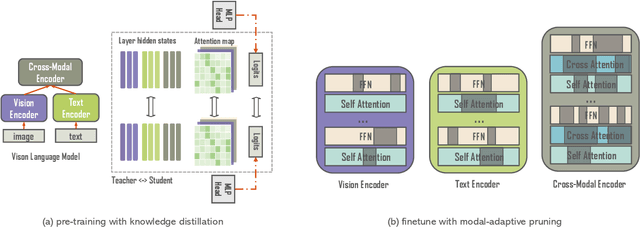
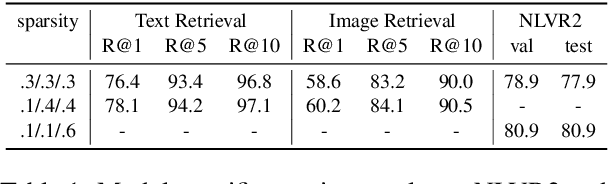
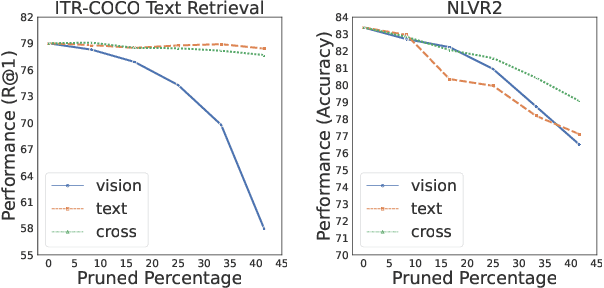
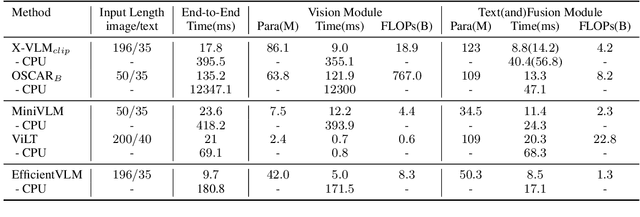
Pre-trained vision-language models (VLMs) have achieved impressive results in a range of vision-language tasks. However, popular VLMs usually consist of hundreds of millions of parameters which brings challenges for fine-tuning and deployment in real-world applications due to space, memory, and latency constraints. In this work, we introduce a distilling then pruning framework to compress large vision-language models into smaller, faster, and more accurate ones. We first shrink the size of a pre-trained large VLM and apply knowledge distillation in the vision-language pre-training stage to obtain a task-agnostic compact VLM. Then we propose a modal-adaptive pruning algorithm to automatically infer the importance of vision and language modalities for different downstream tasks and adaptively remove redundant structures and neurons in different encoders with controllable target sparsity. We apply our framework to train EfficientVLM, a fast and accurate vision-language model consisting of 6 vision layers, 3 text layers, and 3 cross-modal fusion layers, accounting for only 93 million parameters in total, which is 44.3% of the teacher model. EfficientVLM retains 98.4% performance of the teacher model and accelerates its inference speed by 2.2x. EfficientVLM achieves a large absolute improvement over previous SoTA efficient VLMs of similar sizes by a large margin on various vision-language tasks, including VQAv2 (+4.9%), NLVR2 (+5.6%), ITR (R@1 on TR +17.2%, on IR + 15.6% ) and COCO caption generation (CIDEr +6.5), demonstrating a large potential on training lightweight VLMs.
Prefix Language Models are Unified Modal Learners
Jun 15, 2022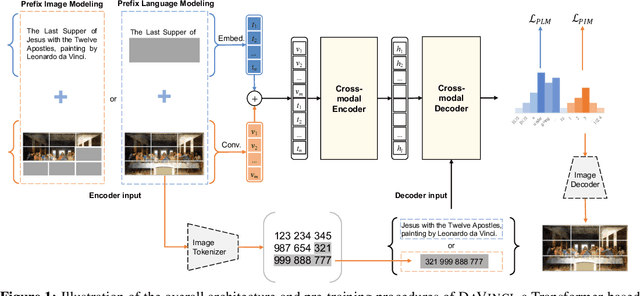
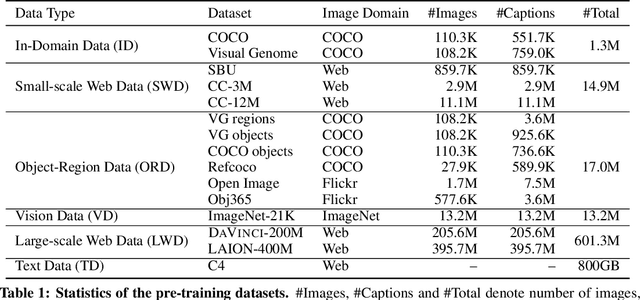
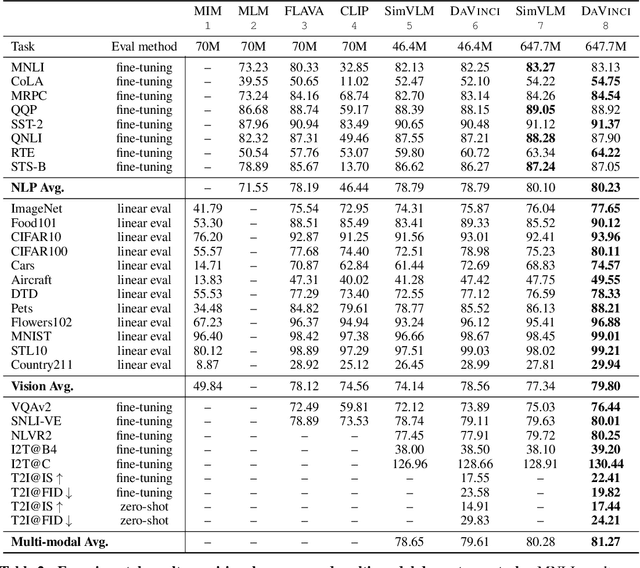

With the success of vision-language pre-training, we have witnessed the state-of-the-art has been pushed on multi-modal understanding and generation. However, the current pre-training paradigm is either incapable of targeting all modalities at once (e.g., text generation and image generation), or requires multi-fold well-designed tasks which significantly limits the scalability. We demonstrate that a unified modal model could be learned with a prefix language modeling objective upon text and image sequences. Thanks to the simple but powerful pre-training paradigm, our proposed model, DaVinci, is simple to train, scalable to huge data, and adaptable to a variety of downstream tasks across modalities (language / vision / vision+language), types (understanding / generation) and settings (e.g., zero-shot, fine-tuning, linear evaluation) with a single unified architecture. DaVinci achieves the competitive performance on a wide range of 26 understanding / generation tasks, and outperforms previous unified vision-language models on most tasks, including ImageNet classification (+1.6%), VQAv2 (+1.4%), COCO caption generation (BLEU@4 +1.1%, CIDEr +1.5%) and COCO image generation (IS +0.9%, FID -1.0%), at the comparable model and data scale. Furthermore, we offer a well-defined benchmark for future research by reporting the performance on different scales of the pre-training dataset on a heterogeneous and wide distribution coverage. Our results establish new, stronger baselines for future comparisons at different data scales and shed light on the difficulties of comparing VLP models more generally.
Cross-View Language Modeling: Towards Unified Cross-Lingual Cross-Modal Pre-training
Jun 01, 2022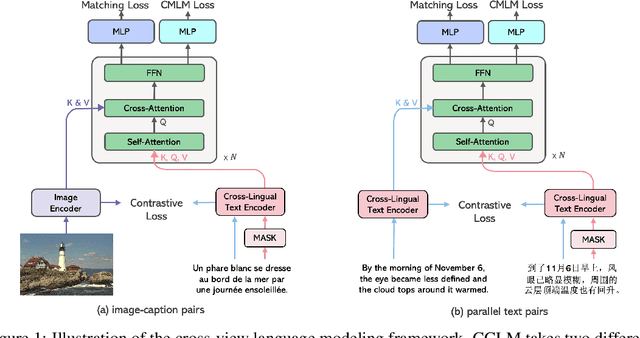
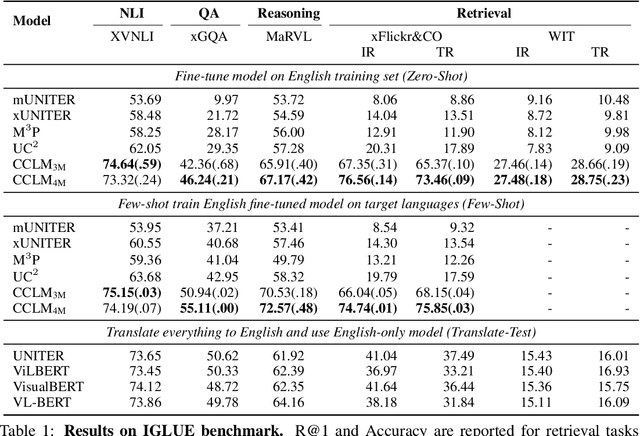
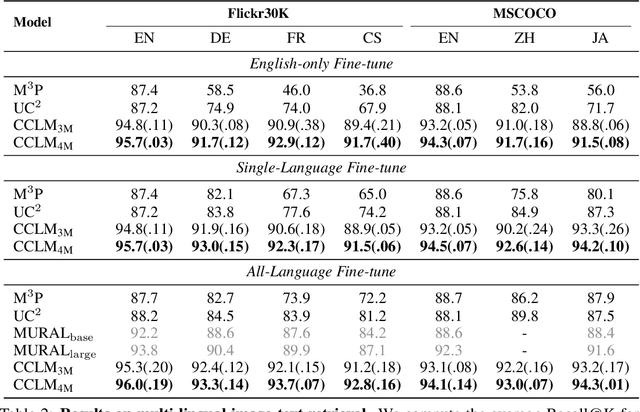
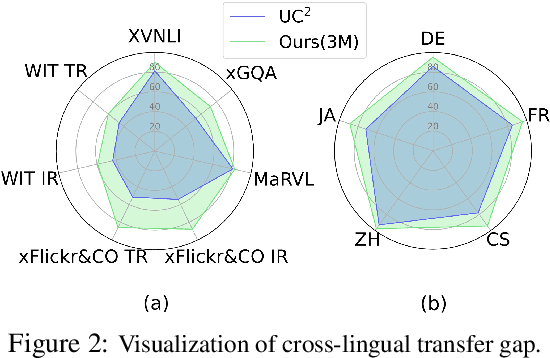
In this paper, we introduce Cross-View Language Modeling, a simple and effective language model pre-training framework that unifies cross-lingual cross-modal pre-training with shared architectures and objectives. Our approach is motivated by a key observation that cross-lingual and cross-modal pre-training share the same goal of aligning two different views of the same object into a common semantic space. To this end, the cross-view language modeling framework considers both multi-modal data (i.e., image-caption pairs) and multi-lingual data (i.e., parallel sentence pairs) as two different views of the same object, and trains the model to align the two views by maximizing the mutual information between them with conditional masked language modeling and contrastive learning. We pre-train CCLM, a Cross-lingual Cross-modal Language Model, with the cross-view language modeling framework. Empirical results on IGLUE, a multi-lingual multi-modal benchmark, and two multi-lingual image-text retrieval datasets show that while conceptually simpler, CCLM significantly outperforms the prior state-of-the-art with an average absolute improvement of over 10%. Notably, CCLM is the first multi-lingual multi-modal model that surpasses the translate-test performance of representative English vision-language models by zero-shot cross-lingual transfer.
VLUE: A Multi-Task Benchmark for Evaluating Vision-Language Models
May 30, 2022

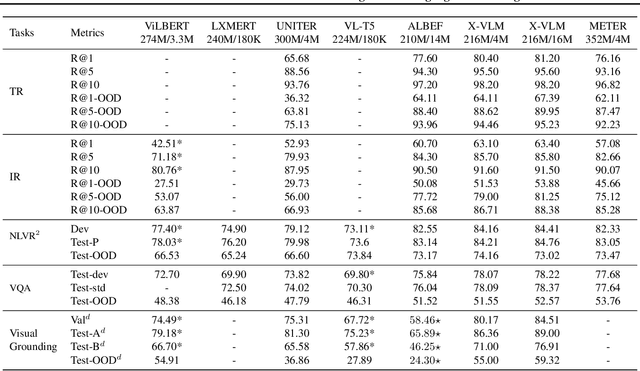
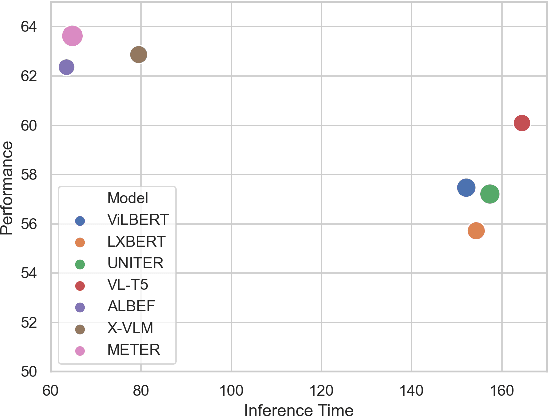
Recent advances in vision-language pre-training (VLP) have demonstrated impressive performance in a range of vision-language (VL) tasks. However, there exist several challenges for measuring the community's progress in building general multi-modal intelligence. First, most of the downstream VL datasets are annotated using raw images that are already seen during pre-training, which may result in an overestimation of current VLP models' generalization ability. Second, recent VLP work mainly focuses on absolute performance but overlooks the efficiency-performance trade-off, which is also an important indicator for measuring progress. To this end, we introduce the Vision-Language Understanding Evaluation (VLUE) benchmark, a multi-task multi-dimension benchmark for evaluating the generalization capabilities and the efficiency-performance trade-off (``Pareto SOTA'') of VLP models. We demonstrate that there is a sizable generalization gap for all VLP models when testing on out-of-distribution test sets annotated on images from a more diverse distribution that spreads across cultures. Moreover, we find that measuring the efficiency-performance trade-off of VLP models leads to complementary insights for several design choices of VLP. We release the VLUE benchmark to promote research on building vision-language models that generalize well to more diverse images and concepts unseen during pre-training, and are practical in terms of efficiency-performance trade-off.
Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts
Nov 16, 2021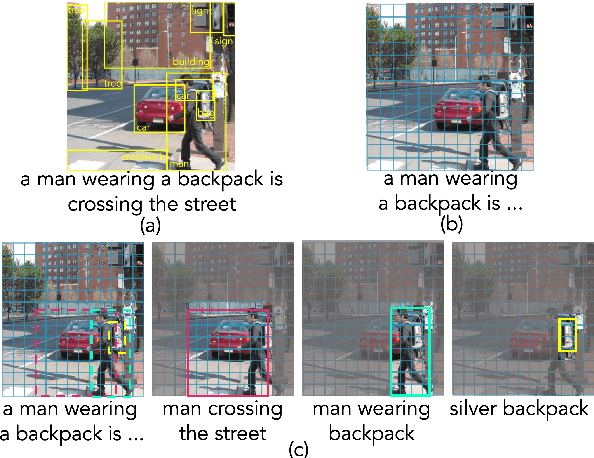
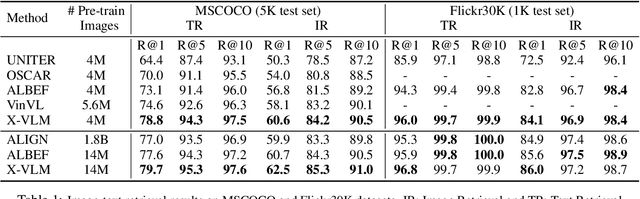
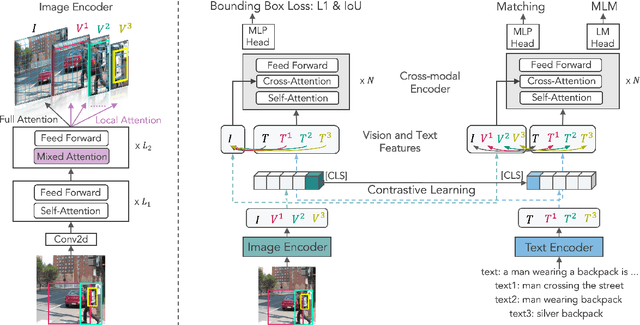
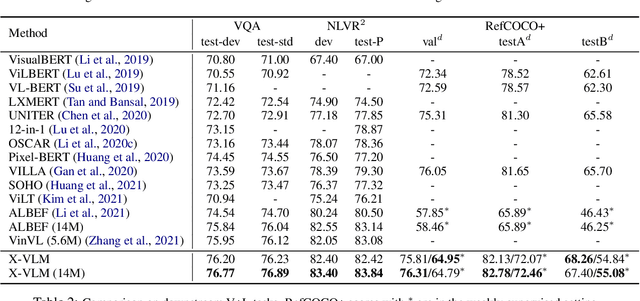
Most existing methods in vision language pre-training rely on object-centric features extracted through object detection, and make fine-grained alignments between the extracted features and texts. We argue that the use of object detection may not be suitable for vision language pre-training. Instead, we point out that the task should be performed so that the regions of `visual concepts' mentioned in the texts are located in the images, and in the meantime alignments between texts and visual concepts are identified, where the alignments are in multi-granularity. This paper proposes a new method called X-VLM to perform `multi-grained vision language pre-training'. Experimental results show that X-VLM consistently outperforms state-of-the-art methods in many downstream vision language tasks.
Active Testing: An Unbiased Evaluation Method for Distantly Supervised Relation Extraction
Oct 17, 2020
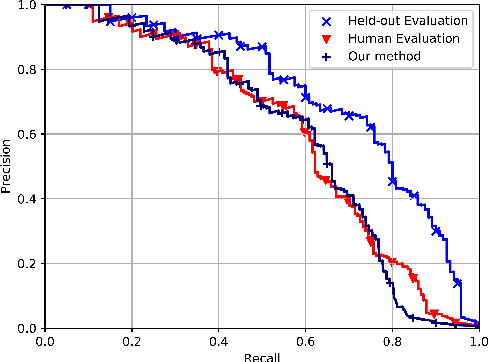
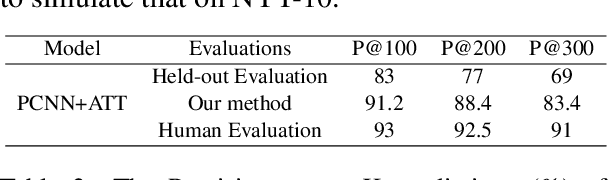
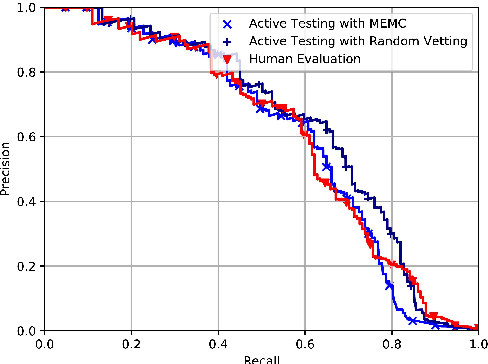
Distant supervision has been a widely used method for neural relation extraction for its convenience of automatically labeling datasets. However, existing works on distantly supervised relation extraction suffer from the low quality of test set, which leads to considerable biased performance evaluation. These biases not only result in unfair evaluations but also mislead the optimization of neural relation extraction. To mitigate this problem, we propose a novel evaluation method named active testing through utilizing both the noisy test set and a few manual annotations. Experiments on a widely used benchmark show that our proposed approach can yield approximately unbiased evaluations for distantly supervised relation extractors.