 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX$^2$-VLM: All-In-One Pre-trained Model For Vision-Language Tasks
Paper and Code
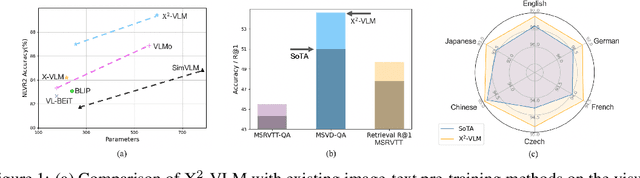
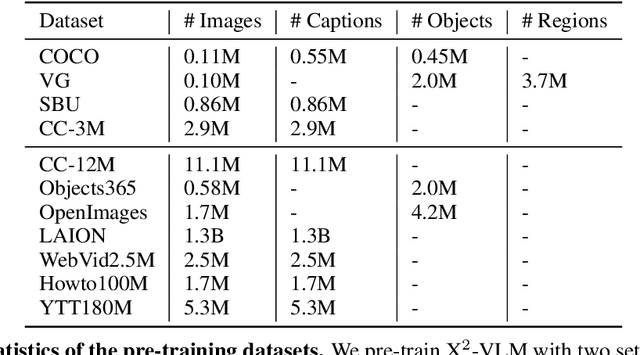
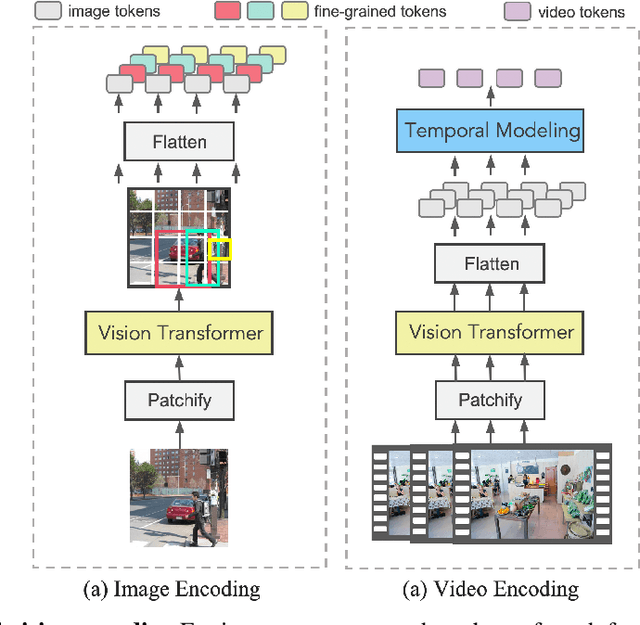

Vision language pre-training aims to learn alignments between vision and language from a large amount of data. We proposed multi-grained vision language pre-training, a unified approach which can learn vision language alignments in multiple granularity. This paper advances the proposed method by unifying image and video encoding in one model and scaling up the model with large-scale data. We present X$^2$-VLM, a pre-trained VLM with a modular architecture for both image-text tasks and video-text tasks. Experiment results show that X$^2$-VLM performs the best on base and large scale for both image-text and video-text tasks, making a good trade-off between performance and model scale. Moreover, we show that the modular design of X$^2$-VLM results in high transferability for X$^2$-VLM to be utilized in any language or domain. For example, by simply replacing the text encoder with XLM-R, X$^2$-VLM outperforms state-of-the-art multilingual multi-modal pre-trained models without any multilingual pre-training. The code and pre-trained models will be available at github.com/zengyan-97/X2-VLM.