 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefix Language Models are Unified Modal Learners
Paper and Code
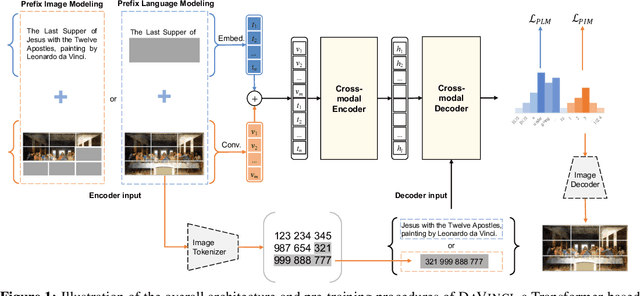
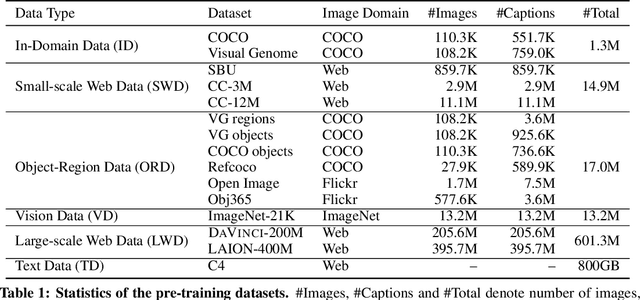
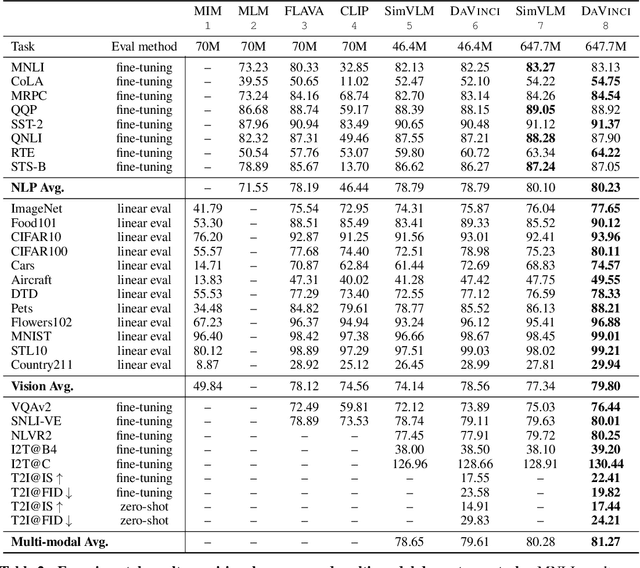

With the success of vision-language pre-training, we have witnessed the state-of-the-art has been pushed on multi-modal understanding and generation. However, the current pre-training paradigm is either incapable of targeting all modalities at once (e.g., text generation and image generation), or requires multi-fold well-designed tasks which significantly limits the scalability. We demonstrate that a unified modal model could be learned with a prefix language modeling objective upon text and image sequences. Thanks to the simple but powerful pre-training paradigm, our proposed model, DaVinci, is simple to train, scalable to huge data, and adaptable to a variety of downstream tasks across modalities (language / vision / vision+language), types (understanding / generation) and settings (e.g., zero-shot, fine-tuning, linear evaluation) with a single unified architecture. DaVinci achieves the competitive performance on a wide range of 26 understanding / generation tasks, and outperforms previous unified vision-language models on most tasks, including ImageNet classification (+1.6%), VQAv2 (+1.4%), COCO caption generation (BLEU@4 +1.1%, CIDEr +1.5%) and COCO image generation (IS +0.9%, FID -1.0%), at the comparable model and data scale. Furthermore, we offer a well-defined benchmark for future research by reporting the performance on different scales of the pre-training dataset on a heterogeneous and wide distribution coverage. Our results establish new, stronger baselines for future comparisons at different data scales and shed light on the difficulties of comparing VLP models more generally.