 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts
Paper and Code
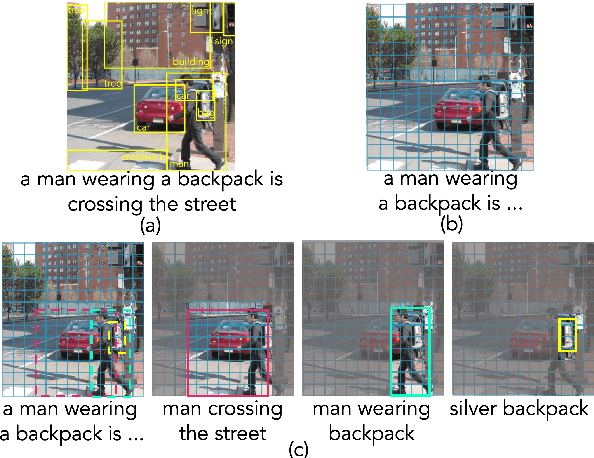
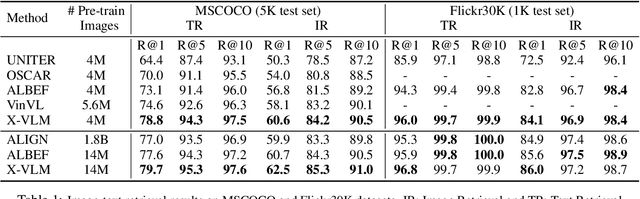
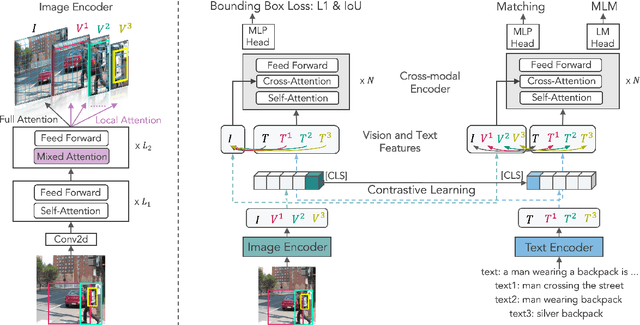
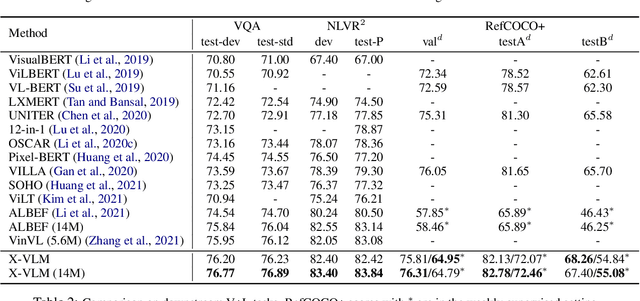
Most existing methods in vision language pre-training rely on object-centric features extracted through object detection, and make fine-grained alignments between the extracted features and texts. We argue that the use of object detection may not be suitable for vision language pre-training. Instead, we point out that the task should be performed so that the regions of `visual concepts' mentioned in the texts are located in the images, and in the meantime alignments between texts and visual concepts are identified, where the alignments are in multi-granularity. This paper proposes a new method called X-VLM to perform `multi-grained vision language pre-training'. Experimental results show that X-VLM consistently outperforms state-of-the-art methods in many downstream vision language tasks.