 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRRG-CLIP: Automatic Generation of Chest Radiology Reports and Classification of Chest Radiographs
Dec 31, 2024



The complexity of stacked imaging and the massive number of radiographs make writing radiology reports complex and inefficient. Even highly experienced radiologists struggle to maintain accuracy and consistency in interpreting radiographs under prolonged high-intensity work. To address these issues, this work proposes the CRRG-CLIP Model (Chest Radiology Report Generation and Radiograph Classification Model), an end-to-end model for automated report generation and radiograph classification. The model consists of two modules: the radiology report generation module and the radiograph classification module. The generation module uses Faster R-CNN to identify anatomical regions in radiographs, a binary classifier to select key regions, and GPT-2 to generate semantically coherent reports. The classification module uses the unsupervised Contrastive Language Image Pretraining (CLIP) model, addressing the challenges of high-cost labelled datasets and insufficient features. The results show that the generation module performs comparably to high-performance baseline models on BLEU, METEOR, and ROUGE-L metrics, and outperformed the GPT-4o model on BLEU-2, BLEU-3, BLEU-4, and ROUGE-L metrics. The classification module significantly surpasses the state-of-the-art model in AUC and Accuracy. This demonstrates that the proposed model achieves high accuracy, readability, and fluency in report generation, while multimodal contrastive training with unlabelled radiograph-report pairs enhances classification performance.
Advances in Machine Learning Research Using Knowledge Graphs
Dec 23, 2024The study uses CSSCI-indexed literature from the China National Knowledge Infrastructure (CNKI) database as the data source. It utilizes the CiteSpace visualization software to draw knowledge graphs on aspects such as institutional collaboration and keyword co-occurrence. This analysis provides insights into the current state of research and emerging trends in the field of machine learning in China. Additionally, it identifies the challenges faced in the field of machine learning research and offers suggestions that could serve as valuable references for future research.
A Fusion Approach of Dependency Syntax and Sentiment Polarity for Feature Label Extraction in Commodity Reviews
Dec 20, 2024
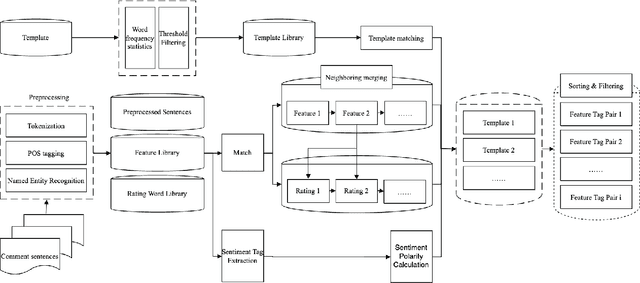
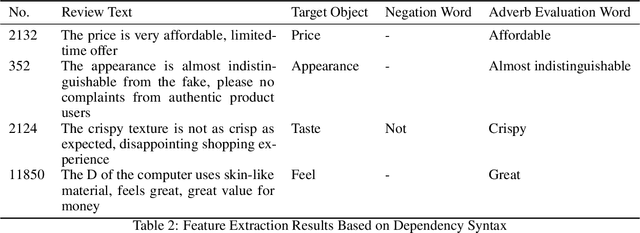
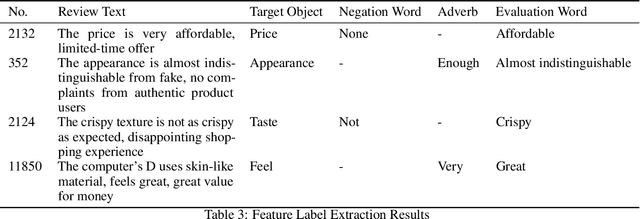
This study analyzes 13,218 product reviews from JD.com, covering four categories: mobile phones, computers, cosmetics, and food. A novel method for feature label extraction is proposed by integrating dependency parsing and sentiment polarity analysis. The proposed method addresses the challenges of low robustness in existing extraction algorithms and significantly enhances extraction accuracy. Experimental results show that the method achieves an accuracy of 0.7, with recall and F-score both stabilizing at 0.8, demonstrating its effectiveness. However, challenges such as dependence on matching dictionaries and the limited scope of extracted feature tags require further investigation in future research.