 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Distillation-based Hybrid Federated Learning on Non-IID Data
Sep 26, 2024In federated learning, the heterogeneity of client data has a great impact on the performance of model training. Many heterogeneity issues in this process are raised by non-independently and identically distributed (Non-IID) data. This study focuses on the issue of label distribution skew. To address it, we propose a hybrid federated learning framework called HFLDD, which integrates dataset distillation to generate approximately independent and equally distributed (IID) data, thereby improving the performance of model training. Particularly, we partition the clients into heterogeneous clusters, where the data labels among different clients within a cluster are unbalanced while the data labels among different clusters are balanced. The cluster headers collect distilled data from the corresponding cluster members, and conduct model training in collaboration with the server. This training process is like traditional federated learning on IID data, and hence effectively alleviates the impact of Non-IID data on model training. Furthermore, we compare our proposed method with typical baseline methods on public datasets. Experimental results demonstrate that when the data labels are severely imbalanced, the proposed HFLDD outperforms the baseline methods in terms of both test accuracy and communication cost.
Reconstructing Sparse Illicit Supply Networks: A Case Study of Multiplex Drug Trafficking Networks
Jul 29, 2022

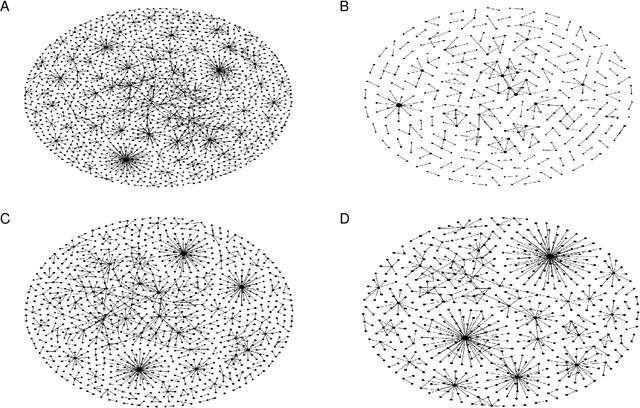

The network structure provides critical information for law enforcement agencies to develop effective strategies to interdict illicit supply networks. However, the complete structure of covert networks is often unavailable, thus it is crucially important to develop approaches to infer a more complete structure of covert networks. In this paper, we work on real-world multiplex drug trafficking networks extracted from an investigation report. A statistical approach built on the EM algorithm (DegEM) as well as other methods based on structural similarity are applied to reconstruct the multiplex drug trafficking network given different fractions of observed nodes and links. It is found that DegEM approach achieves the best predictive performance in terms of several accuracy metrics. Meanwhile, structural similarity-based methods perform poorly in reconstructing the drug trafficking networks due to the sparsity of links between nodes in the network. The inferred multiplex networks can be leveraged to (i) inform the decision-making on monitoring covert networks as well as allocating limited resources for collecting additional information to improve the reconstruction accuracy and (ii) develop more effective interdiction strategies.