 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntermediate Representations are Strong AI-Generated Image Detectors
May 05, 2026The rapid advancement in generative AI models has enabled the creation of photorealistic images. At the same time, there are growing concerns about the potential misuse and dangers of generated content, as well as a pressing need for effective AI-generated image detectors. However, current training-based detection techniques are typically computationally costly and can hardly be generalized to unseen data domains, while training-free methods fall short in detection performance. To bridge this gap, we propose a search-based method employing data embedding sensitivity in intermediate layers to detect AI-generated images. Given a set of real and AI-generated images, our method examines the similarity between original image embeddings and perturbed image embeddings, and detects AI-generated images based on the similarity. We examine the proposed method on two comprehensive benchmarks: GenImage and Forensics Small. Our method exhibits improved performance across different datasets compared to both training-free and training-based state-of-the-art methods. On average, our method achieves the largest performance gain on the Forensics Small benchmark by 39.61% compared to the best training-free method and 5.14% compared to the best training-based method in AUROC score.
Improving Robustness of Tabular Retrieval via Representational Stability
Apr 28, 2026Transformer-based table retrieval systems flatten structured tables into token sequences, making retrieval sensitive to the choice of serialization even when table semantics remain unchanged. We show that semantically equivalent serializations, such as $\texttt{csv}$, $\texttt{tsv}$, $\texttt{html}$, $\texttt{markdown}$, and $\texttt{ddl}$, can produce substantially different embeddings and retrieval results across multiple benchmarks and retriever families. To address this instability, we treat serialization embedding as noisy views of a shared semantic signal and use its centroid as a canonical target representation. We show that centroid averaging suppresses format-specific variation and can recover the semantic content common to different serializations when format-induced shifts differ across tables. Empirically, centroid representations outrank individual formats in aggregate pairwise comparisons across $\texttt{MPNet}$, $\texttt{BGE-M3}$, $\texttt{ReasonIR}$, and $\texttt{SPLADE}$. We further introduce a lightweight residual bottleneck adapter on top of a frozen encoder that maps single-serialization embeddings towards centroid targets while preserving variance and enforcing covariance regularization. The adapter improves robustness for several dense retrievers, though gains are model-dependent and weaker for sparse lexical retrieval. These results identify serialization sensitivity as a major source of retrieval variance and show the promise of post hoc geometric correction for serialization-invariant table retrieval.
From Static Templates to Dynamic Runtime Graphs: A Survey of Workflow Optimization for LLM Agents
Mar 23, 2026Large language model (LLM)-based systems are becoming increasingly popular for solving tasks by constructing executable workflows that interleave LLM calls, information retrieval, tool use, code execution, memory updates, and verification. This survey reviews recent methods for designing and optimizing such workflows, which we treat as agentic computation graphs (ACGs). We organize the literature based on when workflow structure is determined, where structure refers to which components or agents are present, how they depend on each other, and how information flows between them. This lens distinguishes static methods, which fix a reusable workflow scaffold before deployment, from dynamic methods, which select, generate, or revise the workflow for a particular run before or during execution. We further organize prior work along three dimensions: when structure is determined, what part of the workflow is optimized, and which evaluation signals guide optimization (e.g., task metrics, verifier signals, preferences, or trace-derived feedback). We also distinguish reusable workflow templates, run-specific realized graphs, and execution traces, separating reusable design choices from the structures actually deployed in a given run and from realized runtime behavior. Finally, we outline a structure-aware evaluation perspective that complements downstream task metrics with graph-level properties, execution cost, robustness, and structural variation across inputs. Our goal is to provide a clear vocabulary, a unified framework for positioning new methods, a more comparable view of existing body of literature, and a more reproducible evaluation standard for future work in workflow optimizations for LLM agents.
Unraveling the cognitive patterns of Large Language Models through module communities
Aug 25, 2025Large Language Models (LLMs) have reshaped our world with significant advancements in science, engineering, and society through applications ranging from scientific discoveries and medical diagnostics to Chatbots. Despite their ubiquity and utility, the underlying mechanisms of LLM remain concealed within billions of parameters and complex structures, making their inner architecture and cognitive processes challenging to comprehend. We address this gap by adopting approaches to understanding emerging cognition in biology and developing a network-based framework that links cognitive skills, LLM architectures, and datasets, ushering in a paradigm shift in foundation model analysis. The skill distribution in the module communities demonstrates that while LLMs do not strictly parallel the focalized specialization observed in specific biological systems, they exhibit unique communities of modules whose emergent skill patterns partially mirror the distributed yet interconnected cognitive organization seen in avian and small mammalian brains. Our numerical results highlight a key divergence from biological systems to LLMs, where skill acquisition benefits substantially from dynamic, cross-regional interactions and neural plasticity. By integrating cognitive science principles with machine learning, our framework provides new insights into LLM interpretability and suggests that effective fine-tuning strategies should leverage distributed learning dynamics rather than rigid modular interventions.
Gradient Flow Matching for Learning Update Dynamics in Neural Network Training
May 26, 2025
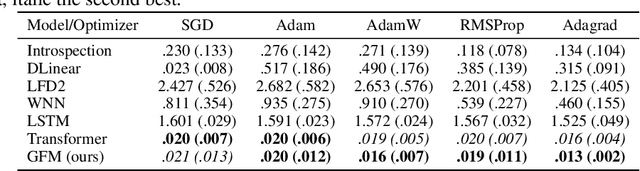

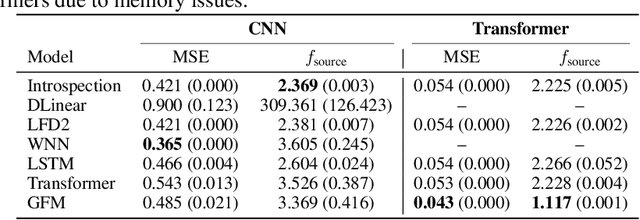
Training deep neural networks remains computationally intensive due to the itera2 tive nature of gradient-based optimization. We propose Gradient Flow Matching (GFM), a continuous-time modeling framework that treats neural network training as a dynamical system governed by learned optimizer-aware vector fields. By leveraging conditional flow matching, GFM captures the underlying update rules of optimizers such as SGD, Adam, and RMSprop, enabling smooth extrapolation of weight trajectories toward convergence. Unlike black-box sequence models, GFM incorporates structural knowledge of gradient-based updates into the learning objective, facilitating accurate forecasting of final weights from partial training sequences. Empirically, GFM achieves forecasting accuracy that is competitive with Transformer-based models and significantly outperforms LSTM and other classical baselines. Furthermore, GFM generalizes across neural architectures and initializations, providing a unified framework for studying optimization dynamics and accelerating convergence prediction.
CRAFT: Training-Free Cascaded Retrieval for Tabular QA
May 21, 2025



Table Question Answering (TQA) involves retrieving relevant tables from a large corpus to answer natural language queries. Traditional dense retrieval models, such as DTR and ColBERT, not only incur high computational costs for large-scale retrieval tasks but also require retraining or fine-tuning on new datasets, limiting their adaptability to evolving domains and knowledge. In this work, we propose $\textbf{CRAFT}$, a cascaded retrieval approach that first uses a sparse retrieval model to filter a subset of candidate tables before applying more computationally expensive dense models and neural re-rankers. Our approach achieves better retrieval performance than state-of-the-art (SOTA) sparse, dense, and hybrid retrievers. We further enhance table representations by generating table descriptions and titles using Gemini Flash 1.5. End-to-end TQA results using various Large Language Models (LLMs) on NQ-Tables, a subset of the Natural Questions Dataset, demonstrate $\textbf{CRAFT}$ effectiveness.
Less is More: Efficient Weight Farcasting with 1-Layer Neural Network
May 05, 2025Addressing the computational challenges inherent in training large-scale deep neural networks remains a critical endeavor in contemporary machine learning research. While previous efforts have focused on enhancing training efficiency through techniques such as gradient descent with momentum, learning rate scheduling, and weight regularization, the demand for further innovation continues to burgeon as model sizes keep expanding. In this study, we introduce a novel framework which diverges from conventional approaches by leveraging long-term time series forecasting techniques. Our method capitalizes solely on initial and final weight values, offering a streamlined alternative for complex model architectures. We also introduce a novel regularizer that is tailored to enhance the forecasting performance of our approach. Empirical evaluations conducted on synthetic weight sequences and real-world deep learning architectures, including the prominent large language model DistilBERT, demonstrate the superiority of our method in terms of forecasting accuracy and computational efficiency. Notably, our framework showcases improved performance while requiring minimal additional computational overhead, thus presenting a promising avenue for accelerating the training process across diverse tasks and architectures.
Forecasting Open-Weight AI Model Growth on Hugging Face
Feb 21, 2025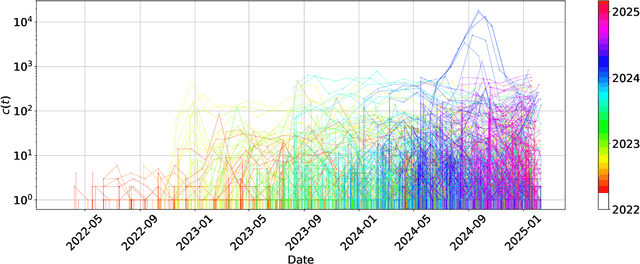

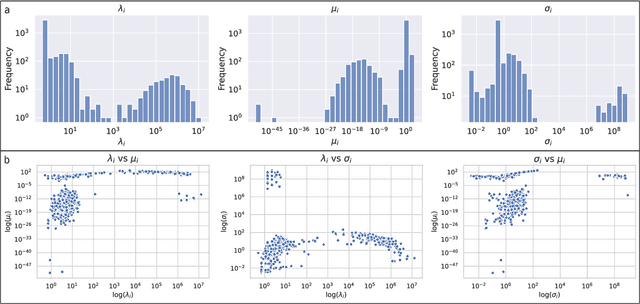
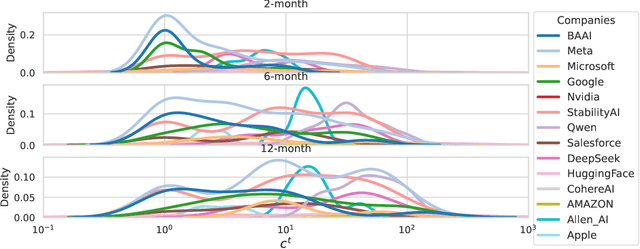
As the open-weight AI landscape continues to proliferate-with model development, significant investment, and user interest-it becomes increasingly important to predict which models will ultimately drive innovation and shape AI ecosystems. Building on parallels with citation dynamics in scientific literature, we propose a framework to quantify how an open-weight model's influence evolves. Specifically, we adapt the model introduced by Wang et al. for scientific citations, using three key parameters-immediacy, longevity, and relative fitness-to track the cumulative number of fine-tuned models of an open-weight model. Our findings reveal that this citation-style approach can effectively capture the diverse trajectories of open-weight model adoption, with most models fitting well and outliers indicating unique patterns or abrupt jumps in usage.
Modular Prompt Learning Improves Vision-Language Models
Feb 19, 2025Pre-trained vision-language models are able to interpret visual concepts and language semantics. Prompt learning, a method of constructing prompts for text encoders or image encoders, elicits the potentials of pre-trained models and readily adapts them to new scenarios. Compared to fine-tuning, prompt learning enables the model to achieve comparable or better performance using fewer trainable parameters. Besides, prompt learning freezes the pre-trained model and avoids the catastrophic forgetting issue in the fine-tuning. Continuous prompts inserted into the input of every transformer layer (i.e. deep prompts) can improve the performances of pre-trained models on downstream tasks. For i-th transformer layer, the inserted prompts replace previously inserted prompts in the $(i-1)$-th layer. Although the self-attention mechanism contextualizes newly inserted prompts for the current layer and embeddings from the previous layer's output, removing all inserted prompts from the previous layer inevitably loses information contained in the continuous prompts. In this work, we propose Modular Prompt Learning (MPL) that is designed to promote the preservation of information contained in the inserted prompts. We evaluate the proposed method on base-to-new generalization and cross-dataset tasks. On average of 11 datasets, our method achieves 0.7% performance gain on the base-to-new generalization task compared to the state-of-the-art method. The largest improvement on the individual dataset is 10.7% (EuroSAT dataset).
Inferring from Logits: Exploring Best Practices for Decoding-Free Generative Candidate Selection
Jan 28, 2025



Generative Language Models rely on autoregressive decoding to produce the output sequence token by token. Many tasks such as preference optimization, require the model to produce task-level output consisting of multiple tokens directly by selecting candidates from a pool as predictions. Determining a task-level prediction from candidates using the ordinary token-level decoding mechanism is constrained by time-consuming decoding and interrupted gradients by discrete token selection. Existing works have been using decoding-free candidate selection methods to obtain candidate probability from initial output logits over vocabulary. Though these estimation methods are widely used, they are not systematically evaluated, especially on end tasks. We introduce an evaluation of a comprehensive collection of decoding-free candidate selection approaches on a comprehensive set of tasks, including five multiple-choice QA tasks with a small candidate pool and four clinical decision tasks with a massive amount of candidates, some with 10k+ options. We evaluate the estimation methods paired with a wide spectrum of foundation LMs covering different architectures, sizes and training paradigms. The results and insights from our analysis inform the future model design.