 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBypassing Prompt Injection and Jailbreak Detection in LLM Guardrails
Apr 16, 2025Large Language Models (LLMs) guardrail systems are designed to protect against prompt injection and jailbreak attacks. However, they remain vulnerable to evasion techniques. We demonstrate two approaches for bypassing LLM prompt injection and jailbreak detection systems via traditional character injection methods and algorithmic Adversarial Machine Learning (AML) evasion techniques. Through testing against six prominent protection systems, including Microsoft's Azure Prompt Shield and Meta's Prompt Guard, we show that both methods can be used to evade detection while maintaining adversarial utility achieving in some instances up to 100% evasion success. Furthermore, we demonstrate that adversaries can enhance Attack Success Rates (ASR) against black-box targets by leveraging word importance ranking computed by offline white-box models. Our findings reveal vulnerabilities within current LLM protection mechanisms and highlight the need for more robust guardrail systems.
EDoRA: Efficient Weight-Decomposed Low-Rank Adaptation via Singular Value Decomposition
Jan 21, 2025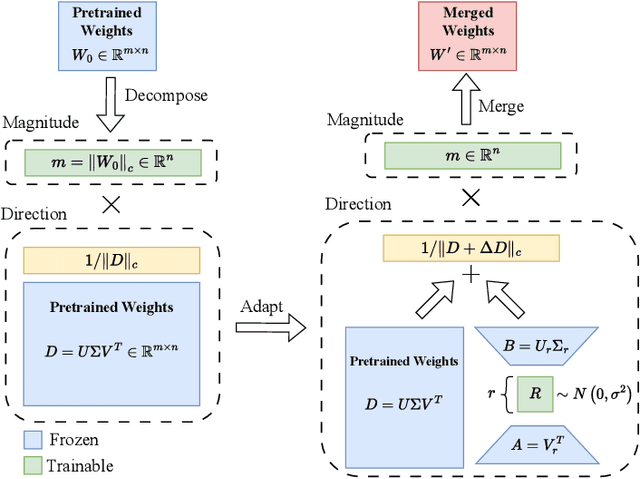
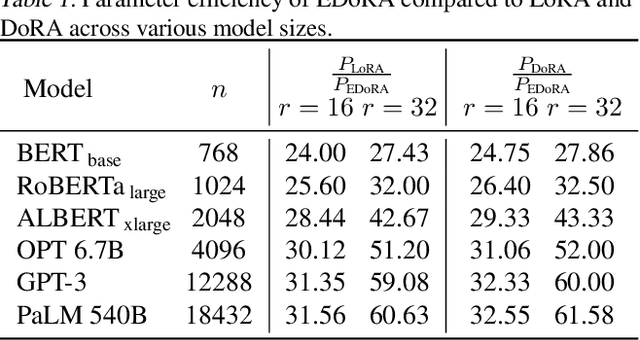
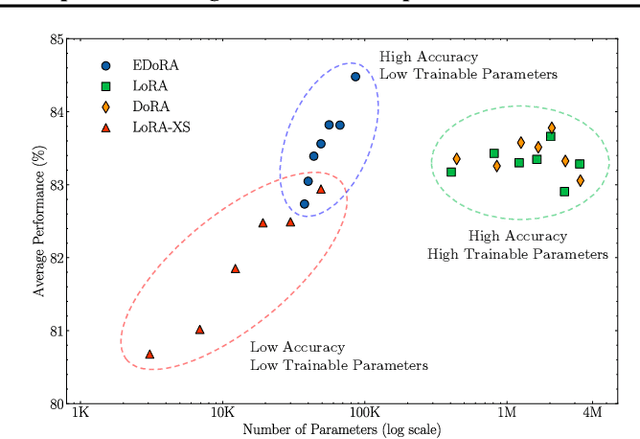
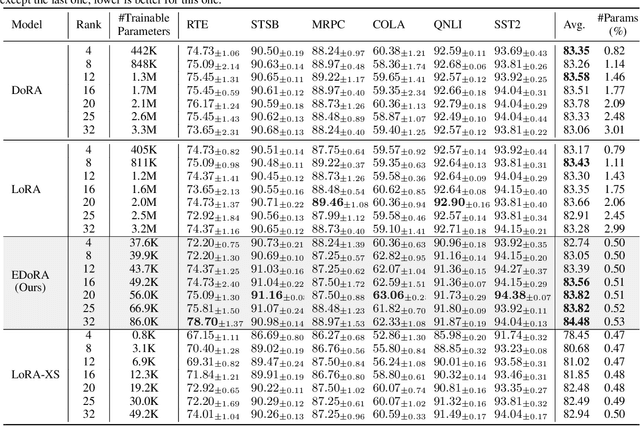
Parameter-efficient fine-tuning methods, such as LoRA, reduces the number of trainable parameters. However, they often suffer from scalability issues and differences between their learning pattern and full fine-tuning. To overcome these limitations, we propose Efficient Weight-Decomposed Low-Rank Adaptation (EDoRA): a novel PEFT method that decomposes pre-trained weights into magnitude and directional components. By freezing low-rank matrices, initializing them by singular value decomposition, and introducing a small trainable matrix between them, EDoRA achieves substantial reduction in trainable parameters while maintaining learning capacity. Experimental results on the GLUE benchmark demonstrate that EDoRA achieves competitive or superior performance compared to state-of-the-art methods, such as LoRA and DoRA, with up to 30x fewer trainable parameters. This makes EDoRA a highly efficient solution for adapting LLMs to diverse tasks under memory-constrained settings. Code is available at https://github.com/Hamid-Nasiri/EDoRA .
Compilation as a Defense: Enhancing DL Model Attack Robustness via Tensor Optimization
Sep 20, 2023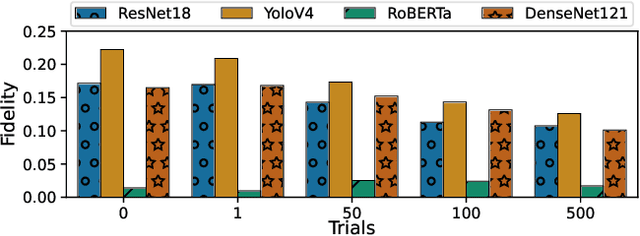
Adversarial Machine Learning (AML) is a rapidly growing field of security research, with an often overlooked area being model attacks through side-channels. Previous works show such attacks to be serious threats, though little progress has been made on efficient remediation strategies that avoid costly model re-engineering. This work demonstrates a new defense against AML side-channel attacks using model compilation techniques, namely tensor optimization. We show relative model attack effectiveness decreases of up to 43% using tensor optimization, discuss the implications, and direction of future work.
Model Leeching: An Extraction Attack Targeting LLMs
Sep 19, 2023Model Leeching is a novel extraction attack targeting Large Language Models (LLMs), capable of distilling task-specific knowledge from a target LLM into a reduced parameter model. We demonstrate the effectiveness of our attack by extracting task capability from ChatGPT-3.5-Turbo, achieving 73% Exact Match (EM) similarity, and SQuAD EM and F1 accuracy scores of 75% and 87%, respectively for only $50 in API cost. We further demonstrate the feasibility of adversarial attack transferability from an extracted model extracted via Model Leeching to perform ML attack staging against a target LLM, resulting in an 11% increase to attack success rate when applied to ChatGPT-3.5-Turbo.
PINCH: An Adversarial Extraction Attack Framework for Deep Learning Models
Sep 13, 2022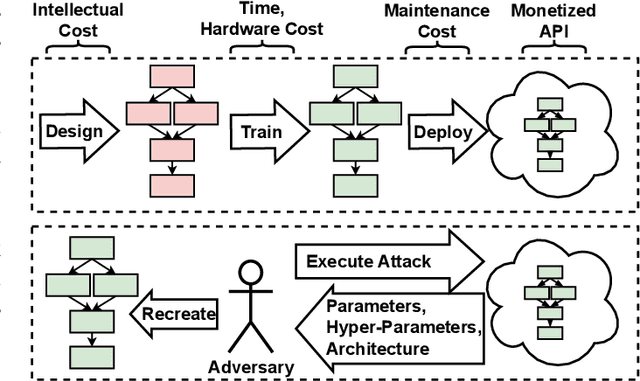

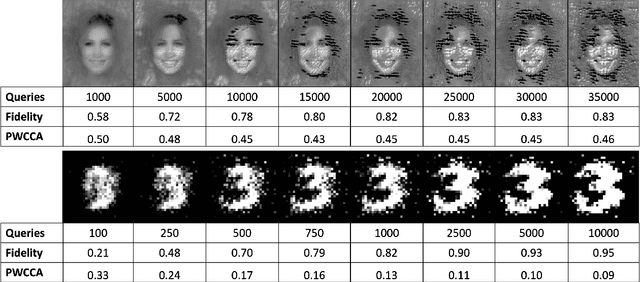
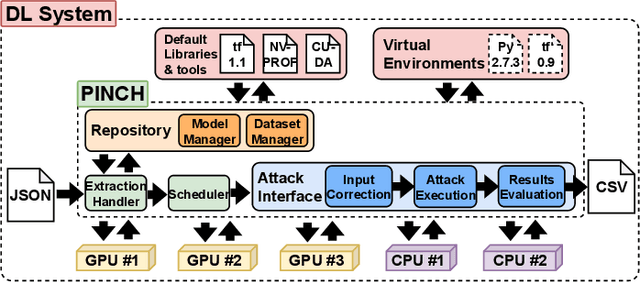
Deep Learning (DL) models increasingly power a diversity of applications. Unfortunately, this pervasiveness also makes them attractive targets for extraction attacks which can steal the architecture, parameters, and hyper-parameters of a targeted DL model. Existing extraction attack studies have observed varying levels of attack success for different DL models and datasets, yet the underlying cause(s) behind their susceptibility often remain unclear. Ascertaining such root-cause weaknesses would help facilitate secure DL systems, though this requires studying extraction attacks in a wide variety of scenarios to identify commonalities across attack success and DL characteristics. The overwhelmingly high technical effort and time required to understand, implement, and evaluate even a single attack makes it infeasible to explore the large number of unique extraction attack scenarios in existence, with current frameworks typically designed to only operate for specific attack types, datasets and hardware platforms. In this paper we present PINCH: an efficient and automated extraction attack framework capable of deploying and evaluating multiple DL models and attacks across heterogeneous hardware platforms. We demonstrate the effectiveness of PINCH by empirically evaluating a large number of previously unexplored extraction attack scenarios, as well as secondary attack staging. Our key findings show that 1) multiple characteristics affect extraction attack success spanning DL model architecture, dataset complexity, hardware, attack type, and 2) partially successful extraction attacks significantly enhance the success of further adversarial attack staging.
HUNTER: AI based Holistic Resource Management for Sustainable Cloud Computing
Oct 28, 2021
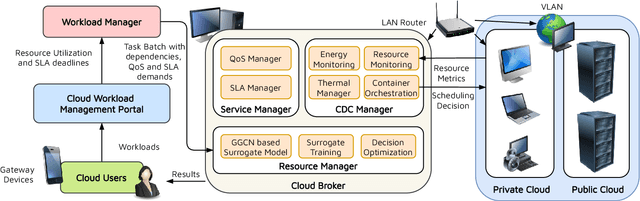
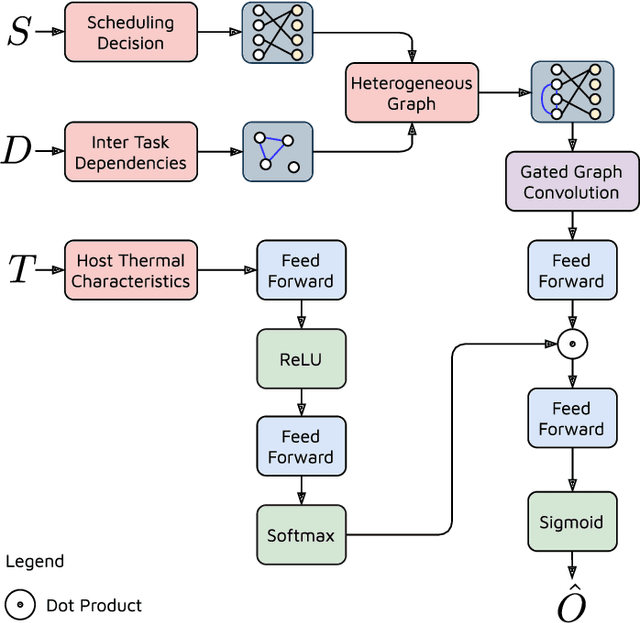
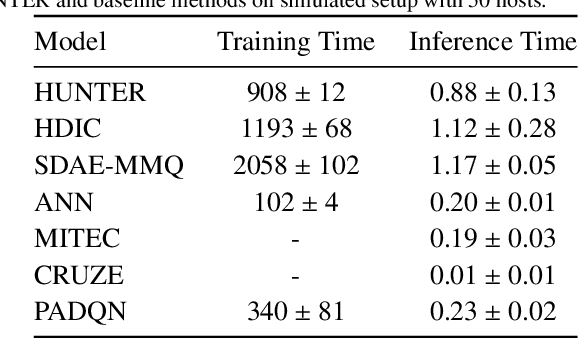
The worldwide adoption of cloud data centers (CDCs) has given rise to the ubiquitous demand for hosting application services on the cloud. Further, contemporary data-intensive industries have seen a sharp upsurge in the resource requirements of modern applications. This has led to the provisioning of an increased number of cloud servers, giving rise to higher energy consumption and, consequently, sustainability concerns. Traditional heuristics and reinforcement learning based algorithms for energy-efficient cloud resource management address the scalability and adaptability related challenges to a limited extent. Existing work often fails to capture dependencies across thermal characteristics of hosts, resource consumption of tasks and the corresponding scheduling decisions. This leads to poor scalability and an increase in the compute resource requirements, particularly in environments with non-stationary resource demands. To address these limitations, we propose an artificial intelligence (AI) based holistic resource management technique for sustainable cloud computing called HUNTER. The proposed model formulates the goal of optimizing energy efficiency in data centers as a multi-objective scheduling problem, considering three important models: energy, thermal and cooling. HUNTER utilizes a Gated Graph Convolution Network as a surrogate model for approximating the Quality of Service (QoS) for a system state and generating optimal scheduling decisions. Experiments on simulated and physical cloud environments using the CloudSim toolkit and the COSCO framework show that HUNTER outperforms state-of-the-art baselines in terms of energy consumption, SLA violation, scheduling time, cost and temperature by up to 12, 35, 43, 54 and 3 percent respectively.