 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePINCH: An Adversarial Extraction Attack Framework for Deep Learning Models
Paper and Code
Sep 13, 2022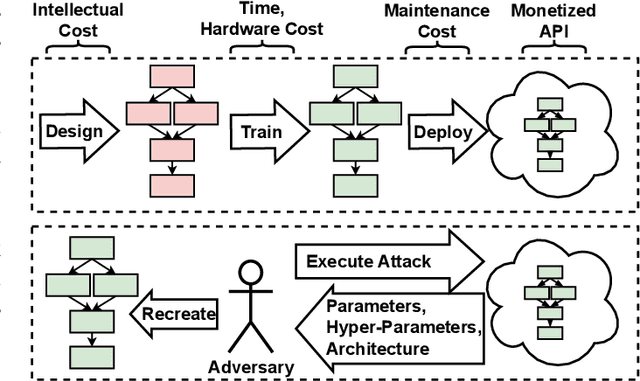

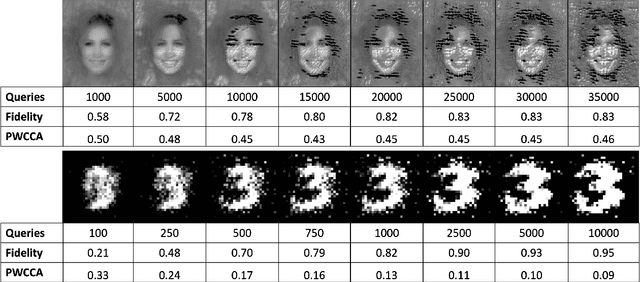
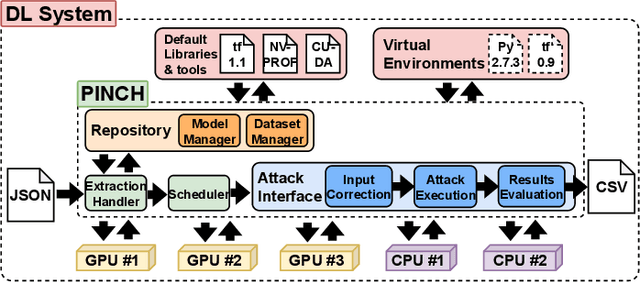
Deep Learning (DL) models increasingly power a diversity of applications. Unfortunately, this pervasiveness also makes them attractive targets for extraction attacks which can steal the architecture, parameters, and hyper-parameters of a targeted DL model. Existing extraction attack studies have observed varying levels of attack success for different DL models and datasets, yet the underlying cause(s) behind their susceptibility often remain unclear. Ascertaining such root-cause weaknesses would help facilitate secure DL systems, though this requires studying extraction attacks in a wide variety of scenarios to identify commonalities across attack success and DL characteristics. The overwhelmingly high technical effort and time required to understand, implement, and evaluate even a single attack makes it infeasible to explore the large number of unique extraction attack scenarios in existence, with current frameworks typically designed to only operate for specific attack types, datasets and hardware platforms. In this paper we present PINCH: an efficient and automated extraction attack framework capable of deploying and evaluating multiple DL models and attacks across heterogeneous hardware platforms. We demonstrate the effectiveness of PINCH by empirically evaluating a large number of previously unexplored extraction attack scenarios, as well as secondary attack staging. Our key findings show that 1) multiple characteristics affect extraction attack success spanning DL model architecture, dataset complexity, hardware, attack type, and 2) partially successful extraction attacks significantly enhance the success of further adversarial attack staging.