 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBypassing Prompt Injection and Jailbreak Detection in LLM Guardrails
Apr 16, 2025Large Language Models (LLMs) guardrail systems are designed to protect against prompt injection and jailbreak attacks. However, they remain vulnerable to evasion techniques. We demonstrate two approaches for bypassing LLM prompt injection and jailbreak detection systems via traditional character injection methods and algorithmic Adversarial Machine Learning (AML) evasion techniques. Through testing against six prominent protection systems, including Microsoft's Azure Prompt Shield and Meta's Prompt Guard, we show that both methods can be used to evade detection while maintaining adversarial utility achieving in some instances up to 100% evasion success. Furthermore, we demonstrate that adversaries can enhance Attack Success Rates (ASR) against black-box targets by leveraging word importance ranking computed by offline white-box models. Our findings reveal vulnerabilities within current LLM protection mechanisms and highlight the need for more robust guardrail systems.
UNICAD: A Unified Approach for Attack Detection, Noise Reduction and Novel Class Identification
Jun 24, 2024



As the use of Deep Neural Networks (DNNs) becomes pervasive, their vulnerability to adversarial attacks and limitations in handling unseen classes poses significant challenges. The state-of-the-art offers discrete solutions aimed to tackle individual issues covering specific adversarial attack scenarios, classification or evolving learning. However, real-world systems need to be able to detect and recover from a wide range of adversarial attacks without sacrificing classification accuracy and to flexibly act in {\bf unseen} scenarios. In this paper, UNICAD, is proposed as a novel framework that integrates a variety of techniques to provide an adaptive solution. For the targeted image classification, UNICAD achieves accurate image classification, detects unseen classes, and recovers from adversarial attacks using Prototype and Similarity-based DNNs with denoising autoencoders. Our experiments performed on the CIFAR-10 dataset highlight UNICAD's effectiveness in adversarial mitigation and unseen class classification, outperforming traditional models.
Federated Adversarial Learning for Robust Autonomous Landing Runway Detection
Jun 22, 2024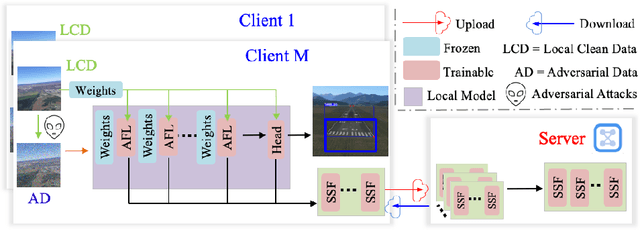
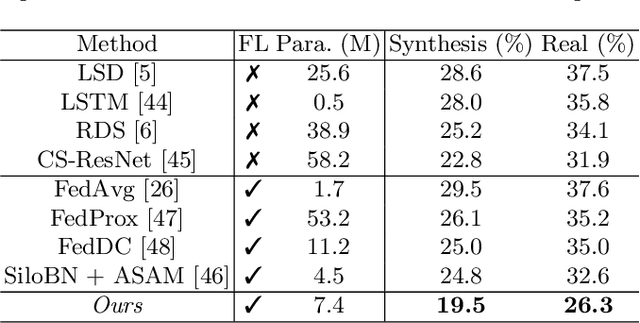
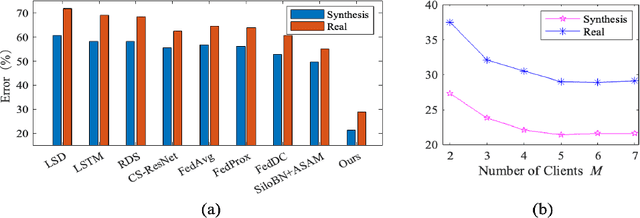
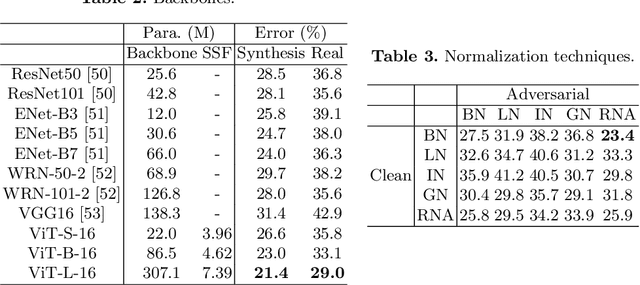
As the development of deep learning techniques in autonomous landing systems continues to grow, one of the major challenges is trust and security in the face of possible adversarial attacks. In this paper, we propose a federated adversarial learning-based framework to detect landing runways using paired data comprising of clean local data and its adversarial version. Firstly, the local model is pre-trained on a large-scale lane detection dataset. Then, instead of exploiting large instance-adaptive models, we resort to a parameter-efficient fine-tuning method known as scale and shift deep features (SSF), upon the pre-trained model. Secondly, in each SSF layer, distributions of clean local data and its adversarial version are disentangled for accurate statistics estimation. To the best of our knowledge, this marks the first instance of federated learning work that address the adversarial sample problem in landing runway detection. Our experimental evaluations over both synthesis and real images of Landing Approach Runway Detection (LARD) dataset consistently demonstrate good performance of the proposed federated adversarial learning and robust to adversarial attacks.
* ICANN2024
Compilation as a Defense: Enhancing DL Model Attack Robustness via Tensor Optimization
Sep 20, 2023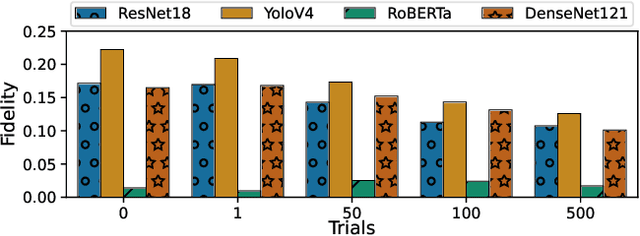
Adversarial Machine Learning (AML) is a rapidly growing field of security research, with an often overlooked area being model attacks through side-channels. Previous works show such attacks to be serious threats, though little progress has been made on efficient remediation strategies that avoid costly model re-engineering. This work demonstrates a new defense against AML side-channel attacks using model compilation techniques, namely tensor optimization. We show relative model attack effectiveness decreases of up to 43% using tensor optimization, discuss the implications, and direction of future work.
Model Leeching: An Extraction Attack Targeting LLMs
Sep 19, 2023Model Leeching is a novel extraction attack targeting Large Language Models (LLMs), capable of distilling task-specific knowledge from a target LLM into a reduced parameter model. We demonstrate the effectiveness of our attack by extracting task capability from ChatGPT-3.5-Turbo, achieving 73% Exact Match (EM) similarity, and SQuAD EM and F1 accuracy scores of 75% and 87%, respectively for only $50 in API cost. We further demonstrate the feasibility of adversarial attack transferability from an extracted model extracted via Model Leeching to perform ML attack staging against a target LLM, resulting in an 11% increase to attack success rate when applied to ChatGPT-3.5-Turbo.
Privacy-preserving Decentralized Federated Learning over Time-varying Communication Graph
Oct 01, 2022

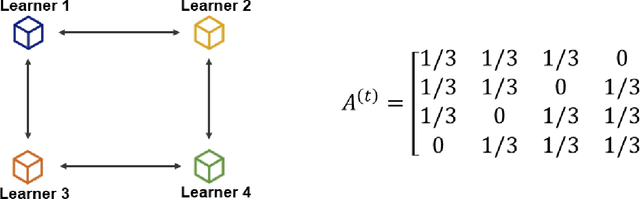
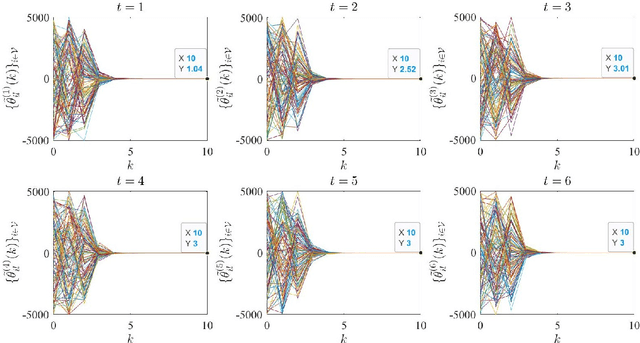
Establishing how a set of learners can provide privacy-preserving federated learning in a fully decentralized (peer-to-peer, no coordinator) manner is an open problem. We propose the first privacy-preserving consensus-based algorithm for the distributed learners to achieve decentralized global model aggregation in an environment of high mobility, where the communication graph between the learners may vary between successive rounds of model aggregation. In particular, in each round of global model aggregation, the Metropolis-Hastings method is applied to update the weighted adjacency matrix based on the current communication topology. In addition, the Shamir's secret sharing scheme is integrated to facilitate privacy in reaching consensus of the global model. The paper establishes the correctness and privacy properties of the proposed algorithm. The computational efficiency is evaluated by a simulation built on a federated learning framework with a real-word dataset.
PINCH: An Adversarial Extraction Attack Framework for Deep Learning Models
Sep 13, 2022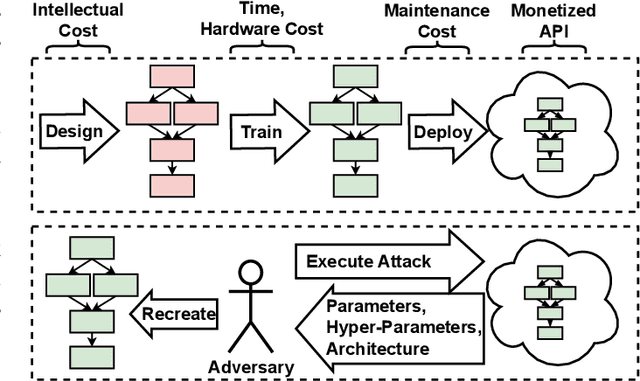

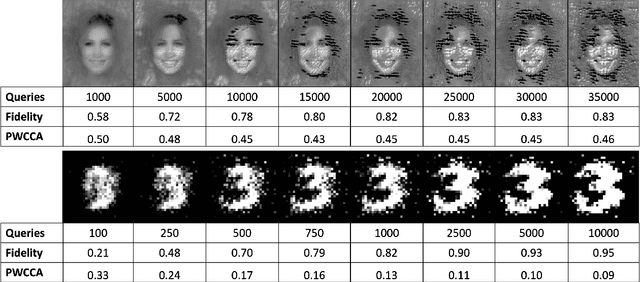
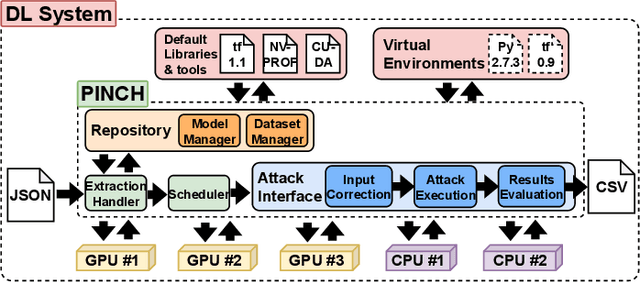
Deep Learning (DL) models increasingly power a diversity of applications. Unfortunately, this pervasiveness also makes them attractive targets for extraction attacks which can steal the architecture, parameters, and hyper-parameters of a targeted DL model. Existing extraction attack studies have observed varying levels of attack success for different DL models and datasets, yet the underlying cause(s) behind their susceptibility often remain unclear. Ascertaining such root-cause weaknesses would help facilitate secure DL systems, though this requires studying extraction attacks in a wide variety of scenarios to identify commonalities across attack success and DL characteristics. The overwhelmingly high technical effort and time required to understand, implement, and evaluate even a single attack makes it infeasible to explore the large number of unique extraction attack scenarios in existence, with current frameworks typically designed to only operate for specific attack types, datasets and hardware platforms. In this paper we present PINCH: an efficient and automated extraction attack framework capable of deploying and evaluating multiple DL models and attacks across heterogeneous hardware platforms. We demonstrate the effectiveness of PINCH by empirically evaluating a large number of previously unexplored extraction attack scenarios, as well as secondary attack staging. Our key findings show that 1) multiple characteristics affect extraction attack success spanning DL model architecture, dataset complexity, hardware, attack type, and 2) partially successful extraction attacks significantly enhance the success of further adversarial attack staging.