 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoMedX: Towards Explainable Multi-Modal Prototype Learning for Bone Health Classification
Sep 18, 2025Bone health studies are crucial in medical practice for the early detection and treatment of Osteopenia and Osteoporosis. Clinicians usually make a diagnosis based on densitometry (DEXA scans) and patient history. The applications of AI in this field are ongoing research. Most successful methods rely on deep learning models that use vision alone (DEXA/X-ray imagery) and focus on prediction accuracy, while explainability is often disregarded and left to post hoc assessments of input contributions. We propose ProtoMedX, a multi-modal model that uses both DEXA scans of the lumbar spine and patient records. ProtoMedX's prototype-based architecture is explainable by design, which is crucial for medical applications, especially in the context of the upcoming EU AI Act, as it allows explicit analysis of model decisions, including incorrect ones. ProtoMedX demonstrates state-of-the-art performance in bone health classification while also providing explanations that can be visually understood by clinicians. Using a dataset of 4,160 real NHS patients, the proposed ProtoMedX achieves 87.58% accuracy in vision-only tasks and 89.8% in its multi-modal variant, both surpassing existing published methods.
Prototype-Based Continual Learning with Label-free Replay Buffer and Cluster Preservation Loss
Apr 09, 2025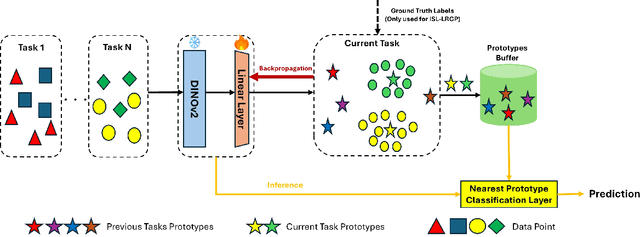
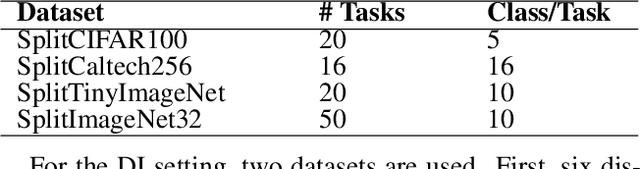
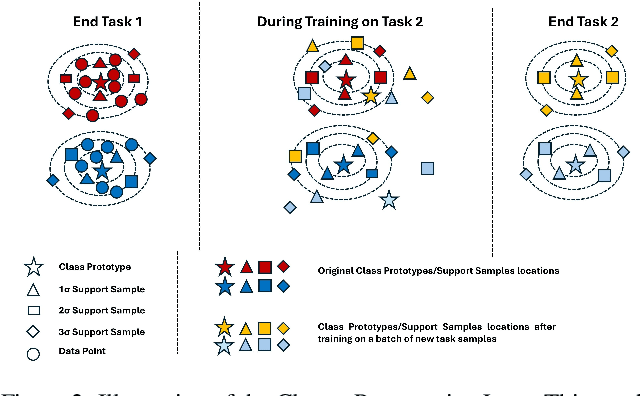
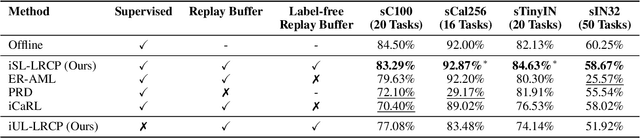
Continual learning techniques employ simple replay sample selection processes and use them during subsequent tasks. Typically, they rely on labeled data. In this paper, we depart from this by automatically selecting prototypes stored without labels, preserving cluster structures in the latent space across tasks. By eliminating label dependence in the replay buffer and introducing cluster preservation loss, it is demonstrated that the proposed method can maintain essential information from previously encountered tasks while ensuring adaptation to new tasks. "Push-away" and "pull-toward" mechanisms over previously learned prototypes are also introduced for class-incremental and domain-incremental scenarios. These mechanisms ensure the retention of previously learned information as well as adaptation to new classes or domain shifts. The proposed method is evaluated on several benchmarks, including SplitCIFAR100, SplitImageNet32, SplitTinyImageNet, and SplitCaltech256 for class-incremental, as well as R-MNIST and CORe50 for domain-incremental setting using pre-extracted DINOv2 features. Experimental results indicate that the label-free replay-based technique outperforms state-of-the-art continual learning methods and, in some cases, even surpasses offline learning. An unsupervised variant of the proposed technique for the class-incremental setting, avoiding labels use even on incoming data, also demonstrated competitive performance, outperforming particular supervised baselines in some cases. These findings underscore the effectiveness of the proposed framework in retaining prior information and facilitating continual adaptation.
COMIX: Compositional Explanations using Prototypes
Jan 10, 2025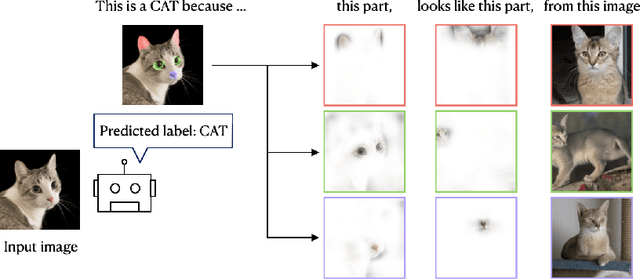

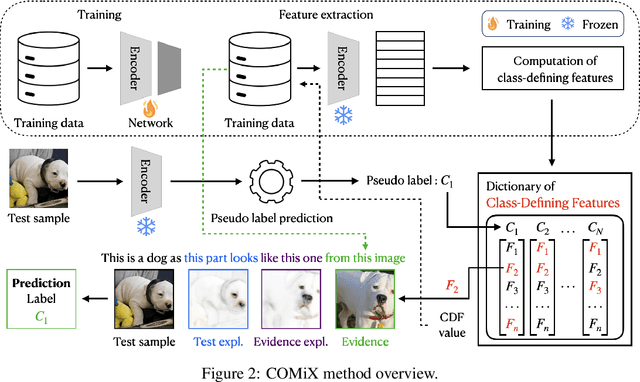
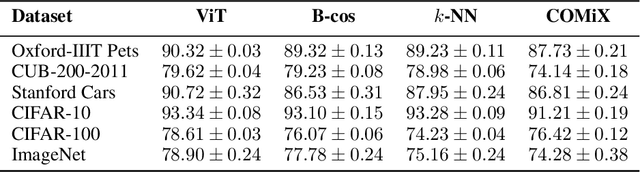
Aligning machine representations with human understanding is key to improving interpretability of machine learning (ML) models. When classifying a new image, humans often explain their decisions by decomposing the image into concepts and pointing to corresponding regions in familiar images. Current ML explanation techniques typically either trace decision-making processes to reference prototypes, generate attribution maps highlighting feature importance, or incorporate intermediate bottlenecks designed to align with human-interpretable concepts. The proposed method, named COMIX, classifies an image by decomposing it into regions based on learned concepts and tracing each region to corresponding ones in images from the training dataset, assuring that explanations fully represent the actual decision-making process. We dissect the test image into selected internal representations of a neural network to derive prototypical parts (primitives) and match them with the corresponding primitives derived from the training data. In a series of qualitative and quantitative experiments, we theoretically prove and demonstrate that our method, in contrast to post hoc analysis, provides fidelity of explanations and shows that the efficiency is competitive with other inherently interpretable architectures. Notably, it shows substantial improvements in fidelity and sparsity metrics, including 48.82% improvement in the C-insertion score on the ImageNet dataset over the best state-of-the-art baseline.
Complex-Cycle-Consistent Diffusion Model for Monaural Speech Enhancement
Dec 12, 2024



In this paper, we present a novel diffusion model-based monaural speech enhancement method. Our approach incorporates the separate estimation of speech spectra's magnitude and phase in two diffusion networks. Throughout the diffusion process, noise clips from real-world noise interferences are added gradually to the clean speech spectra and a noise-aware reverse process is proposed to learn how to generate both clean speech spectra and noise spectra. Furthermore, to fully leverage the intrinsic relationship between magnitude and phase, we introduce a complex-cycle-consistent (CCC) mechanism that uses the estimated magnitude to map the phase, and vice versa. We implement this algorithm within a phase-aware speech enhancement diffusion model (SEDM). We conduct extensive experiments on public datasets to demonstrate the effectiveness of our method, highlighting the significant benefits of exploiting the intrinsic relationship between phase and magnitude information to enhance speech. The comparison to conventional diffusion models demonstrates the superiority of SEDM.
UNICAD: A Unified Approach for Attack Detection, Noise Reduction and Novel Class Identification
Jun 24, 2024



As the use of Deep Neural Networks (DNNs) becomes pervasive, their vulnerability to adversarial attacks and limitations in handling unseen classes poses significant challenges. The state-of-the-art offers discrete solutions aimed to tackle individual issues covering specific adversarial attack scenarios, classification or evolving learning. However, real-world systems need to be able to detect and recover from a wide range of adversarial attacks without sacrificing classification accuracy and to flexibly act in {\bf unseen} scenarios. In this paper, UNICAD, is proposed as a novel framework that integrates a variety of techniques to provide an adaptive solution. For the targeted image classification, UNICAD achieves accurate image classification, detects unseen classes, and recovers from adversarial attacks using Prototype and Similarity-based DNNs with denoising autoencoders. Our experiments performed on the CIFAR-10 dataset highlight UNICAD's effectiveness in adversarial mitigation and unseen class classification, outperforming traditional models.
PUDD: Towards Robust Multi-modal Prototype-based Deepfake Detection
Jun 22, 2024



Deepfake techniques generate highly realistic data, making it challenging for humans to discern between actual and artificially generated images. Recent advancements in deep learning-based deepfake detection methods, particularly with diffusion models, have shown remarkable progress. However, there is a growing demand for real-world applications to detect unseen individuals, deepfake techniques, and scenarios. To address this limitation, we propose a Prototype-based Unified Framework for Deepfake Detection (PUDD). PUDD offers a detection system based on similarity, comparing input data against known prototypes for video classification and identifying potential deepfakes or previously unseen classes by analyzing drops in similarity. Our extensive experiments reveal three key findings: (1) PUDD achieves an accuracy of 95.1% on Celeb-DF, outperforming state-of-the-art deepfake detection methods; (2) PUDD leverages image classification as the upstream task during training, demonstrating promising performance in both image classification and deepfake detection tasks during inference; (3) PUDD requires only 2.7 seconds for retraining on new data and emits 10$^{5}$ times less carbon compared to the state-of-the-art model, making it significantly more environmentally friendly.
* CVPR2024
Federated Adversarial Learning for Robust Autonomous Landing Runway Detection
Jun 22, 2024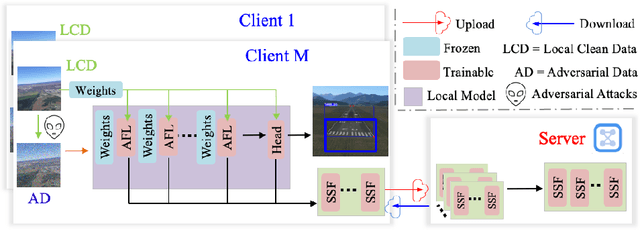
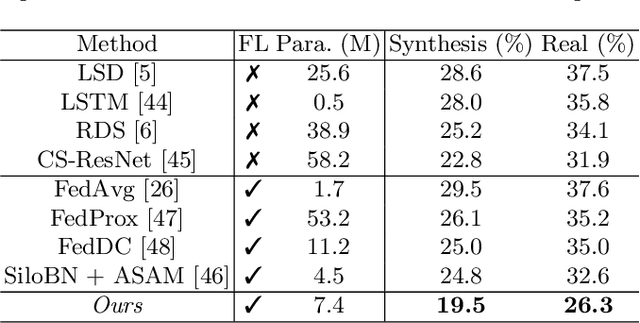
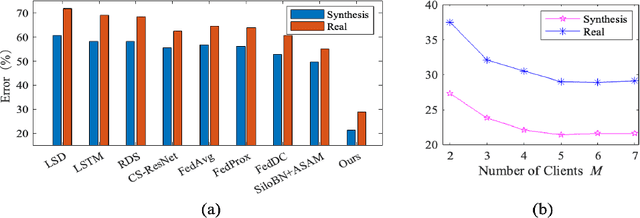
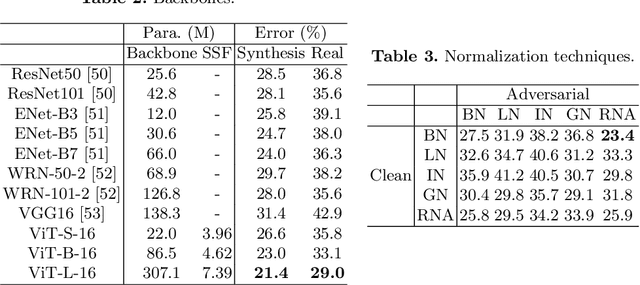
As the development of deep learning techniques in autonomous landing systems continues to grow, one of the major challenges is trust and security in the face of possible adversarial attacks. In this paper, we propose a federated adversarial learning-based framework to detect landing runways using paired data comprising of clean local data and its adversarial version. Firstly, the local model is pre-trained on a large-scale lane detection dataset. Then, instead of exploiting large instance-adaptive models, we resort to a parameter-efficient fine-tuning method known as scale and shift deep features (SSF), upon the pre-trained model. Secondly, in each SSF layer, distributions of clean local data and its adversarial version are disentangled for accurate statistics estimation. To the best of our knowledge, this marks the first instance of federated learning work that address the adversarial sample problem in landing runway detection. Our experimental evaluations over both synthesis and real images of Landing Approach Runway Detection (LARD) dataset consistently demonstrate good performance of the proposed federated adversarial learning and robust to adversarial attacks.
* ICANN2024
IMAFD: An Interpretable Multi-stage Approach to Flood Detection from time series Multispectral Data
May 13, 2024



In this paper, we address two critical challenges in the domain of flood detection: the computational expense of large-scale time series change detection and the lack of interpretable decision-making processes on explainable AI (XAI). To overcome these challenges, we proposed an interpretable multi-stage approach to flood detection, IMAFD has been proposed. It provides an automatic, efficient and interpretable solution suitable for large-scale remote sensing tasks and offers insight into the decision-making process. The proposed IMAFD approach combines the analysis of the dynamic time series image sequences to identify images with possible flooding with the static, within-image semantic segmentation. It combines anomaly detection (at both image and pixel level) with semantic segmentation. The flood detection problem is addressed through four stages: (1) at a sequence level: identifying the suspected images (2) at a multi-image level: detecting change within suspected images (3) at an image level: semantic segmentation of images into Land, Water or Cloud class (4) decision making. Our contributions are two folder. First, we efficiently reduced the number of frames to be processed for dense change detection by providing a multi-stage holistic approach to flood detection. Second, the proposed semantic change detection method (stage 3) provides human users with an interpretable decision-making process, while most of the explainable AI (XAI) methods provide post hoc explanations. The evaluation of the proposed IMAFD framework was performed on three datasets, WorldFloods, RavAEn and MediaEval. For all the above datasets, the proposed framework demonstrates a competitive performance compared to other methods offering also interpretability and insight.
Unsupervised Domain Adaptation within Deep Foundation Latent Spaces
Feb 22, 2024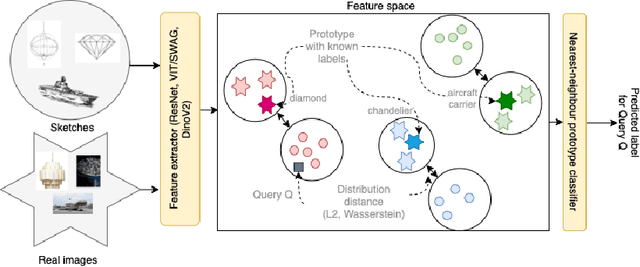

The vision transformer-based foundation models, such as ViT or Dino-V2, are aimed at solving problems with little or no finetuning of features. Using a setting of prototypical networks, we analyse to what extent such foundation models can solve unsupervised domain adaptation without finetuning over the source or target domain. Through quantitative analysis, as well as qualitative interpretations of decision making, we demonstrate that the suggested method can improve upon existing baselines, as well as showcase the limitations of such approach yet to be solved.
Towards interpretable-by-design deep learning algorithms
Nov 19, 2023



The proposed framework named IDEAL (Interpretable-by-design DEep learning ALgorithms) recasts the standard supervised classification problem into a function of similarity to a set of prototypes derived from the training data, while taking advantage of existing latent spaces of large neural networks forming so-called Foundation Models (FM). This addresses the issue of explainability (stage B) while retaining the benefits from the tremendous achievements offered by DL models (e.g., visual transformers, ViT) pre-trained on huge data sets such as IG-3.6B + ImageNet-1K or LVD-142M (stage A). We show that one can turn such DL models into conceptually simpler, explainable-through-prototypes ones. The key findings can be summarized as follows: (1) the proposed models are interpretable through prototypes, mitigating the issue of confounded interpretations, (2) the proposed IDEAL framework circumvents the issue of catastrophic forgetting allowing efficient class-incremental learning, and (3) the proposed IDEAL approach demonstrates that ViT architectures narrow the gap between finetuned and non-finetuned models allowing for transfer learning in a fraction of time \textbf{without} finetuning of the feature space on a target dataset with iterative supervised methods.