Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation within Deep Foundation Latent Spaces
Paper and Code
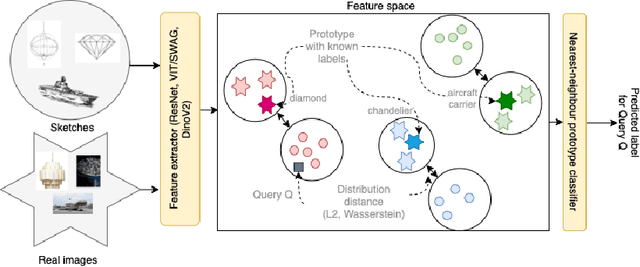

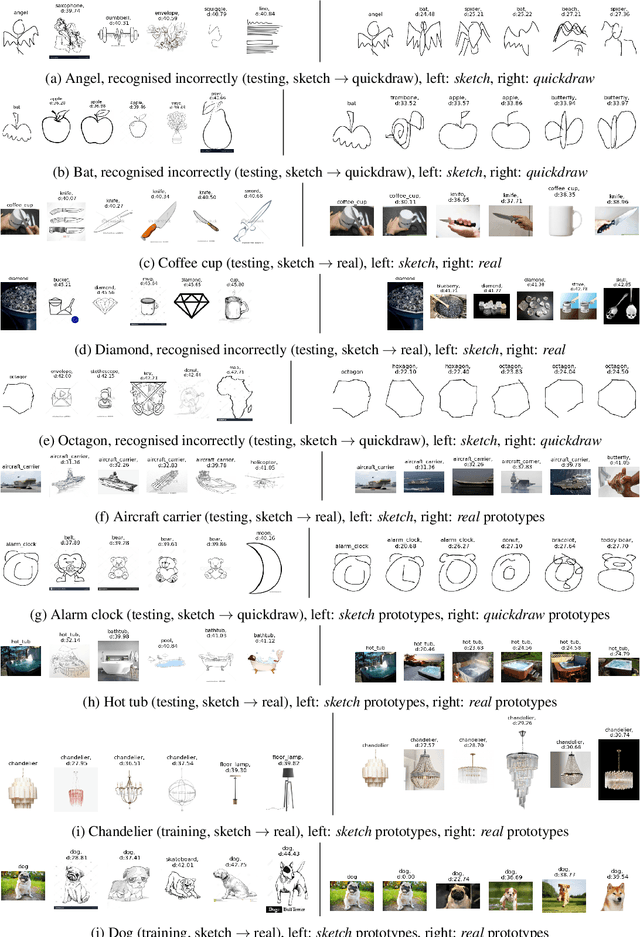
The vision transformer-based foundation models, such as ViT or Dino-V2, are aimed at solving problems with little or no finetuning of features. Using a setting of prototypical networks, we analyse to what extent such foundation models can solve unsupervised domain adaptation without finetuning over the source or target domain. Through quantitative analysis, as well as qualitative interpretations of decision making, we demonstrate that the suggested method can improve upon existing baselines, as well as showcase the limitations of such approach yet to be solved.
View paper on