 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConRF: Zero-shot Stylization of 3D Scenes with Conditioned Radiation Fields
Paper and Code
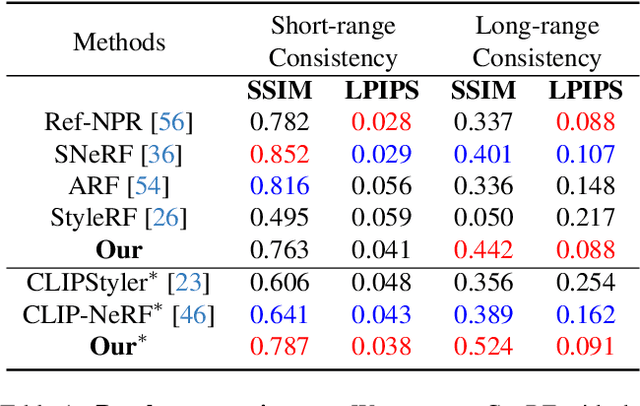
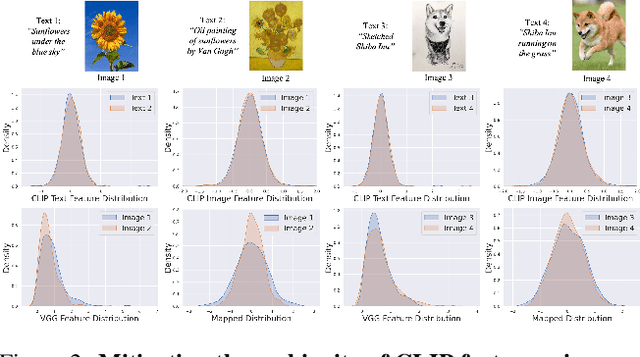
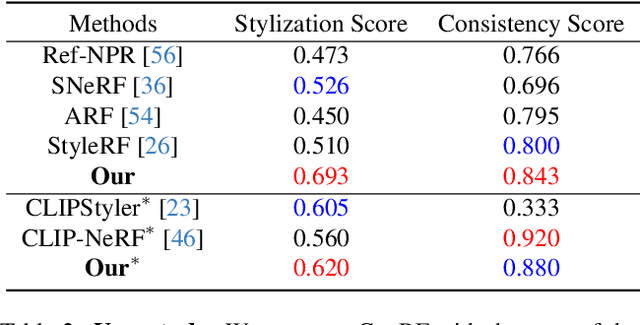
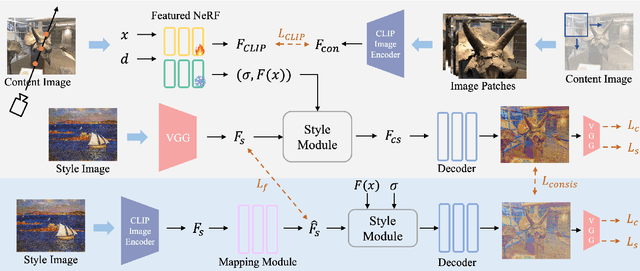
Most of the existing works on arbitrary 3D NeRF style transfer required retraining on each single style condition. This work aims to achieve zero-shot controlled stylization in 3D scenes utilizing text or visual input as conditioning factors. We introduce ConRF, a novel method of zero-shot stylization. Specifically, due to the ambiguity of CLIP features, we employ a conversion process that maps the CLIP feature space to the style space of a pre-trained VGG network and then refine the CLIP multi-modal knowledge into a style transfer neural radiation field. Additionally, we use a 3D volumetric representation to perform local style transfer. By combining these operations, ConRF offers the capability to utilize either text or images as references, resulting in the generation of sequences with novel views enhanced by global or local stylization. Our experiment demonstrates that ConRF outperforms other existing methods for 3D scene and single-text stylization in terms of visual quality.