 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Camera Motions in Any Video
Apr 21, 2025
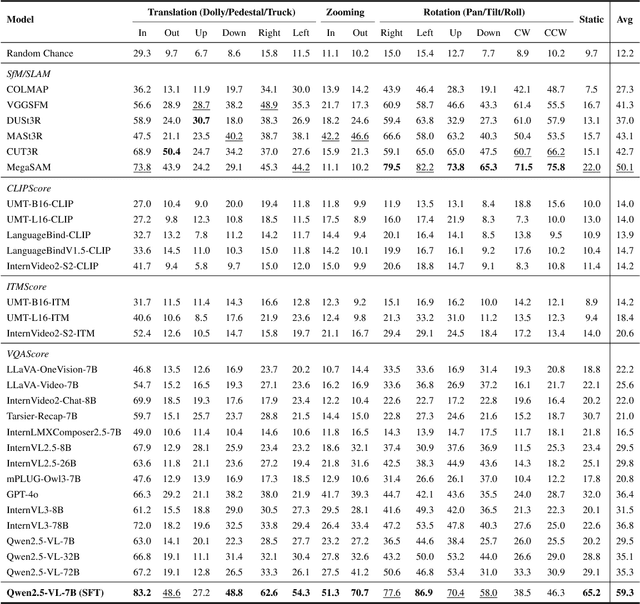
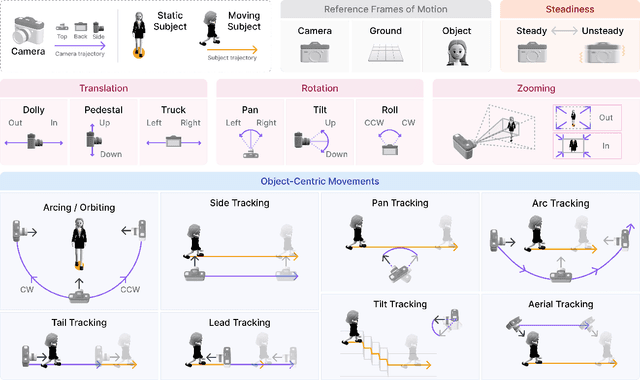
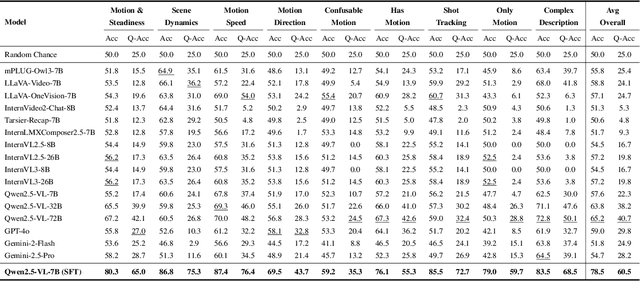
We introduce CameraBench, a large-scale dataset and benchmark designed to assess and improve camera motion understanding. CameraBench consists of ~3,000 diverse internet videos, annotated by experts through a rigorous multi-stage quality control process. One of our contributions is a taxonomy of camera motion primitives, designed in collaboration with cinematographers. We find, for example, that some motions like "follow" (or tracking) require understanding scene content like moving subjects. We conduct a large-scale human study to quantify human annotation performance, revealing that domain expertise and tutorial-based training can significantly enhance accuracy. For example, a novice may confuse zoom-in (a change of intrinsics) with translating forward (a change of extrinsics), but can be trained to differentiate the two. Using CameraBench, we evaluate Structure-from-Motion (SfM) and Video-Language Models (VLMs), finding that SfM models struggle to capture semantic primitives that depend on scene content, while VLMs struggle to capture geometric primitives that require precise estimation of trajectories. We then fine-tune a generative VLM on CameraBench to achieve the best of both worlds and showcase its applications, including motion-augmented captioning, video question answering, and video-text retrieval. We hope our taxonomy, benchmark, and tutorials will drive future efforts towards the ultimate goal of understanding camera motions in any video.
Brain Mapping with Dense Features: Grounding Cortical Semantic Selectivity in Natural Images With Vision Transformers
Oct 07, 2024



Advances in large-scale artificial neural networks have facilitated novel insights into the functional topology of the brain. Here, we leverage this approach to study how semantic categories are organized in the human visual cortex. To overcome the challenge presented by the co-occurrence of multiple categories in natural images, we introduce BrainSAIL (Semantic Attribution and Image Localization), a method for isolating specific neurally-activating visual concepts in images. BrainSAIL exploits semantically consistent, dense spatial features from pre-trained vision models, building upon their demonstrated ability to robustly predict neural activity. This method derives clean, spatially dense embeddings without requiring any additional training, and employs a novel denoising process that leverages the semantic consistency of images under random augmentations. By unifying the space of whole-image embeddings and dense visual features and then applying voxel-wise encoding models to these features, we enable the identification of specific subregions of each image which drive selectivity patterns in different areas of the higher visual cortex. We validate BrainSAIL on cortical regions with known category selectivity, demonstrating its ability to accurately localize and disentangle selectivity to diverse visual concepts. Next, we demonstrate BrainSAIL's ability to characterize high-level visual selectivity to scene properties and low-level visual features such as depth, luminance, and saturation, providing insights into the encoding of complex visual information. Finally, we use BrainSAIL to directly compare the feature selectivity of different brain encoding models across different regions of interest in visual cortex. Our innovative method paves the way for significant advances in mapping and decomposing high-level visual representations in the human brain.
StableSemantics: A Synthetic Language-Vision Dataset of Semantic Representations in Naturalistic Images
Jun 19, 2024



Understanding the semantics of visual scenes is a fundamental challenge in Computer Vision. A key aspect of this challenge is that objects sharing similar semantic meanings or functions can exhibit striking visual differences, making accurate identification and categorization difficult. Recent advancements in text-to-image frameworks have led to models that implicitly capture natural scene statistics. These frameworks account for the visual variability of objects, as well as complex object co-occurrences and sources of noise such as diverse lighting conditions. By leveraging large-scale datasets and cross-attention conditioning, these models generate detailed and contextually rich scene representations. This capability opens new avenues for improving object recognition and scene understanding in varied and challenging environments. Our work presents StableSemantics, a dataset comprising 224 thousand human-curated prompts, processed natural language captions, over 2 million synthetic images, and 10 million attention maps corresponding to individual noun chunks. We explicitly leverage human-generated prompts that correspond to visually interesting stable diffusion generations, provide 10 generations per phrase, and extract cross-attention maps for each image. We explore the semantic distribution of generated images, examine the distribution of objects within images, and benchmark captioning and open vocabulary segmentation methods on our data. To the best of our knowledge, we are the first to release a diffusion dataset with semantic attributions. We expect our proposed dataset to catalyze advances in visual semantic understanding and provide a foundation for developing more sophisticated and effective visual models. Website: https://stablesemantics.github.io/StableSemantics
DiffusionPID: Interpreting Diffusion via Partial Information Decomposition
Jun 07, 2024
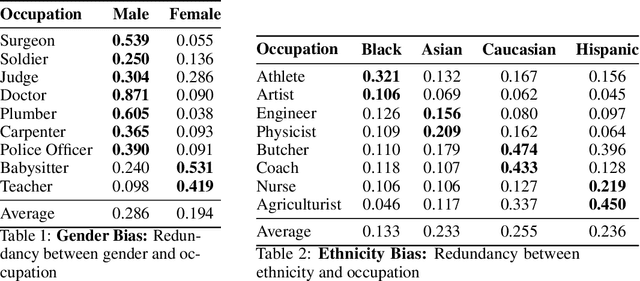


Text-to-image diffusion models have made significant progress in generating naturalistic images from textual inputs, and demonstrate the capacity to learn and represent complex visual-semantic relationships. While these diffusion models have achieved remarkable success, the underlying mechanisms driving their performance are not yet fully accounted for, with many unanswered questions surrounding what they learn, how they represent visual-semantic relationships, and why they sometimes fail to generalize. Our work presents Diffusion Partial Information Decomposition (DiffusionPID), a novel technique that applies information-theoretic principles to decompose the input text prompt into its elementary components, enabling a detailed examination of how individual tokens and their interactions shape the generated image. We introduce a formal approach to analyze the uniqueness, redundancy, and synergy terms by applying PID to the denoising model at both the image and pixel level. This approach enables us to characterize how individual tokens and their interactions affect the model output. We first present a fine-grained analysis of characteristics utilized by the model to uniquely localize specific concepts, we then apply our approach in bias analysis and show it can recover gender and ethnicity biases. Finally, we use our method to visually characterize word ambiguity and similarity from the model's perspective and illustrate the efficacy of our method for prompt intervention. Our results show that PID is a potent tool for evaluating and diagnosing text-to-image diffusion models.
Detecting Anomalies using Generative Adversarial Networks on Images
Nov 24, 2022

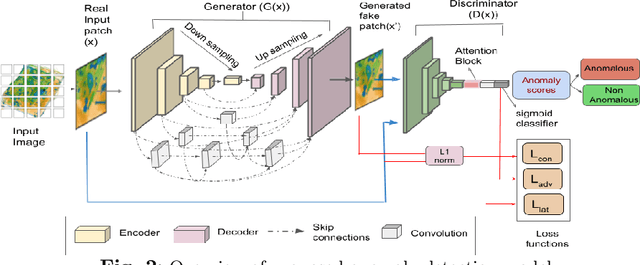
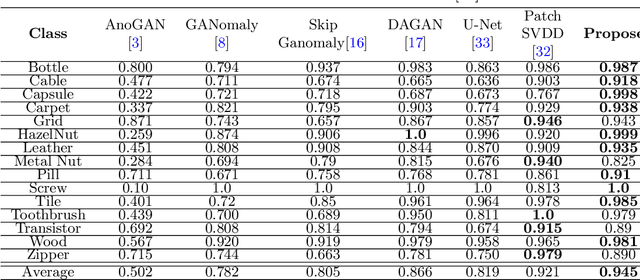
Automatic detection of anomalies such as weapons or threat objects in baggage security, or detecting impaired items in industrial production is an important computer vision task demanding high efficiency and accuracy. Most of the available data in the anomaly detection task is imbalanced as the number of positive/anomalous instances is sparse. Inadequate availability of the data makes training of a deep neural network architecture for anomaly detection challenging. This paper proposes a novel Generative Adversarial Network (GAN) based model for anomaly detection. It uses normal (non-anomalous) images to learn about the normality based on which it detects if an input image contains an anomalous/threat object. The proposed model uses a generator with an encoder-decoder network having dense convolutional skip connections for enhanced reconstruction and to capture the data distribution. A self-attention augmented discriminator is used having the ability to check the consistency of detailed features even in distant portions. We use spectral normalisation to facilitate stable and improved training of the GAN. Experiments are performed on three datasets, viz. CIFAR-10, MVTec AD (for industrial applications) and SIXray (for X-ray baggage security). On the MVTec AD and SIXray datasets, our model achieves an improvement of upto 21% and 4.6%, respectively