 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-FoundationStereo: Real-Time Zero-Shot Stereo Matching
Dec 11, 2025Stereo foundation models achieve strong zero-shot generalization but remain computationally prohibitive for real-time applications. Efficient stereo architectures, on the other hand, sacrifice robustness for speed and require costly per-domain fine-tuning. To bridge this gap, we present Fast-FoundationStereo, a family of architectures that achieve, for the first time, strong zero-shot generalization at real-time frame rate. We employ a divide-and-conquer acceleration strategy with three components: (1) knowledge distillation to compress the hybrid backbone into a single efficient student; (2) blockwise neural architecture search for automatically discovering optimal cost filtering designs under latency budgets, reducing search complexity exponentially; and (3) structured pruning for eliminating redundancy in the iterative refinement module. Furthermore, we introduce an automatic pseudo-labeling pipeline used to curate 1.4M in-the-wild stereo pairs to supplement synthetic training data and facilitate knowledge distillation. The resulting model can run over 10x faster than FoundationStereo while closely matching its zero-shot accuracy, thus establishing a new state-of-the-art among real-time methods. Project page: https://nvlabs.github.io/Fast-FoundationStereo/
Brain Mapping with Dense Features: Grounding Cortical Semantic Selectivity in Natural Images With Vision Transformers
Oct 07, 2024



Advances in large-scale artificial neural networks have facilitated novel insights into the functional topology of the brain. Here, we leverage this approach to study how semantic categories are organized in the human visual cortex. To overcome the challenge presented by the co-occurrence of multiple categories in natural images, we introduce BrainSAIL (Semantic Attribution and Image Localization), a method for isolating specific neurally-activating visual concepts in images. BrainSAIL exploits semantically consistent, dense spatial features from pre-trained vision models, building upon their demonstrated ability to robustly predict neural activity. This method derives clean, spatially dense embeddings without requiring any additional training, and employs a novel denoising process that leverages the semantic consistency of images under random augmentations. By unifying the space of whole-image embeddings and dense visual features and then applying voxel-wise encoding models to these features, we enable the identification of specific subregions of each image which drive selectivity patterns in different areas of the higher visual cortex. We validate BrainSAIL on cortical regions with known category selectivity, demonstrating its ability to accurately localize and disentangle selectivity to diverse visual concepts. Next, we demonstrate BrainSAIL's ability to characterize high-level visual selectivity to scene properties and low-level visual features such as depth, luminance, and saturation, providing insights into the encoding of complex visual information. Finally, we use BrainSAIL to directly compare the feature selectivity of different brain encoding models across different regions of interest in visual cortex. Our innovative method paves the way for significant advances in mapping and decomposing high-level visual representations in the human brain.
StableSemantics: A Synthetic Language-Vision Dataset of Semantic Representations in Naturalistic Images
Jun 19, 2024



Understanding the semantics of visual scenes is a fundamental challenge in Computer Vision. A key aspect of this challenge is that objects sharing similar semantic meanings or functions can exhibit striking visual differences, making accurate identification and categorization difficult. Recent advancements in text-to-image frameworks have led to models that implicitly capture natural scene statistics. These frameworks account for the visual variability of objects, as well as complex object co-occurrences and sources of noise such as diverse lighting conditions. By leveraging large-scale datasets and cross-attention conditioning, these models generate detailed and contextually rich scene representations. This capability opens new avenues for improving object recognition and scene understanding in varied and challenging environments. Our work presents StableSemantics, a dataset comprising 224 thousand human-curated prompts, processed natural language captions, over 2 million synthetic images, and 10 million attention maps corresponding to individual noun chunks. We explicitly leverage human-generated prompts that correspond to visually interesting stable diffusion generations, provide 10 generations per phrase, and extract cross-attention maps for each image. We explore the semantic distribution of generated images, examine the distribution of objects within images, and benchmark captioning and open vocabulary segmentation methods on our data. To the best of our knowledge, we are the first to release a diffusion dataset with semantic attributions. We expect our proposed dataset to catalyze advances in visual semantic understanding and provide a foundation for developing more sophisticated and effective visual models. Website: https://stablesemantics.github.io/StableSemantics
DiffusionPID: Interpreting Diffusion via Partial Information Decomposition
Jun 07, 2024
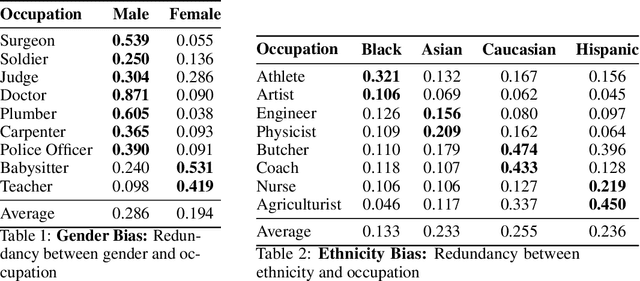


Text-to-image diffusion models have made significant progress in generating naturalistic images from textual inputs, and demonstrate the capacity to learn and represent complex visual-semantic relationships. While these diffusion models have achieved remarkable success, the underlying mechanisms driving their performance are not yet fully accounted for, with many unanswered questions surrounding what they learn, how they represent visual-semantic relationships, and why they sometimes fail to generalize. Our work presents Diffusion Partial Information Decomposition (DiffusionPID), a novel technique that applies information-theoretic principles to decompose the input text prompt into its elementary components, enabling a detailed examination of how individual tokens and their interactions shape the generated image. We introduce a formal approach to analyze the uniqueness, redundancy, and synergy terms by applying PID to the denoising model at both the image and pixel level. This approach enables us to characterize how individual tokens and their interactions affect the model output. We first present a fine-grained analysis of characteristics utilized by the model to uniquely localize specific concepts, we then apply our approach in bias analysis and show it can recover gender and ethnicity biases. Finally, we use our method to visually characterize word ambiguity and similarity from the model's perspective and illustrate the efficacy of our method for prompt intervention. Our results show that PID is a potent tool for evaluating and diagnosing text-to-image diffusion models.
Curiosity & Entropy Driven Unsupervised RL in Multiple Environments
Jan 08, 2024The authors of 'Unsupervised Reinforcement Learning in Multiple environments' propose a method, alpha-MEPOL, to tackle unsupervised RL across multiple environments. They pre-train a task-agnostic exploration policy using interactions from an entire environment class and then fine-tune this policy for various tasks using supervision. We expanded upon this work, with the goal of improving performance. We primarily propose and experiment with five new modifications to the original work: sampling trajectories using an entropy-based probability distribution, dynamic alpha, higher KL Divergence threshold, curiosity-driven exploration, and alpha-percentile sampling on curiosity. Dynamic alpha and higher KL-Divergence threshold both provided a significant improvement over the baseline from the earlier work. PDF-sampling failed to provide any improvement due to it being approximately equivalent to the baseline method when the sample space is small. In high-dimensional environments, the addition of curiosity-driven exploration enhances learning by encouraging the agent to seek diverse experiences and explore the unknown more. However, its benefits are limited in low-dimensional and simpler environments where exploration possibilities are constrained and there is little that is truly unknown to the agent. Overall, some of our experiments did boost performance over the baseline and there are a few directions that seem promising for further research.
Canonical Fields: Self-Supervised Learning of Pose-Canonicalized Neural Fields
Dec 05, 2022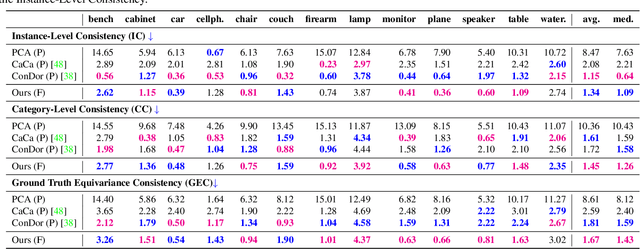
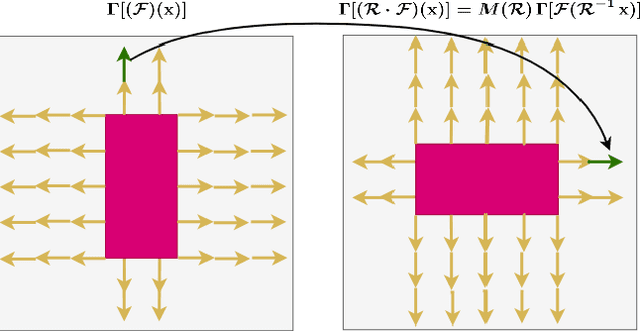
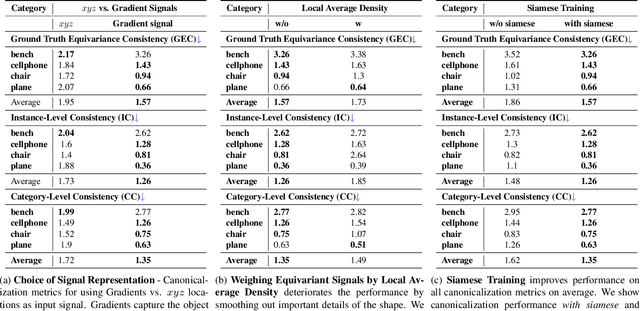
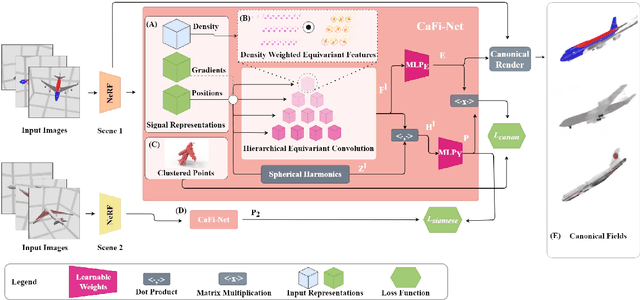
Coordinate-based implicit neural networks, or neural fields, have emerged as useful representations of shape and appearance in 3D computer vision. Despite advances however, it remains challenging to build neural fields for categories of objects without datasets like ShapeNet that provide canonicalized object instances that are consistently aligned for their 3D position and orientation (pose). We present Canonical Field Network (CaFi-Net), a self-supervised method to canonicalize the 3D pose of instances from an object category represented as neural fields, specifically neural radiance fields (NeRFs). CaFi-Net directly learns from continuous and noisy radiance fields using a Siamese network architecture that is designed to extract equivariant field features for category-level canonicalization. During inference, our method takes pre-trained neural radiance fields of novel object instances at arbitrary 3D pose, and estimates a canonical field with consistent 3D pose across the entire category. Extensive experiments on a new dataset of 1300 NeRF models across 13 object categories show that our method matches or exceeds the performance of 3D point cloud-based methods.