 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenHSI: Controllable Generation of Human-Scene Interaction Videos
Jun 24, 2025Large-scale pre-trained video diffusion models have exhibited remarkable capabilities in diverse video generation. However, existing solutions face several challenges in using these models to generate long movie-like videos with rich human-object interactions that include unrealistic human-scene interaction, lack of subject identity preservation, and require expensive training. We propose GenHSI, a training-free method for controllable generation of long human-scene interaction videos (HSI). Taking inspiration from movie animation, our key insight is to overcome the limitations of previous work by subdividing the long video generation task into three stages: (1) script writing, (2) pre-visualization, and (3) animation. Given an image of a scene, a user description, and multiple images of a person, we use these three stages to generate long-videos that preserve human-identity and provide rich human-scene interactions. Script writing converts complex human tasks into simple atomic tasks that are used in the pre-visualization stage to generate 3D keyframes (storyboards). These 3D keyframes are rendered and animated by off-the-shelf video diffusion models for consistent long video generation with rich contacts in a 3D-aware manner. A key advantage of our work is that we alleviate the need for scanned, accurate scenes and create 3D keyframes from single-view images. We are the first to generate a long video sequence with a consistent camera pose that contains arbitrary numbers of character actions without training. Experiments demonstrate that our method can generate long videos that effectively preserve scene content and character identity with plausible human-scene interaction from a single image scene. Visit our project homepage https://kunkun0w0.github.io/project/GenHSI/ for more information.
GeoDiffuser: Geometry-Based Image Editing with Diffusion Models
Apr 22, 2024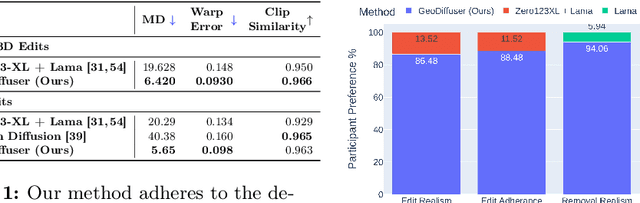

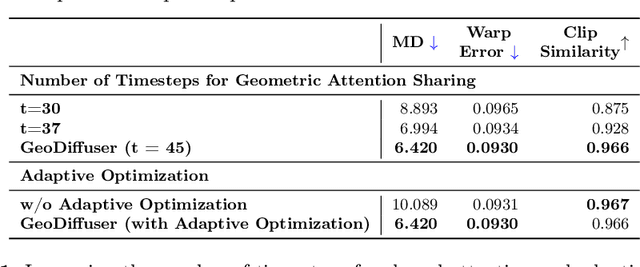
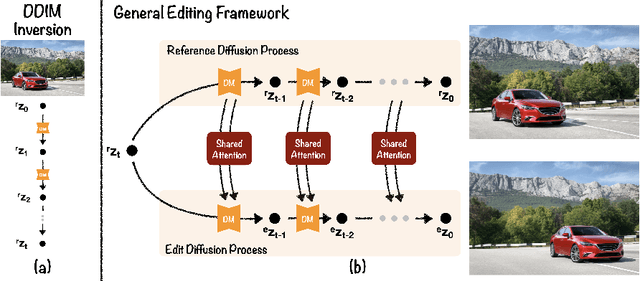
The success of image generative models has enabled us to build methods that can edit images based on text or other user input. However, these methods are bespoke, imprecise, require additional information, or are limited to only 2D image edits. We present GeoDiffuser, a zero-shot optimization-based method that unifies common 2D and 3D image-based object editing capabilities into a single method. Our key insight is to view image editing operations as geometric transformations. We show that these transformations can be directly incorporated into the attention layers in diffusion models to implicitly perform editing operations. Our training-free optimization method uses an objective function that seeks to preserve object style but generate plausible images, for instance with accurate lighting and shadows. It also inpaints disoccluded parts of the image where the object was originally located. Given a natural image and user input, we segment the foreground object using SAM and estimate a corresponding transform which is used by our optimization approach for editing. GeoDiffuser can perform common 2D and 3D edits like object translation, 3D rotation, and removal. We present quantitative results, including a perceptual study, that shows how our approach is better than existing methods. Visit https://ivl.cs.brown.edu/research/geodiffuser.html for more information.
LEGO-Net: Learning Regular Rearrangements of Objects in Rooms
Jan 23, 2023



Humans universally dislike the task of cleaning up a messy room. If machines were to help us with this task, they must understand human criteria for regular arrangements, such as several types of symmetry, co-linearity or co-circularity, spacing uniformity in linear or circular patterns, and further inter-object relationships that relate to style and functionality. Previous approaches for this task relied on human input to explicitly specify goal state, or synthesized scenes from scratch -- but such methods do not address the rearrangement of existing messy scenes without providing a goal state. In this paper, we present LEGO-Net, a data-driven transformer-based iterative method for learning regular rearrangement of objects in messy rooms. LEGO-Net is partly inspired by diffusion models -- it starts with an initial messy state and iteratively "de-noises'' the position and orientation of objects to a regular state while reducing the distance traveled. Given randomly perturbed object positions and orientations in an existing dataset of professionally-arranged scenes, our method is trained to recover a regular re-arrangement. Results demonstrate that our method is able to reliably rearrange room scenes and outperform other methods. We additionally propose a metric for evaluating regularity in room arrangements using number-theoretic machinery.
Canonical Fields: Self-Supervised Learning of Pose-Canonicalized Neural Fields
Dec 05, 2022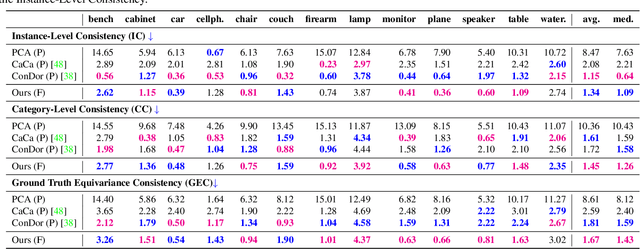
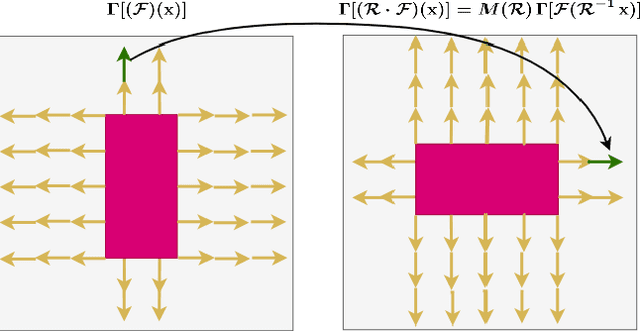
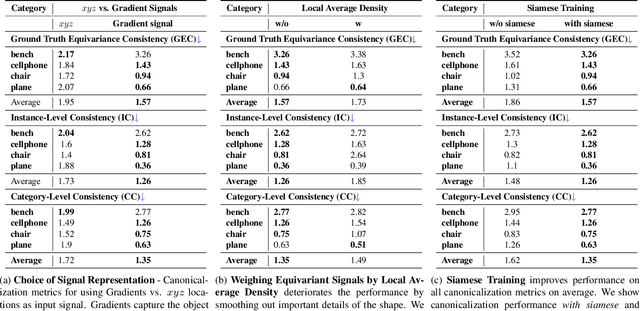
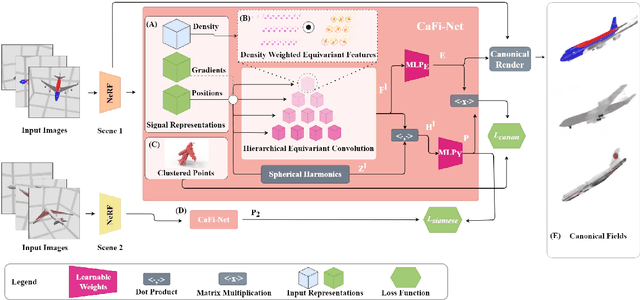
Coordinate-based implicit neural networks, or neural fields, have emerged as useful representations of shape and appearance in 3D computer vision. Despite advances however, it remains challenging to build neural fields for categories of objects without datasets like ShapeNet that provide canonicalized object instances that are consistently aligned for their 3D position and orientation (pose). We present Canonical Field Network (CaFi-Net), a self-supervised method to canonicalize the 3D pose of instances from an object category represented as neural fields, specifically neural radiance fields (NeRFs). CaFi-Net directly learns from continuous and noisy radiance fields using a Siamese network architecture that is designed to extract equivariant field features for category-level canonicalization. During inference, our method takes pre-trained neural radiance fields of novel object instances at arbitrary 3D pose, and estimates a canonical field with consistent 3D pose across the entire category. Extensive experiments on a new dataset of 1300 NeRF models across 13 object categories show that our method matches or exceeds the performance of 3D point cloud-based methods.
ConDor: Self-Supervised Canonicalization of 3D Pose for Partial Shapes
Jan 19, 2022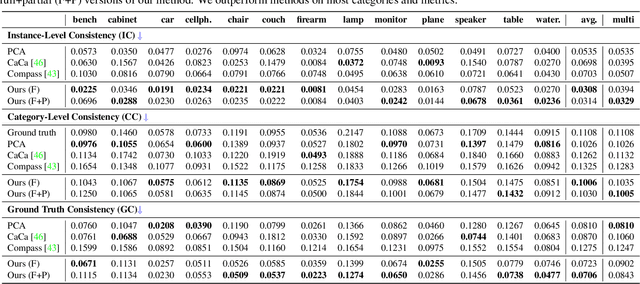
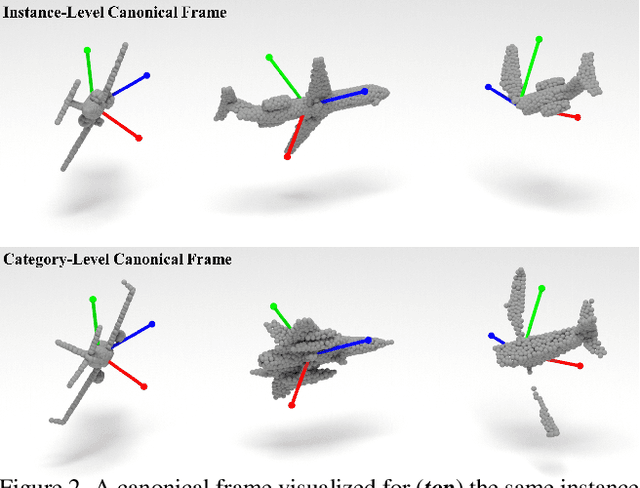
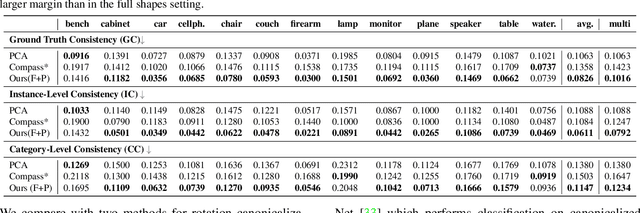
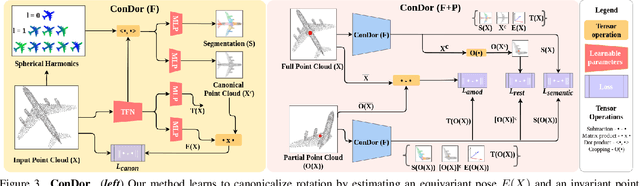
Progress in 3D object understanding has relied on manually canonicalized shape datasets that contain instances with consistent position and orientation (3D pose). This has made it hard to generalize these methods to in-the-wild shapes, eg., from internet model collections or depth sensors. ConDor is a self-supervised method that learns to Canonicalize the 3D orientation and position for full and partial 3D point clouds. We build on top of Tensor Field Networks (TFNs), a class of permutation- and rotation-equivariant, and translation-invariant 3D networks. During inference, our method takes an unseen full or partial 3D point cloud at an arbitrary pose and outputs an equivariant canonical pose. During training, this network uses self-supervision losses to learn the canonical pose from an un-canonicalized collection of full and partial 3D point clouds. ConDor can also learn to consistently co-segment object parts without any supervision. Extensive quantitative results on four new metrics show that our approach outperforms existing methods while enabling new applications such as operation on depth images and annotation transfer.
DRACO: Weakly Supervised Dense Reconstruction And Canonicalization of Objects
Nov 25, 2020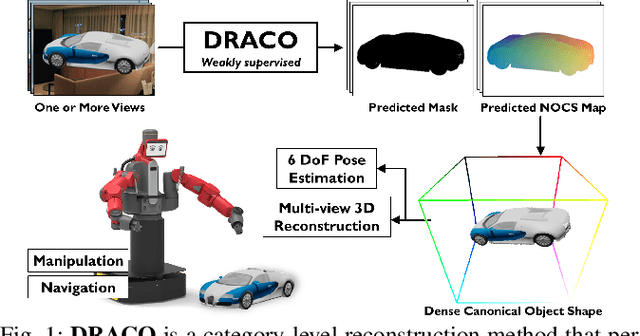
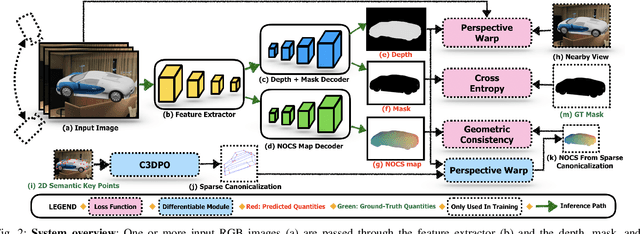
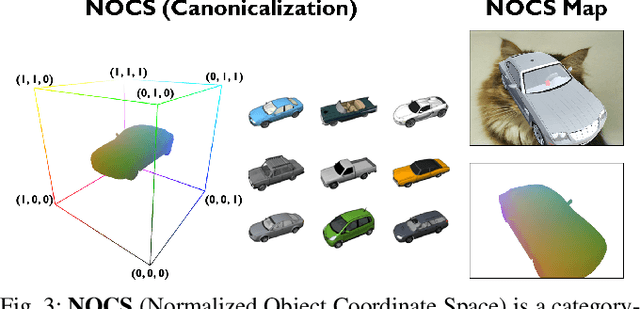

We present DRACO, a method for Dense Reconstruction And Canonicalization of Object shape from one or more RGB images. Canonical shape reconstruction, estimating 3D object shape in a coordinate space canonicalized for scale, rotation, and translation parameters, is an emerging paradigm that holds promise for a multitude of robotic applications. Prior approaches either rely on painstakingly gathered dense 3D supervision, or produce only sparse canonical representations, limiting real-world applicability. DRACO performs dense canonicalization using only weak supervision in the form of camera poses and semantic keypoints at train time. During inference, DRACO predicts dense object-centric depth maps in a canonical coordinate-space, solely using one or more RGB images of an object. Extensive experiments on canonical shape reconstruction and pose estimation show that DRACO is competitive or superior to fully-supervised methods.
BirdSLAM: Monocular Multibody SLAM in Bird's-Eye View
Nov 15, 2020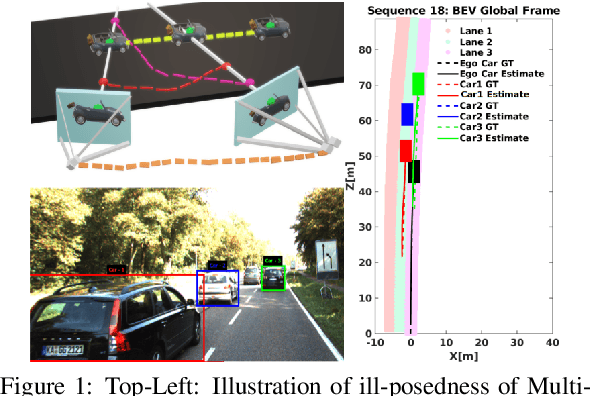
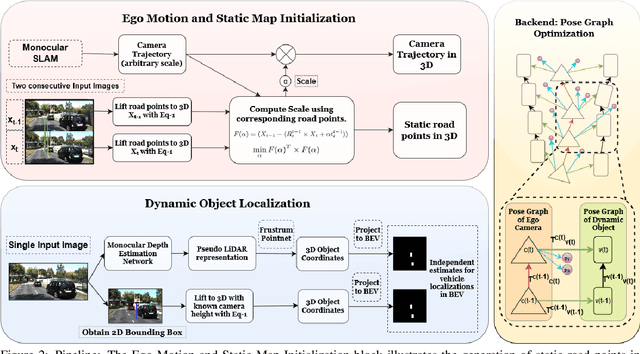
In this paper, we present BirdSLAM, a novel simultaneous localization and mapping (SLAM) system for the challenging scenario of autonomous driving platforms equipped with only a monocular camera. BirdSLAM tackles challenges faced by other monocular SLAM systems (such as scale ambiguity in monocular reconstruction, dynamic object localization, and uncertainty in feature representation) by using an orthographic (bird's-eye) view as the configuration space in which localization and mapping are performed. By assuming only the height of the ego-camera above the ground, BirdSLAM leverages single-view metrology cues to accurately localize the ego-vehicle and all other traffic participants in bird's-eye view. We demonstrate that our system outperforms prior work that uses strictly greater information, and highlight the relevance of each design decision via an ablation analysis.
Multi-object Monocular SLAM for Dynamic Environments
Feb 10, 2020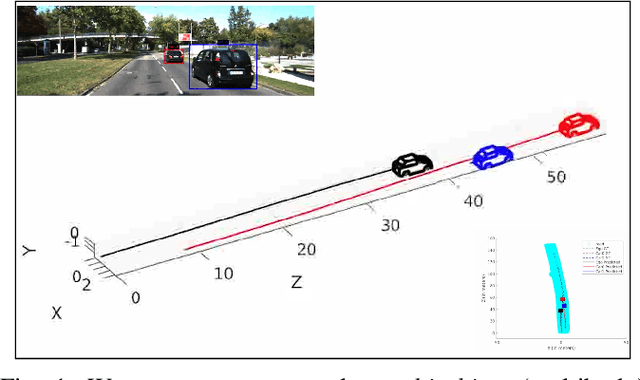
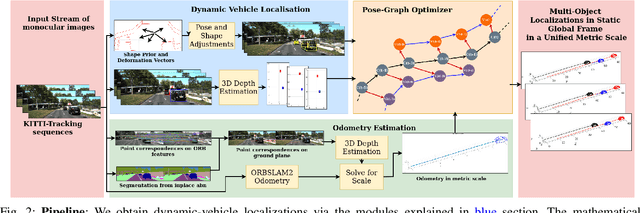
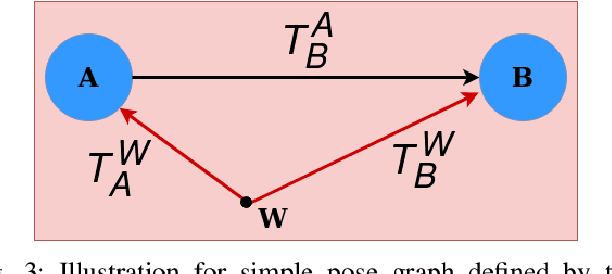
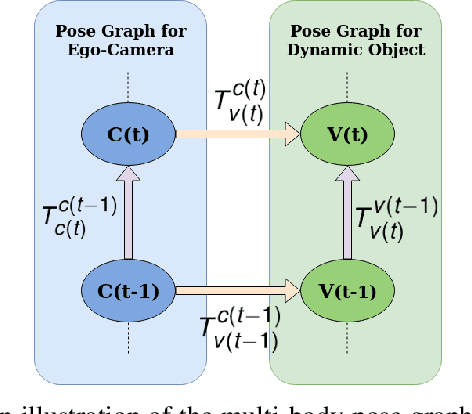
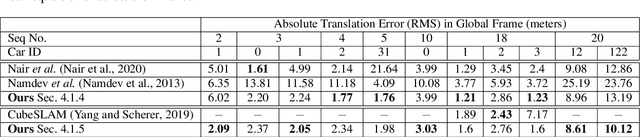
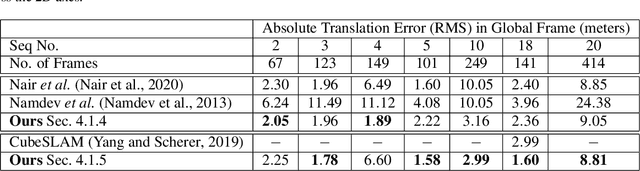
Multibody monocular SLAM in dynamic environments remains a long-standing challenge in terms of perception and state estimation. Although theoretical solutions exist, practice lags behind, predominantly due to the lack of robust perceptual and predictive models of dynamic participants. The quintessential challenge in Multi-body monocular SLAM in dynamic scenes stems from the problem of unobservability as it is not possible to triangulate a moving object from a moving monocular camera. Under restrictions of object motion the problem can be solved, however even here one is entailed to solve for the single family solution to the relative scale problem. The relative scale problem exists since the dynamic objects that get reconstructed with the monocular camera have a different scale vis a vis the scale space in which the stationary scene is reconstructed. We solve this rather intractable problem by reconstructing dynamic vehicles/participants in single view in metric scale through an object SLAM pipeline. Further, we lift the ego vehicle trajectory obtained from Monocular ORB-SLAM also into metric scales making use of ground plane features thereby resolving the relative scale problem. We present a multi pose-graph optimization formulation to estimate the pose and track dynamic objects in the environment. This optimization helps us reduce the average error in trajectories of multiple bodies in KITTI Tracking sequences. To the best of our knowledge, our method is the first practical monocular multi-body SLAM system to perform dynamic multi-object and ego localization in a unified framework in metric scale.