 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Deep Convolutional Neural Network Model For Yoga Pose Recognition Using Single Images
Jun 27, 2023Pose recognition deals with designing algorithms to locate human body joints in a 2D/3D space and run inference on the estimated joint locations for predicting the poses. Yoga poses consist of some very complex postures. It imposes various challenges on the computer vision algorithms like occlusion, inter-class similarity, intra-class variability, viewpoint complexity, etc. This paper presents YPose, an efficient deep convolutional neural network (CNN) model to recognize yoga asanas from RGB images. The proposed model consists of four steps as follows: (a) first, the region of interest (ROI) is segmented using segmentation based approaches to extract the ROI from the original images; (b) second, these refined images are passed to a CNN architecture based on the backbone of EfficientNets for feature extraction; (c) third, dense refinement blocks, adapted from the architecture of densely connected networks are added to learn more diversified features; and (d) fourth, global average pooling and fully connected layers are applied for the classification of the multi-level hierarchy of the yoga poses. The proposed model has been tested on the Yoga-82 dataset. It is a publicly available benchmark dataset for yoga pose recognition. Experimental results show that the proposed model achieves the state-of-the-art on this dataset. The proposed model obtained an accuracy of 93.28%, which is an improvement over the earlier state-of-the-art (79.35%) with a margin of approximately 13.9%. The code will be made publicly available.
A Novel Two Stream Decision Level Fusion of Vision and Inertial Sensors Data for Automatic Multimodal Human Activity Recognition System
Jun 27, 2023This paper presents a novel multimodal human activity recognition system. It uses a two-stream decision level fusion of vision and inertial sensors. In the first stream, raw RGB frames are passed to a part affinity field-based pose estimation network to detect the keypoints of the user. These keypoints are then pre-processed and inputted in a sliding window fashion to a specially designed convolutional neural network for the spatial feature extraction followed by regularized LSTMs to calculate the temporal features. The outputs of LSTM networks are then inputted to fully connected layers for classification. In the second stream, data obtained from inertial sensors are pre-processed and inputted to regularized LSTMs for the feature extraction followed by fully connected layers for the classification. At this stage, the SoftMax scores of two streams are then fused using the decision level fusion which gives the final prediction. Extensive experiments are conducted to evaluate the performance. Four multimodal standard benchmark datasets (UP-Fall detection, UTD-MHAD, Berkeley-MHAD, and C-MHAD) are used for experimentations. The accuracies obtained by the proposed system are 96.9 %, 97.6 %, 98.7 %, and 95.9 % respectively on the UP-Fall Detection, UTDMHAD, Berkeley-MHAD, and C-MHAD datasets. These results are far superior than the current state-of-the-art methods.
DroneAttention: Sparse Weighted Temporal Attention for Drone-Camera Based Activity Recognition
Dec 07, 2022
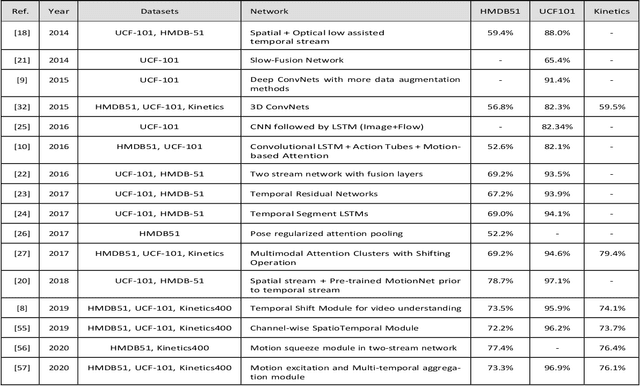
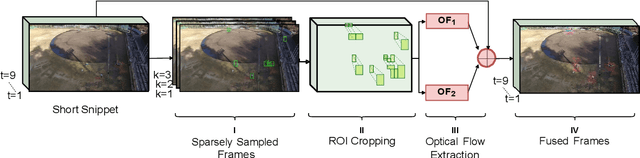
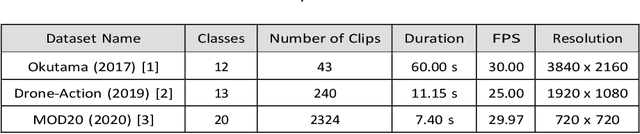
Human activity recognition (HAR) using drone-mounted cameras has attracted considerable interest from the computer vision research community in recent years. A robust and efficient HAR system has a pivotal role in fields like video surveillance, crowd behavior analysis, sports analysis, and human-computer interaction. What makes it challenging are the complex poses, understanding different viewpoints, and the environmental scenarios where the action is taking place. To address such complexities, in this paper, we propose a novel Sparse Weighted Temporal Attention (SWTA) module to utilize sparsely sampled video frames for obtaining global weighted temporal attention. The proposed SWTA is comprised of two parts. First, temporal segment network that sparsely samples a given set of frames. Second, weighted temporal attention, which incorporates a fusion of attention maps derived from optical flow, with raw RGB images. This is followed by a basenet network, which comprises a convolutional neural network (CNN) module along with fully connected layers that provide us with activity recognition. The SWTA network can be used as a plug-in module to the existing deep CNN architectures, for optimizing them to learn temporal information by eliminating the need for a separate temporal stream. It has been evaluated on three publicly available benchmark datasets, namely Okutama, MOD20, and Drone-Action. The proposed model has received an accuracy of 72.76%, 92.56%, and 78.86% on the respective datasets thereby surpassing the previous state-of-the-art performances by a margin of 25.26%, 18.56%, and 2.94%, respectively.
Detecting Anomalies using Generative Adversarial Networks on Images
Nov 24, 2022

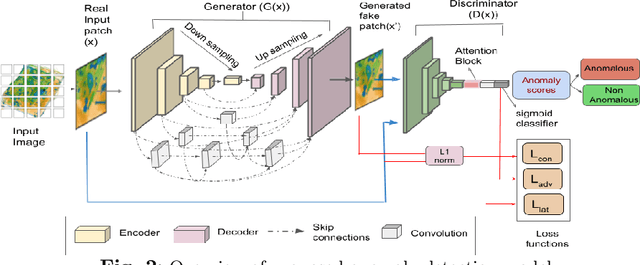
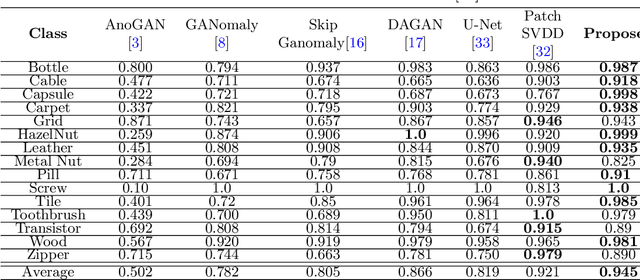
Automatic detection of anomalies such as weapons or threat objects in baggage security, or detecting impaired items in industrial production is an important computer vision task demanding high efficiency and accuracy. Most of the available data in the anomaly detection task is imbalanced as the number of positive/anomalous instances is sparse. Inadequate availability of the data makes training of a deep neural network architecture for anomaly detection challenging. This paper proposes a novel Generative Adversarial Network (GAN) based model for anomaly detection. It uses normal (non-anomalous) images to learn about the normality based on which it detects if an input image contains an anomalous/threat object. The proposed model uses a generator with an encoder-decoder network having dense convolutional skip connections for enhanced reconstruction and to capture the data distribution. A self-attention augmented discriminator is used having the ability to check the consistency of detailed features even in distant portions. We use spectral normalisation to facilitate stable and improved training of the GAN. Experiments are performed on three datasets, viz. CIFAR-10, MVTec AD (for industrial applications) and SIXray (for X-ray baggage security). On the MVTec AD and SIXray datasets, our model achieves an improvement of upto 21% and 4.6%, respectively
SWTF: Sparse Weighted Temporal Fusion for Drone-Based Activity Recognition
Nov 10, 2022Drone-camera based human activity recognition (HAR) has received significant attention from the computer vision research community in the past few years. A robust and efficient HAR system has a pivotal role in fields like video surveillance, crowd behavior analysis, sports analysis, and human-computer interaction. What makes it challenging are the complex poses, understanding different viewpoints, and the environmental scenarios where the action is taking place. To address such complexities, in this paper, we propose a novel Sparse Weighted Temporal Fusion (SWTF) module to utilize sparsely sampled video frames for obtaining global weighted temporal fusion outcome. The proposed SWTF is divided into two components. First, a temporal segment network that sparsely samples a given set of frames. Second, weighted temporal fusion, that incorporates a fusion of feature maps derived from optical flow, with raw RGB images. This is followed by base-network, which comprises a convolutional neural network module along with fully connected layers that provide us with activity recognition. The SWTF network can be used as a plug-in module to the existing deep CNN architectures, for optimizing them to learn temporal information by eliminating the need for a separate temporal stream. It has been evaluated on three publicly available benchmark datasets, namely Okutama, MOD20, and Drone-Action. The proposed model has received an accuracy of 72.76%, 92.56%, and 78.86% on the respective datasets thereby surpassing the previous state-of-the-art performances by a significant margin.
DeepTeeth: A Teeth-photo Based Human Authentication System for Mobile and Hand-held Devices
Jul 28, 2021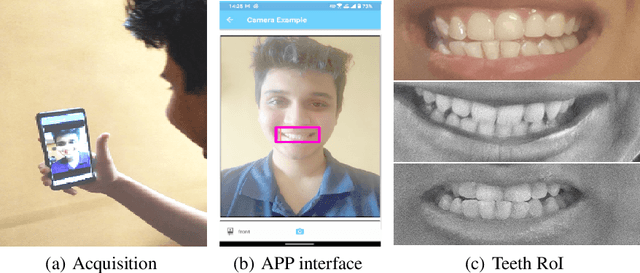
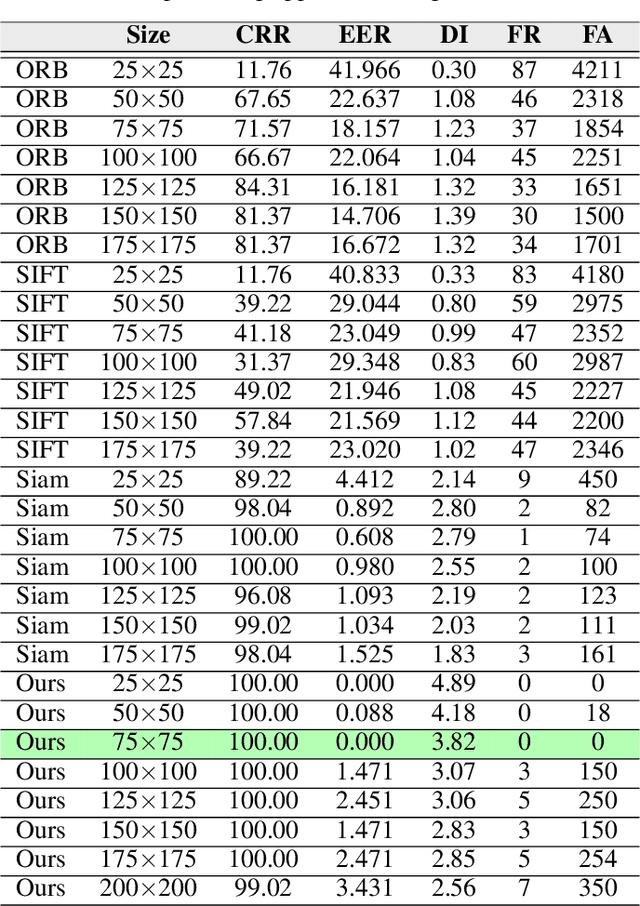

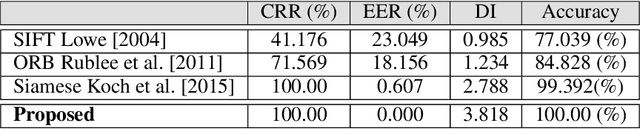
This paper proposes teeth-photo, a new biometric modality for human authentication on mobile and hand held devices. Biometrics samples are acquired using the camera mounted on mobile device with the help of a mobile application having specific markers to register the teeth area. Region of interest (RoI) is then extracted using the markers and the obtained sample is enhanced using contrast limited adaptive histogram equalization (CLAHE) for better visual clarity. We propose a deep learning architecture and novel regularization scheme to obtain highly discriminative embedding for small size RoI. Proposed custom loss function was able to achieve perfect classification for the tiny RoI of $75\times 75$ size. The model is end-to-end and few-shot and therefore is very efficient in terms of time and energy requirements. The system can be used in many ways including device unlocking and secure authentication. To the best of our understanding, this is the first work on teeth-photo based authentication for mobile device. Experiments have been conducted on an in-house teeth-photo database collected using our application. The database is made publicly available. Results have shown that the proposed system has perfect accuracy.
SP-NET: One Shot Fingerprint Singular-Point Detector
Aug 13, 2019

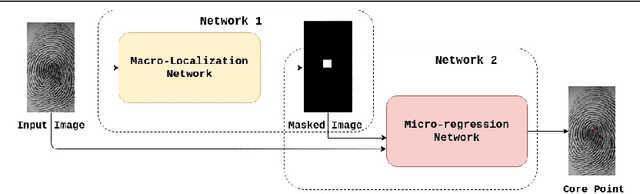

Singular points of a fingerprint image are special locations having high curvature properties. They can play a pivotal role in fingerprint normalization and reliable feature extraction. Accurate and efficient extraction of a singular point plays a major role in successful fingerprint recognition and indexing. In this paper, a novel deep learning based architecture is proposed for one shot (end-to-end) singular point detection from an input fingerprint image. The model consists of a Macro-Localization Network and a Micro-Regression Network along with three stacked hourglass as a bottleneck. The proposed model has been tested on three databases viz. FVC2002 DB1_A, FVC2002 DB2_A and FPL30K and has been found to achieve true detection rate of 98.75%, 97.5% and 92.72% respectively, which is better than any other state-of-the-art technique.