 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVRNet: Lightweight Image Restoration for Aerial Images under Low Visibility
Jan 13, 2023Learning to recover clear images from images having a combination of degrading factors is a challenging task. That being said, autonomous surveillance in low visibility conditions caused by high pollution/smoke, poor air quality index, low light, atmospheric scattering, and haze during a blizzard becomes even more important to prevent accidents. It is thus crucial to form a solution that can result in a high-quality image and is efficient enough to be deployed for everyday use. However, the lack of proper datasets available to tackle this task limits the performance of the previous methods proposed. To this end, we generate the LowVis-AFO dataset, containing 3647 paired dark-hazy and clear images. We also introduce a lightweight deep learning model called Low-Visibility Restoration Network (LVRNet). It outperforms previous image restoration methods with low latency, achieving a PSNR value of 25.744 and an SSIM of 0.905, making our approach scalable and ready for practical use. The code and data can be found at https://github.com/Achleshwar/LVRNet.
NFResNet: Multi-scale and U-shaped Networks for Deblurring
Dec 12, 2022



Multi-Scale and U-shaped Networks are widely used in various image restoration problems, including deblurring. Keeping in mind the wide range of applications, we present a comparison of these architectures and their effects on image deblurring. We also introduce a new block called as NFResblock. It consists of a Fast Fourier Transformation layer and a series of modified Non-Linear Activation Free Blocks. Based on these architectures and additions, we introduce NFResnet and NFResnet+, which are modified multi-scale and U-Net architectures, respectively. We also use three different loss functions to train these architectures: Charbonnier Loss, Edge Loss, and Frequency Reconstruction Loss. Extensive experiments on the Deep Video Deblurring dataset, along with ablation studies for each component, have been presented in this paper. The proposed architectures achieve a considerable increase in Peak Signal to Noise (PSNR) ratio and Structural Similarity Index (SSIM) value.
DroneAttention: Sparse Weighted Temporal Attention for Drone-Camera Based Activity Recognition
Dec 07, 2022
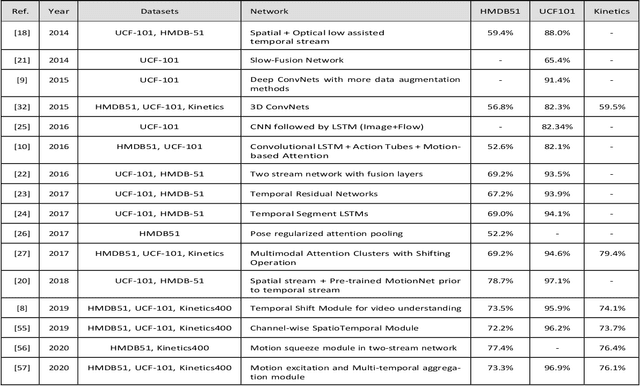
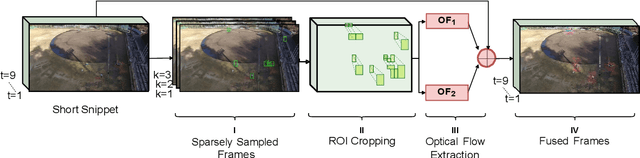
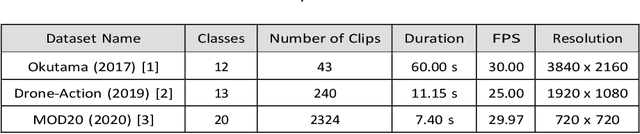
Human activity recognition (HAR) using drone-mounted cameras has attracted considerable interest from the computer vision research community in recent years. A robust and efficient HAR system has a pivotal role in fields like video surveillance, crowd behavior analysis, sports analysis, and human-computer interaction. What makes it challenging are the complex poses, understanding different viewpoints, and the environmental scenarios where the action is taking place. To address such complexities, in this paper, we propose a novel Sparse Weighted Temporal Attention (SWTA) module to utilize sparsely sampled video frames for obtaining global weighted temporal attention. The proposed SWTA is comprised of two parts. First, temporal segment network that sparsely samples a given set of frames. Second, weighted temporal attention, which incorporates a fusion of attention maps derived from optical flow, with raw RGB images. This is followed by a basenet network, which comprises a convolutional neural network (CNN) module along with fully connected layers that provide us with activity recognition. The SWTA network can be used as a plug-in module to the existing deep CNN architectures, for optimizing them to learn temporal information by eliminating the need for a separate temporal stream. It has been evaluated on three publicly available benchmark datasets, namely Okutama, MOD20, and Drone-Action. The proposed model has received an accuracy of 72.76%, 92.56%, and 78.86% on the respective datasets thereby surpassing the previous state-of-the-art performances by a margin of 25.26%, 18.56%, and 2.94%, respectively.
SWTF: Sparse Weighted Temporal Fusion for Drone-Based Activity Recognition
Nov 10, 2022Drone-camera based human activity recognition (HAR) has received significant attention from the computer vision research community in the past few years. A robust and efficient HAR system has a pivotal role in fields like video surveillance, crowd behavior analysis, sports analysis, and human-computer interaction. What makes it challenging are the complex poses, understanding different viewpoints, and the environmental scenarios where the action is taking place. To address such complexities, in this paper, we propose a novel Sparse Weighted Temporal Fusion (SWTF) module to utilize sparsely sampled video frames for obtaining global weighted temporal fusion outcome. The proposed SWTF is divided into two components. First, a temporal segment network that sparsely samples a given set of frames. Second, weighted temporal fusion, that incorporates a fusion of feature maps derived from optical flow, with raw RGB images. This is followed by base-network, which comprises a convolutional neural network module along with fully connected layers that provide us with activity recognition. The SWTF network can be used as a plug-in module to the existing deep CNN architectures, for optimizing them to learn temporal information by eliminating the need for a separate temporal stream. It has been evaluated on three publicly available benchmark datasets, namely Okutama, MOD20, and Drone-Action. The proposed model has received an accuracy of 72.76%, 92.56%, and 78.86% on the respective datasets thereby surpassing the previous state-of-the-art performances by a significant margin.