 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Academic Benchmarks: Critical Analysis and Best Practices for Visual Industrial Anomaly Detection
Mar 30, 2025Anomaly detection (AD) is essential for automating visual inspection in manufacturing. This field of computer vision is rapidly evolving, with increasing attention towards real-world applications. Meanwhile, popular datasets are typically produced in controlled lab environments with artificially created defects, unable to capture the diversity of real production conditions. New methods often fail in production settings, showing significant performance degradation or requiring impractical computational resources. This disconnect between academic results and industrial viability threatens to misdirect visual anomaly detection research. This paper makes three key contributions: (1) we demonstrate the importance of real-world datasets and establish benchmarks using actual production data, (2) we provide a fair comparison of existing SOTA methods across diverse tasks by utilizing metrics that are valuable for practical applications, and (3) we present a comprehensive analysis of recent advancements in this field by discussing important challenges and new perspectives for bridging the academia-industry gap. The code is publicly available at https://github.com/abc-125/viad-benchmark
Instance-Aware Observer Network for Out-of-Distribution Object Segmentation
Jul 20, 2022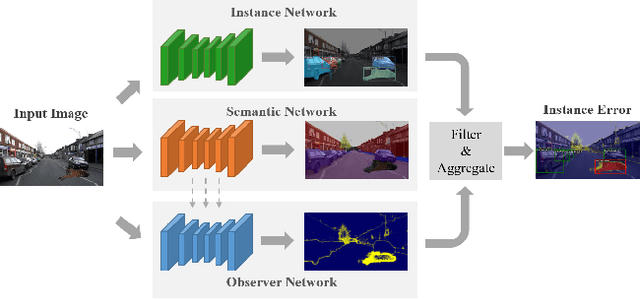
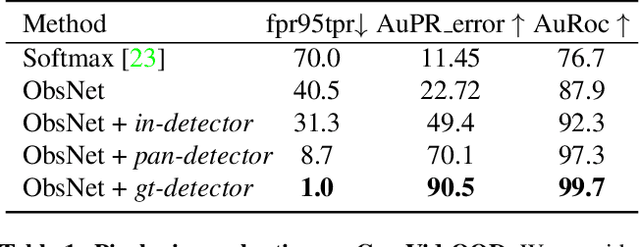

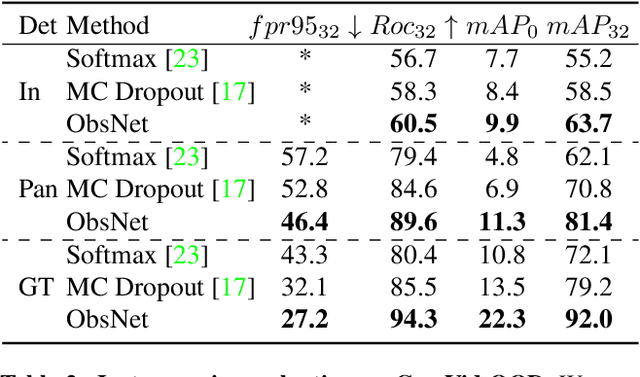
Recent work on Observer Network has shown promising results on Out-Of-Distribution (OOD) detection for semantic segmentation. These methods have difficulty in precisely locating the point of interest in the image, i.e, the anomaly. This limitation is due to the difficulty of fine-grained prediction at the pixel level. To address this issue, we provide instance knowledge to the observer. We extend the approach of ObsNet by harnessing an instance-wise mask prediction. We use an additional, class agnostic, object detector to filter and aggregate observer predictions. Finally, we predict an unique anomaly score for each instance in the image. We show that our proposed method accurately disentangle in-distribution objects from Out-Of-Distribution objects on three datasets.
Triggering Failures: Out-Of-Distribution detection by learning from local adversarial attacks in Semantic Segmentation
Aug 03, 2021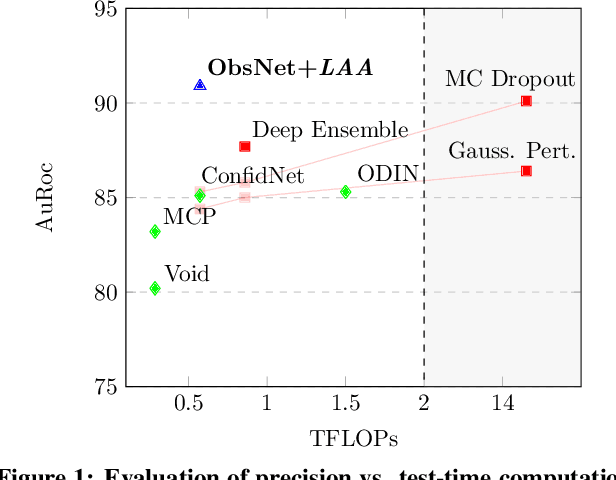

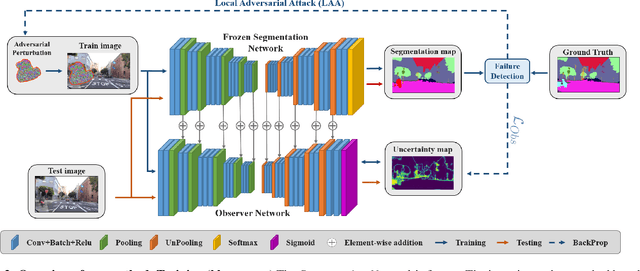
In this paper, we tackle the detection of out-of-distribution (OOD) objects in semantic segmentation. By analyzing the literature, we found that current methods are either accurate or fast but not both which limits their usability in real world applications. To get the best of both aspects, we propose to mitigate the common shortcomings by following four design principles: decoupling the OOD detection from the segmentation task, observing the entire segmentation network instead of just its output, generating training data for the OOD detector by leveraging blind spots in the segmentation network and focusing the generated data on localized regions in the image to simulate OOD objects. Our main contribution is a new OOD detection architecture called ObsNet associated with a dedicated training scheme based on Local Adversarial Attacks (LAA). We validate the soundness of our approach across numerous ablation studies. We also show it obtains top performances both in speed and accuracy when compared to ten recent methods of the literature on three different datasets.
Learning Uncertainty For Safety-Oriented Semantic Segmentation In Autonomous Driving
May 28, 2021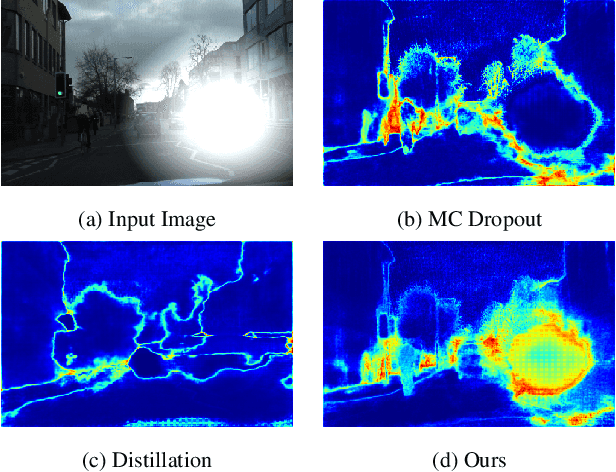

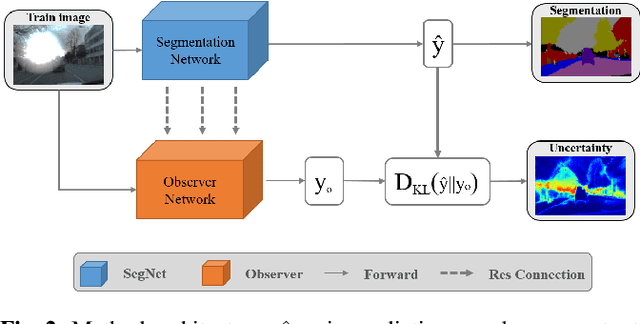

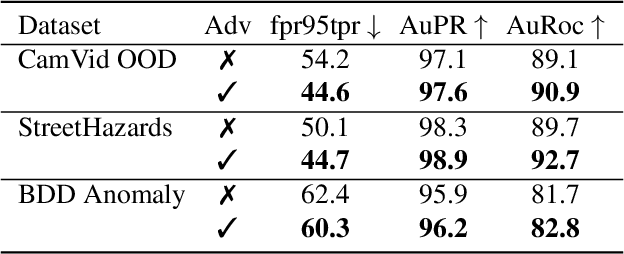
In this paper, we show how uncertainty estimation can be leveraged to enable safety critical image segmentation in autonomous driving, by triggering a fallback behavior if a target accuracy cannot be guaranteed. We introduce a new uncertainty measure based on disagreeing predictions as measured by a dissimilarity function. We propose to estimate this dissimilarity by training a deep neural architecture in parallel to the task-specific network. It allows this observer to be dedicated to the uncertainty estimation, and let the task-specific network make predictions. We propose to use self-supervision to train the observer, which implies that our method does not require additional training data. We show experimentally that our proposed approach is much less computationally intensive at inference time than competing methods (e.g. MCDropout), while delivering better results on safety-oriented evaluation metrics on the CamVid dataset, especially in the case of glare artifacts.
Leveraging Model Interpretability and Stability to increase Model Robustness
Nov 05, 2019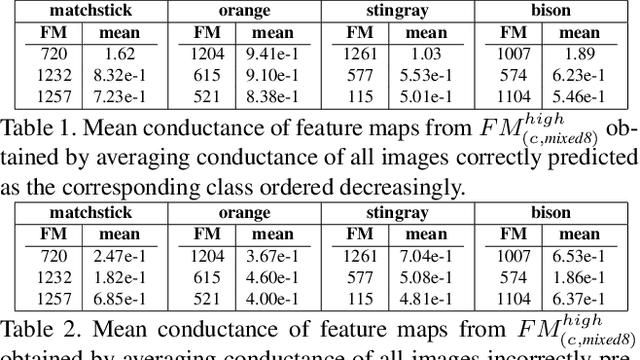
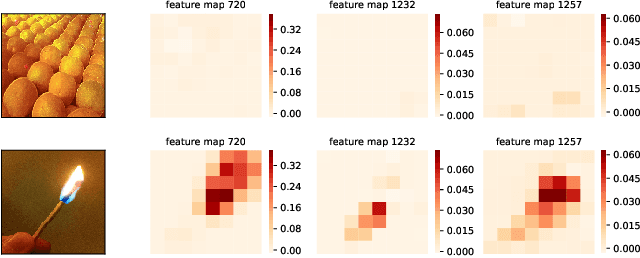
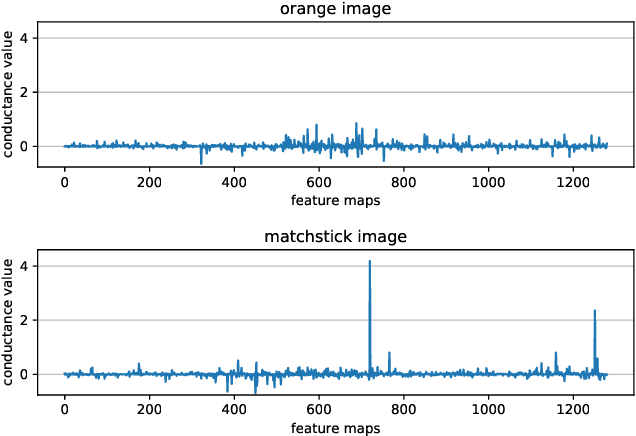
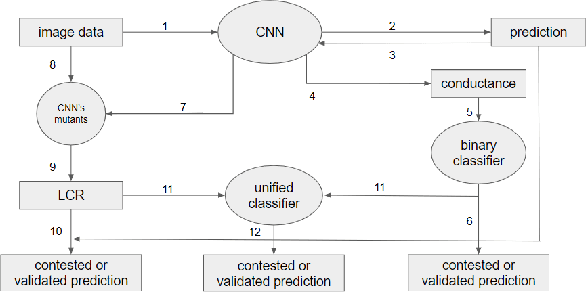
State of the art Deep Neural Networks (DNN) can now achieve above human level accuracy on image classification tasks. However their outstanding performances come along with a complex inference mechanism making them arduously interpretable models. In order to understand the underlying prediction rules of DNNs, Dhamdhere et al. propose an interpretability method to break down a DNN prediction score as sum of its hidden unit contributions, in the form of a metric called conductance. Analyzing conductances of DNN hidden units, we find out there is a difference in how wrong and correct predictions are inferred. We identify distinguishable patterns of hidden unit activations for wrong and correct predictions. We then use an error detector in the form of a binary classifier on top of the DNN to automatically discriminate wrong and correct predictions of the DNN based on their hidden unit activations. Detected wrong predictions are discarded, increasing the model robustness. A different approach to distinguish wrong and correct predictions of DNNs is proposed by Wang et al. whose method is based on the premise that input samples leading a DNN into making wrong predictions are less stable to the DNN weight changes than correctly classified input samples. In our study, we compare both methods and find out by combining them that better detection of wrong predictions can be achieved.