 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Model Interpretability and Stability to increase Model Robustness
Paper and Code
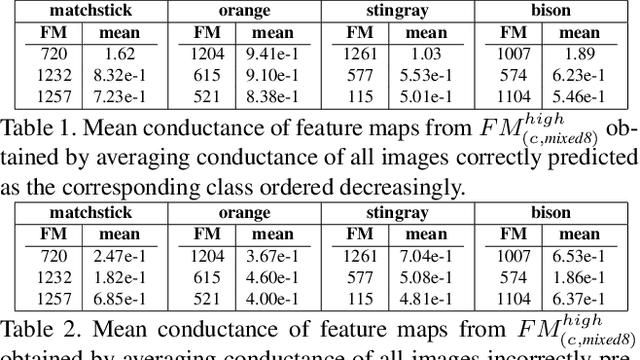
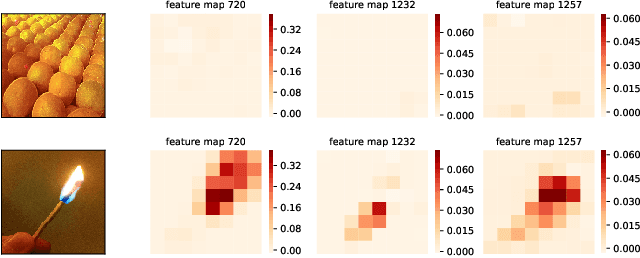
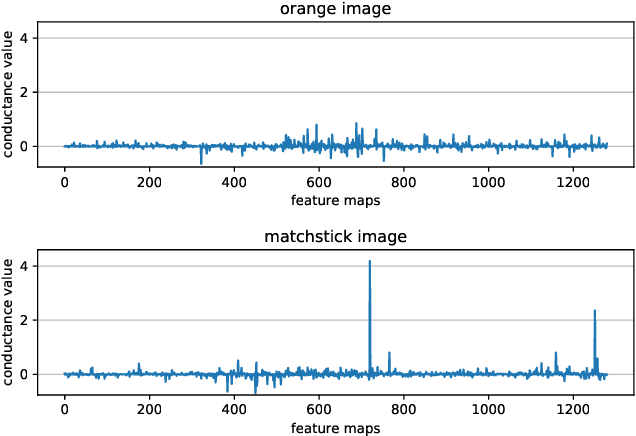
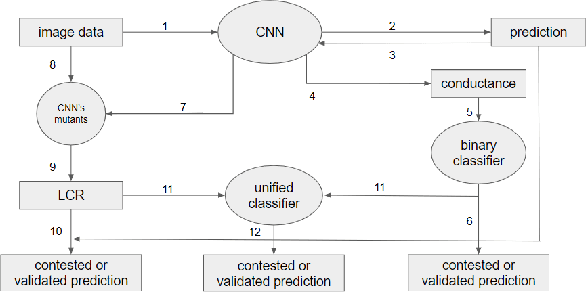
State of the art Deep Neural Networks (DNN) can now achieve above human level accuracy on image classification tasks. However their outstanding performances come along with a complex inference mechanism making them arduously interpretable models. In order to understand the underlying prediction rules of DNNs, Dhamdhere et al. propose an interpretability method to break down a DNN prediction score as sum of its hidden unit contributions, in the form of a metric called conductance. Analyzing conductances of DNN hidden units, we find out there is a difference in how wrong and correct predictions are inferred. We identify distinguishable patterns of hidden unit activations for wrong and correct predictions. We then use an error detector in the form of a binary classifier on top of the DNN to automatically discriminate wrong and correct predictions of the DNN based on their hidden unit activations. Detected wrong predictions are discarded, increasing the model robustness. A different approach to distinguish wrong and correct predictions of DNNs is proposed by Wang et al. whose method is based on the premise that input samples leading a DNN into making wrong predictions are less stable to the DNN weight changes than correctly classified input samples. In our study, we compare both methods and find out by combining them that better detection of wrong predictions can be achieved.