 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManual, Semi or Fully Autonomous Flipper Control? A Framework for Fair Comparison
Mar 18, 2025We investigated the performance of existing semi- and fully autonomous methods for controlling flipper-based skid-steer robots. Our study involves reimplementation of these methods for fair comparison and it introduces a novel semi-autonomous control policy that provides a compelling trade-off among current state-of-the-art approaches. We also propose new metrics for assessing cognitive load and traversal quality and offer a benchmarking interface for generating Quality-Load graphs from recorded data. Our results, presented in a 2D Quality-Load space, demonstrate that the new control policy effectively bridges the gap between autonomous and manual control methods. Additionally, we reveal a surprising fact that fully manual, continuous control of all six degrees of freedom remains highly effective when performed by an experienced operator on a well-designed analog controller from third person view.
Let It Flow: Simultaneous Optimization of 3D Flow and Object Clustering
Apr 12, 2024We study the problem of self-supervised 3D scene flow estimation from real large-scale raw point cloud sequences, which is crucial to various tasks like trajectory prediction or instance segmentation. In the absence of ground truth scene flow labels, contemporary approaches concentrate on deducing optimizing flow across sequential pairs of point clouds by incorporating structure based regularization on flow and object rigidity. The rigid objects are estimated by a variety of 3D spatial clustering methods. While state-of-the-art methods successfully capture overall scene motion using the Neural Prior structure, they encounter challenges in discerning multi-object motions. We identified the structural constraints and the use of large and strict rigid clusters as the main pitfall of the current approaches and we propose a novel clustering approach that allows for combination of overlapping soft clusters as well as non-overlapping rigid clusters representation. Flow is then jointly estimated with progressively growing non-overlapping rigid clusters together with fixed size overlapping soft clusters. We evaluate our method on multiple datasets with LiDAR point clouds, demonstrating the superior performance over the self-supervised baselines reaching new state of the art results. Our method especially excels in resolving flow in complicated dynamic scenes with multiple independently moving objects close to each other which includes pedestrians, cyclists and other vulnerable road users. Our codes will be publicly available.
MonoForce: Self-supervised learning of physics-aware grey-box model for predicting the robot-terrain interaction
Sep 16, 2023



We introduce an explainable, physics-aware, and end-to-end differentiable model which predicts the outcome of robot-terrain interaction from camera images. The proposed MonoForce model consists of a black-box module, which predicts robot-terrain interaction forces from the onboard camera, followed by a white-box module, which transforms these forces through the laws of classical mechanics into the predicted trajectories. As the white-box model is implemented as a differentiable ODE solver, it enables measuring the physical consistency between predicted forces and ground-truth trajectories of the robot. Consequently, it creates a self-supervised loss similar to MonoDepth. To facilitate the reproducibility of the paper, we provide the source code. See the project github for codes and supplementary materials such as videos and data sequences.
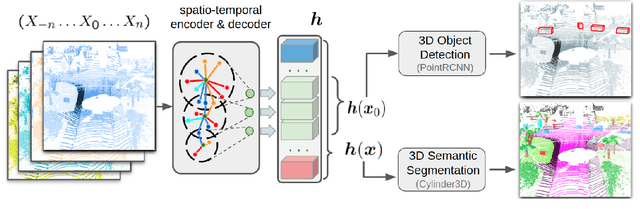
T-UDA: Temporal Unsupervised Domain Adaptation in Sequential Point Clouds
Sep 15, 2023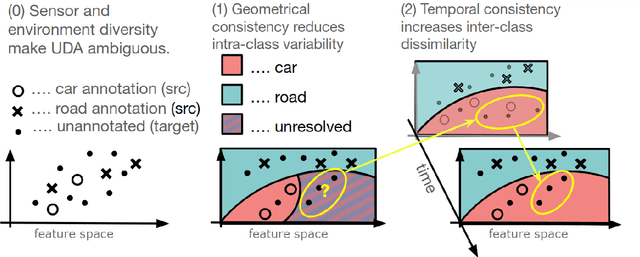
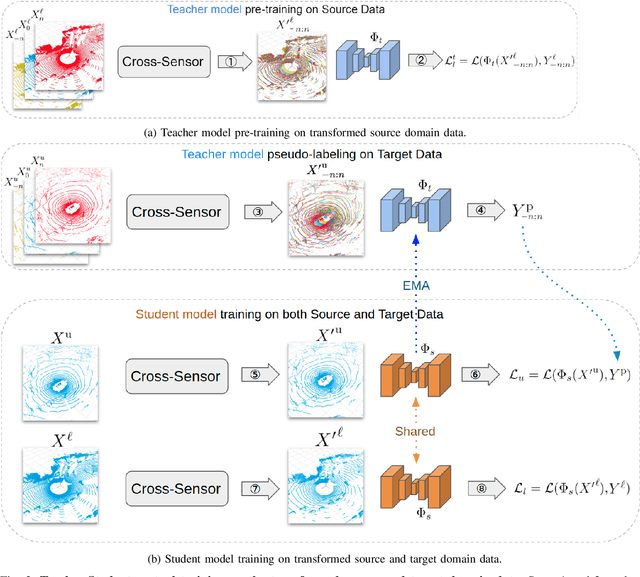
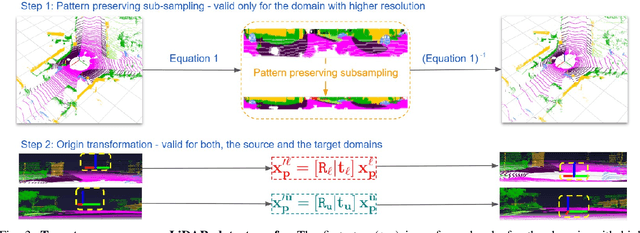
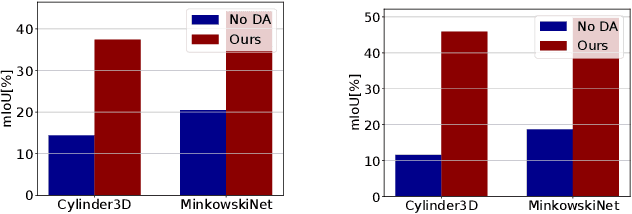
Deep perception models have to reliably cope with an open-world setting of domain shifts induced by different geographic regions, sensor properties, mounting positions, and several other reasons. Since covering all domains with annotated data is technically intractable due to the endless possible variations, researchers focus on unsupervised domain adaptation (UDA) methods that adapt models trained on one (source) domain with annotations available to another (target) domain for which only unannotated data are available. Current predominant methods either leverage semi-supervised approaches, e.g., teacher-student setup, or exploit privileged data, such as other sensor modalities or temporal data consistency. We introduce a novel domain adaptation method that leverages the best of both trends. Our approach combines input data's temporal and cross-sensor geometric consistency with the mean teacher method. Dubbed T-UDA for "temporal UDA", such a combination yields massive performance gains for the task of 3D semantic segmentation of driving scenes. Experiments are conducted on Waymo Open Dataset, nuScenes and SemanticKITTI, for two popular 3D point cloud architectures, Cylinder3D and MinkowskiNet. Our codes are publicly available at https://github.com/ctu-vras/T-UDA.
Teachers in concordance for pseudo-labeling of 3D sequential data
Jul 13, 2022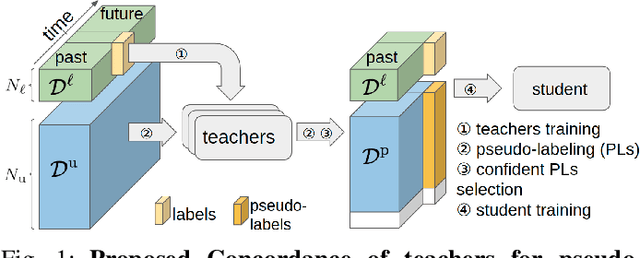

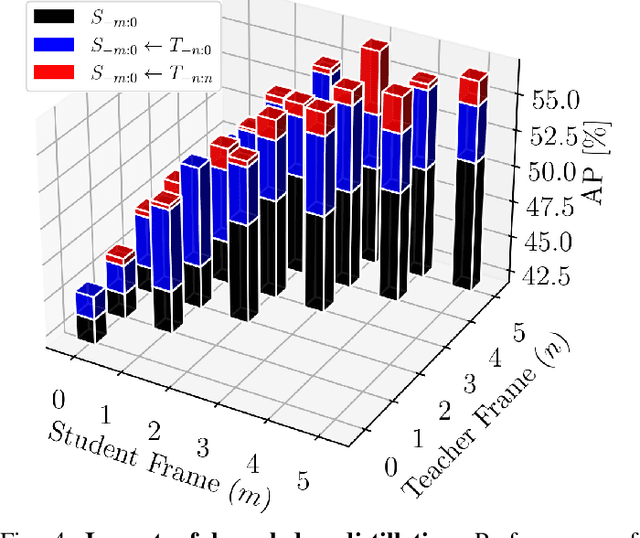
Automatic pseudo-labeling is a powerful tool to tap into large amounts of sequential unlabeled data. It is especially appealing in safety-critical applications of autonomous driving where performance requirements are extreme, datasets large, and manual labeling is very challenging. We propose to leverage the sequentiality of the captures to boost the pseudo-labeling technique in a teacher-student setup via training multiple teachers, each with access to different temporal information. This set of teachers, dubbed Concordance, provides higher quality pseudo-labels for the student training than standard methods. The output of multiple teachers is combined via a novel pseudo-label confidence-guided criterion. Our experimental evaluation focuses on the 3D point cloud domain in urban driving scenarios. We show the performance of our method applied to multiple model architectures with tasks of 3D semantic segmentation and 3D object detection on two benchmark datasets. Our method, using only 20% of manual labels, outperforms some of the fully supervised methods. Special performance boost is achieved for classes rarely appearing in the training data, e.g., bicycles and pedestrians. The implementation of our approach is publicly available at https://github.com/ctu-vras/T-Concord3D.
Real3D-Aug: Point Cloud Augmentation by Placing Real Objects with Occlusion Handling for 3D Detection and Segmentation
Jun 15, 2022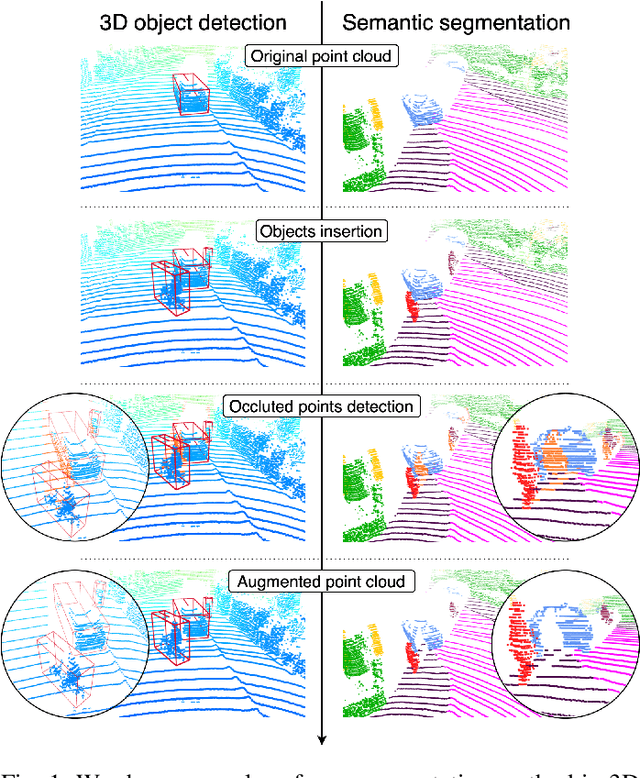
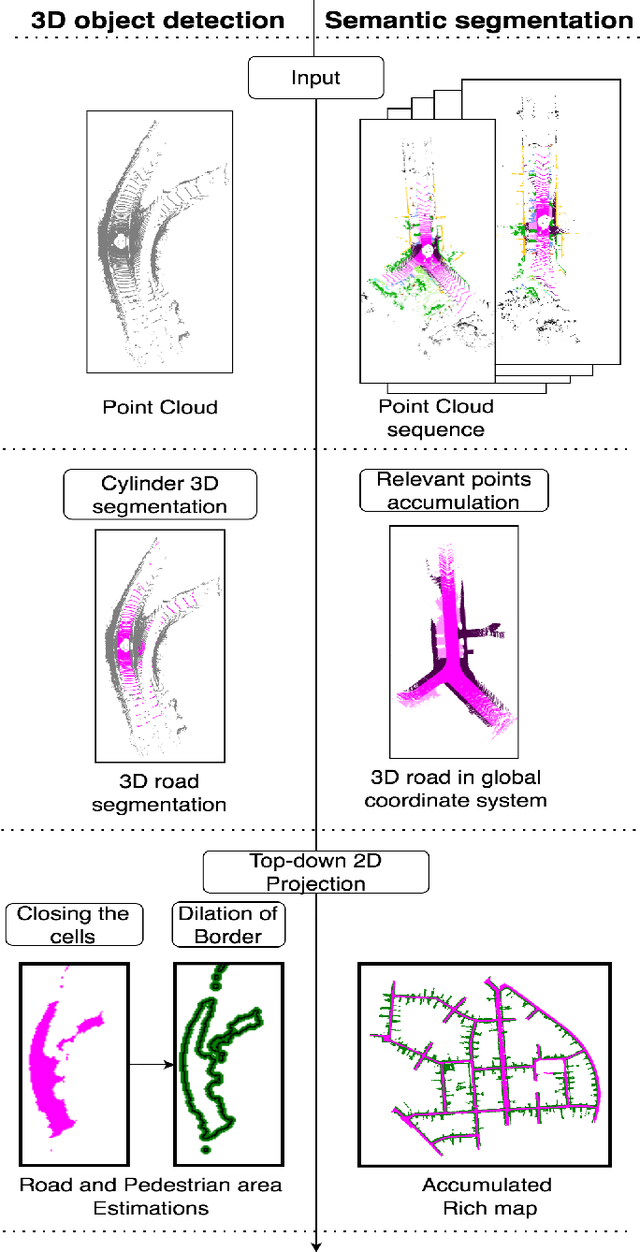
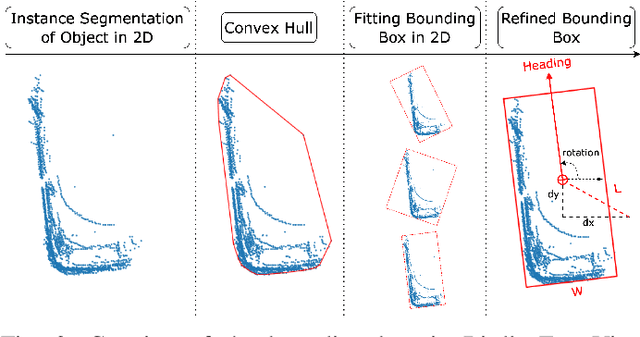
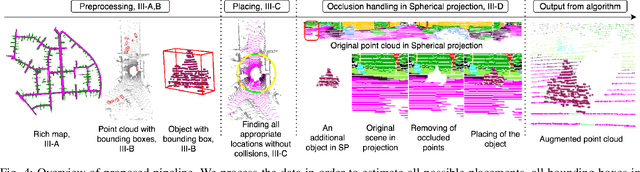
Object detection and semantic segmentation with the 3D lidar point cloud data require expensive annotation. We propose a data augmentation method that takes advantage of already annotated data multiple times. We propose an augmentation framework that reuses real data, automatically finds suitable placements in the scene to be augmented, and handles occlusions explicitly. Due to the usage of the real data, the scan points of newly inserted objects in augmentation sustain the physical characteristics of the lidar, such as intensity and raydrop. The pipeline proves competitive in training top-performing models for 3D object detection and semantic segmentation. The new augmentation provides a significant performance gain in rare and essential classes, notably 6.65% average precision gain for "Hard" pedestrian class in KITTI object detection or 2.14 mean IoU gain in the SemanticKITTI segmentation challenge over the state of the art.
System for multi-robotic exploration of underground environments CTU-CRAS-NORLAB in the DARPA Subterranean Challenge
Oct 12, 2021



We present a field report of CTU-CRAS-NORLAB team from the Subterranean Challenge (SubT) organised by the Defense Advanced Research Projects Agency (DARPA). The contest seeks to advance technologies that would improve the safety and efficiency of search-and-rescue operations in GPS-denied environments. During the contest rounds, teams of mobile robots have to find specific objects while operating in environments with limited radio communication, e.g. mining tunnels, underground stations or natural caverns. We present a heterogeneous exploration robotic system of the CTU-CRAS-NORLAB team, which achieved the third rank at the SubT Tunnel and Urban Circuit rounds and surpassed the performance of all other non-DARPA-funded teams. The field report describes the team's hardware, sensors, algorithms and strategies, and discusses the lessons learned by participating at the DARPA SubT contest.
Data-driven Policy Transfer with Imprecise Perception Simulation
Apr 05, 2018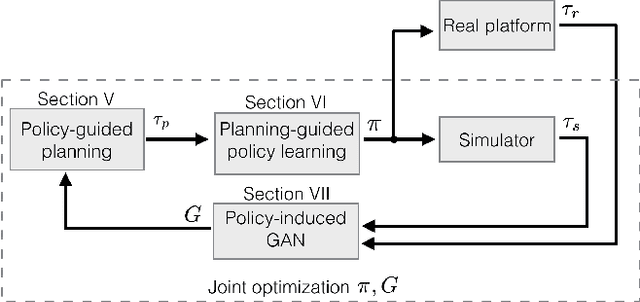

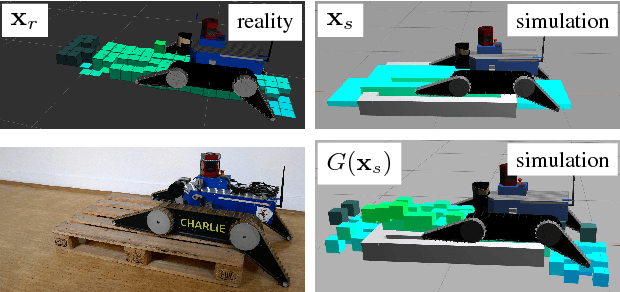
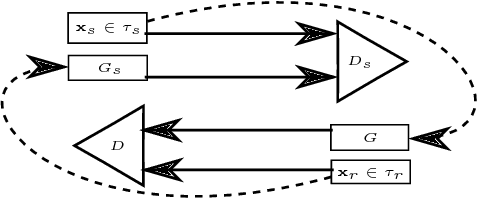
The paper presents a complete pipeline for learning continuous motion control policies for a mobile robot when only a non-differentiable physics simulator of robot-terrain interactions is available. The multi-modal state estimation of the robot is also complex and difficult to simulate, so we simultaneously learn a generative model which refines simulator outputs. We propose a coarse-to-fine learning paradigm, where the coarse motion planning is alternated with imitation learning and policy transfer to the real robot. The policy is jointly optimized with the generative model. We evaluate the method on a real-world platform in a batch of experiments.
Fast Simulation of Vehicles with Non-deformable Tracks
Mar 13, 2017



This paper presents a novel technique that allows for both computationally fast and sufficiently plausible simulation of vehicles with non-deformable tracks. The method is based on an effect we have called Contact Surface Motion. A comparison with several other methods for simulation of tracked vehicle dynamics is presented with the aim to evaluate methods that are available off-the-shelf or with minimum effort in general-purpose robotics simulators. The proposed method is implemented as a plugin for the open-source physics-based simulator Gazebo using the Open Dynamics Engine.
Controlling Robot Morphology from Incomplete Measurements
Dec 08, 2016
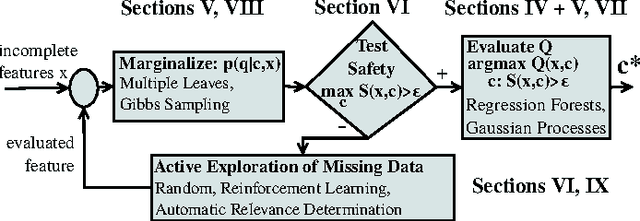


Mobile robots with complex morphology are essential for traversing rough terrains in Urban Search & Rescue missions (USAR). Since teleoperation of the complex morphology causes high cognitive load of the operator, the morphology is controlled autonomously. The autonomous control measures the robot state and surrounding terrain which is usually only partially observable, and thus the data are often incomplete. We marginalize the control over the missing measurements and evaluate an explicit safety condition. If the safety condition is violated, tactile terrain exploration by the body-mounted robotic arm gathers the missing data.