 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoForce: Self-supervised learning of physics-aware grey-box model for predicting the robot-terrain interaction
Sep 16, 2023



We introduce an explainable, physics-aware, and end-to-end differentiable model which predicts the outcome of robot-terrain interaction from camera images. The proposed MonoForce model consists of a black-box module, which predicts robot-terrain interaction forces from the onboard camera, followed by a white-box module, which transforms these forces through the laws of classical mechanics into the predicted trajectories. As the white-box model is implemented as a differentiable ODE solver, it enables measuring the physical consistency between predicted forces and ground-truth trajectories of the robot. Consequently, it creates a self-supervised loss similar to MonoDepth. To facilitate the reproducibility of the paper, we provide the source code. See the project github for codes and supplementary materials such as videos and data sequences.
Self-Supervised Depth Correction of Lidar Measurements from Map Consistency Loss
Mar 02, 2023
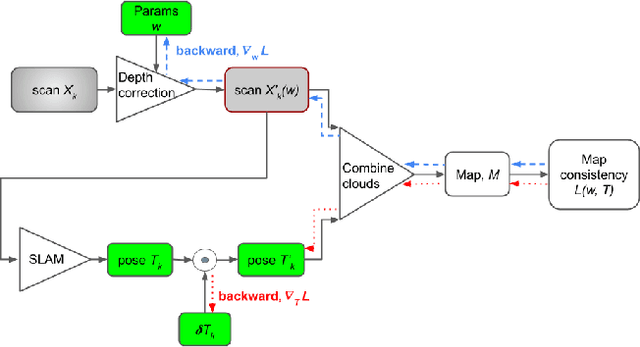


Depth perception is considered an invaluable source of information in the context of 3D mapping and various robotics applications. However, point cloud maps acquired using consumer-level light detection and ranging sensors (lidars) still suffer from bias related to local surface properties such as measuring beam-to-surface incidence angle, distance, texture, reflectance, or illumination conditions. This fact has recently motivated researchers to exploit traditional filters, as well as the deep learning paradigm, in order to suppress the aforementioned depth sensors error while preserving geometric and map consistency details. Despite the effort, depth correction of lidar measurements is still an open challenge mainly due to the lack of clean 3D data that could be used as ground truth. In this paper, we introduce two novel point cloud map consistency losses, which facilitate self-supervised learning on real data of lidar depth correction models. Specifically, the models exploit multiple point cloud measurements of the same scene from different view-points in order to learn to reduce the bias based on the constructed map consistency signal. Complementary to the removal of the bias from the measurements, we demonstrate that the depth correction models help to reduce localization drift. Additionally, we release a data set that contains point cloud data captured in an indoor corridor environment with precise localization and ground truth mapping information.
SwarmCloak: Landing of Two Micro-Quadrotors on Human Hands Using Wearable Tactile Interface Driven by Light Intensity
Jan 31, 2020
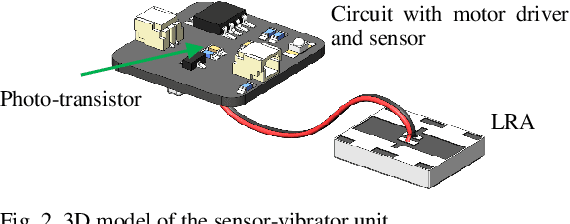
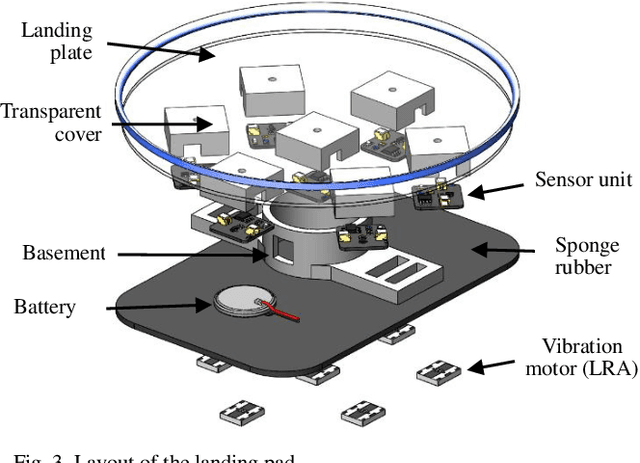
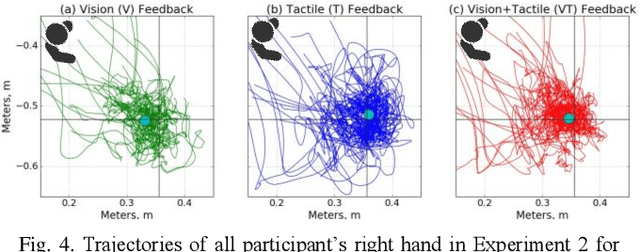
For the human operator, it is often easier and faster to catch a small size quadrotor right in the midair instead of landing it on a surface. However, interaction strategies for such cases have not yet been considered properly, especially when more than one drone has to be landed at the same time. In this paper, we propose a novel interaction strategy to land multiple robots on the human hands using vibrotactile feedback. We developed a wearable tactile display that is activated by the intensity of light emitted from an LED ring on the bottom of the quadcopter. We conducted experiments, where participants were asked to adjust the position of the palm to land one or two vertically-descending drones with different landing speeds, by having only visual feedback, only tactile feedback or visual-tactile feedback. We conducted statistical analysis of the drone landing positions, landing pad and human head trajectories. Two-way ANOVA showed a statistically significant difference between the feedback conditions. Experimental analysis proved that with an increasing number of drones, tactile feedback plays a more important role in accurate hand positioning and operator's convenience. The most precise landing of one and two drones was achieved with the combination of tactile and visual feedback.
SwarmCloak: Landing of a Swarm of Nano-Quadrotors on Human Arms
Nov 22, 2019
We propose a novel system SwarmCloak for landing of a fleet of four flying robots on the human arms using light-sensitive landing pads with vibrotactile feedback. We developed two types of wearable tactile displays with vibromotors which are activated by the light emitted from the LED array at the bottom of quadcopters. In a user study, participants were asked to adjust the position of the arms to land up to two drones, having only visual feedback, only tactile feedback or visual-tactile feedback. The experiment revealed that when the number of drones increases, tactile feedback plays a more important role in accurate landing and operator's convenience. An important finding is that the best landing performance is achieved with the combination of tactile and visual feedback. The proposed technology could have a strong impact on the human-swarm interaction, providing a new level of intuitiveness and engagement into the swarm deployment just right from the skin surface.
SwarmTouch: Guiding a Swarm of Micro-Quadrotors with Impedance Control using a Wearable Tactile Interface
Sep 05, 2019
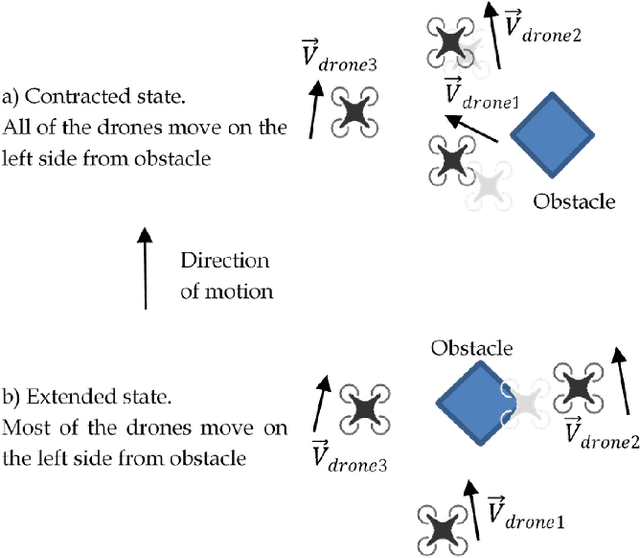
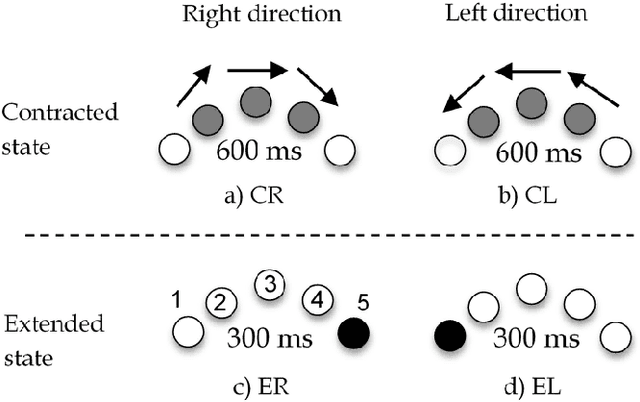
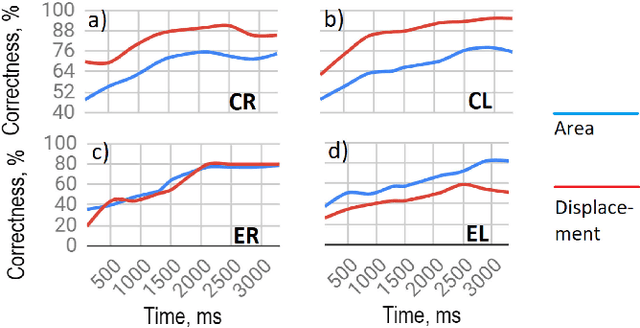
To achieve a smooth and safe guiding of a drone formation by a human operator, we propose a novel interaction strategy for a human-swarm communication which combines impedance control and vibrotactile feedback. The presented approach takes into account the human hand velocity and changes the formation shape and dynamics accordingly using impedance interlinks simulated between quadrotors, which helps to achieve a natural swarm behavior. Several tactile patterns representing static and dynamic parameters of the swarm are proposed. The user feels the state of the swarm at the fingertips and receives valuable information to improve the controllability of the complex formation. A user study revealed the patterns with high recognition rates. A flight experiment demonstrated the possibility to accurately navigate the formation in a cluttered environment using only tactile feedback. Subjects stated that tactile sensation allows guiding the drone formation through obstacles and makes the human-swarm communication more interactive. The proposed technology can potentially have a strong impact on the human-swarm interaction, providing a higher level of awareness during the swarm navigation.
* \c{opyright} 20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works