 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet It Flow: Simultaneous Optimization of 3D Flow and Object Clustering
Apr 12, 2024We study the problem of self-supervised 3D scene flow estimation from real large-scale raw point cloud sequences, which is crucial to various tasks like trajectory prediction or instance segmentation. In the absence of ground truth scene flow labels, contemporary approaches concentrate on deducing optimizing flow across sequential pairs of point clouds by incorporating structure based regularization on flow and object rigidity. The rigid objects are estimated by a variety of 3D spatial clustering methods. While state-of-the-art methods successfully capture overall scene motion using the Neural Prior structure, they encounter challenges in discerning multi-object motions. We identified the structural constraints and the use of large and strict rigid clusters as the main pitfall of the current approaches and we propose a novel clustering approach that allows for combination of overlapping soft clusters as well as non-overlapping rigid clusters representation. Flow is then jointly estimated with progressively growing non-overlapping rigid clusters together with fixed size overlapping soft clusters. We evaluate our method on multiple datasets with LiDAR point clouds, demonstrating the superior performance over the self-supervised baselines reaching new state of the art results. Our method especially excels in resolving flow in complicated dynamic scenes with multiple independently moving objects close to each other which includes pedestrians, cyclists and other vulnerable road users. Our codes will be publicly available.
Regularizing Self-supervised 3D Scene Flows with Surface Awareness and Cyclic Consistency
Dec 12, 2023Learning without supervision how to predict 3D scene flows from point clouds is central to many vision systems. We propose a novel learning framework for this task which improves the necessary regularization. Relying on the assumption that scene elements are mostly rigid, current smoothness losses are built on the definition of ``rigid clusters" in the input point clouds. The definition of these clusters is challenging and has a major impact on the quality of predicted flows. We introduce two new consistency losses that enlarge clusters while preventing them from spreading over distinct objects. In particular, we enforce \emph{temporal} consistency with a forward-backward cyclic loss and \emph{spatial} consistency by considering surface orientation similarity in addition to spatial proximity. The proposed losses are model-independent and can thus be used in a plug-and-play fashion to significantly improve the performance of existing models, as demonstrated on two top-performing ones. We also showcase the effectiveness and generalization capability of our framework on four standard sensor-unique driving datasets, achieving state-of-the-art performance in 3D scene flow estimation. Our codes are available anonymously on \url{https://github.com/vacany/sac-flow}.
Teachers in concordance for pseudo-labeling of 3D sequential data
Jul 13, 2022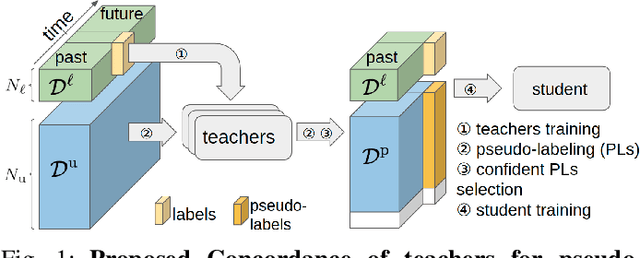
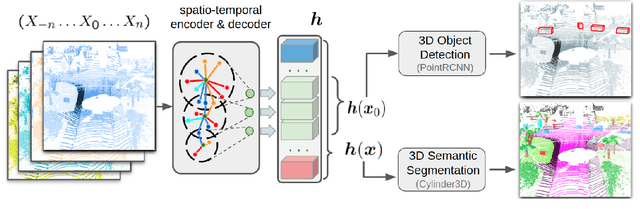

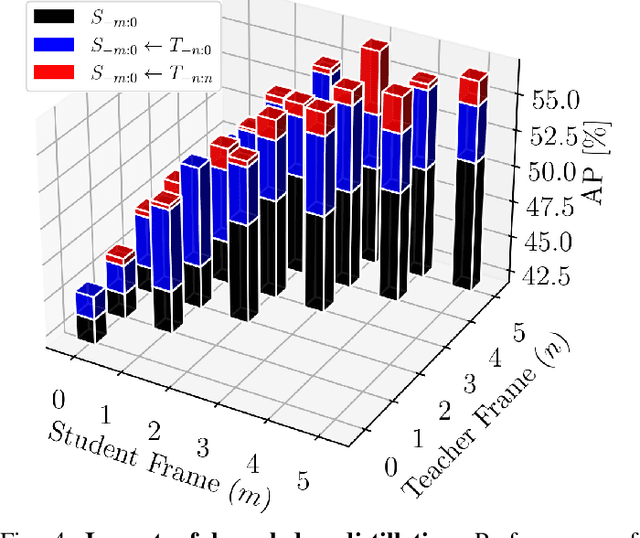
Automatic pseudo-labeling is a powerful tool to tap into large amounts of sequential unlabeled data. It is especially appealing in safety-critical applications of autonomous driving where performance requirements are extreme, datasets large, and manual labeling is very challenging. We propose to leverage the sequentiality of the captures to boost the pseudo-labeling technique in a teacher-student setup via training multiple teachers, each with access to different temporal information. This set of teachers, dubbed Concordance, provides higher quality pseudo-labels for the student training than standard methods. The output of multiple teachers is combined via a novel pseudo-label confidence-guided criterion. Our experimental evaluation focuses on the 3D point cloud domain in urban driving scenarios. We show the performance of our method applied to multiple model architectures with tasks of 3D semantic segmentation and 3D object detection on two benchmark datasets. Our method, using only 20% of manual labels, outperforms some of the fully supervised methods. Special performance boost is achieved for classes rarely appearing in the training data, e.g., bicycles and pedestrians. The implementation of our approach is publicly available at https://github.com/ctu-vras/T-Concord3D.
Real3D-Aug: Point Cloud Augmentation by Placing Real Objects with Occlusion Handling for 3D Detection and Segmentation
Jun 15, 2022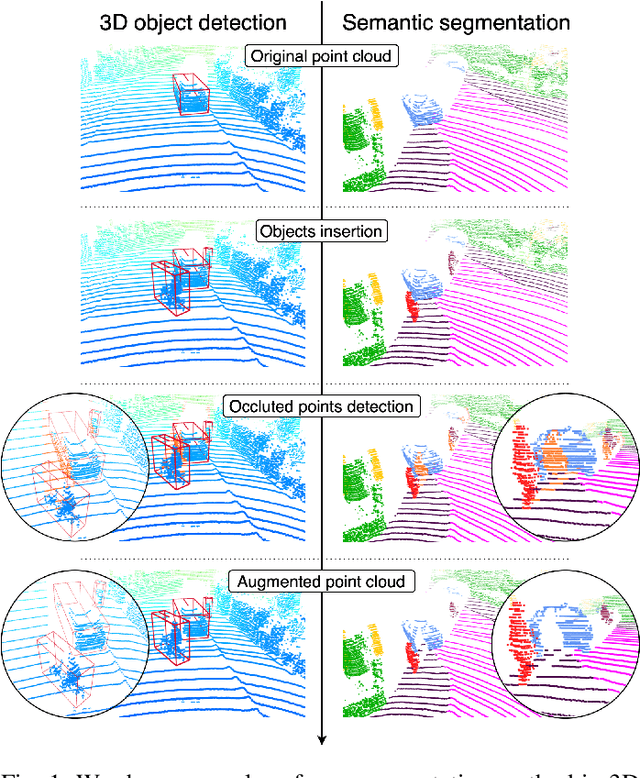
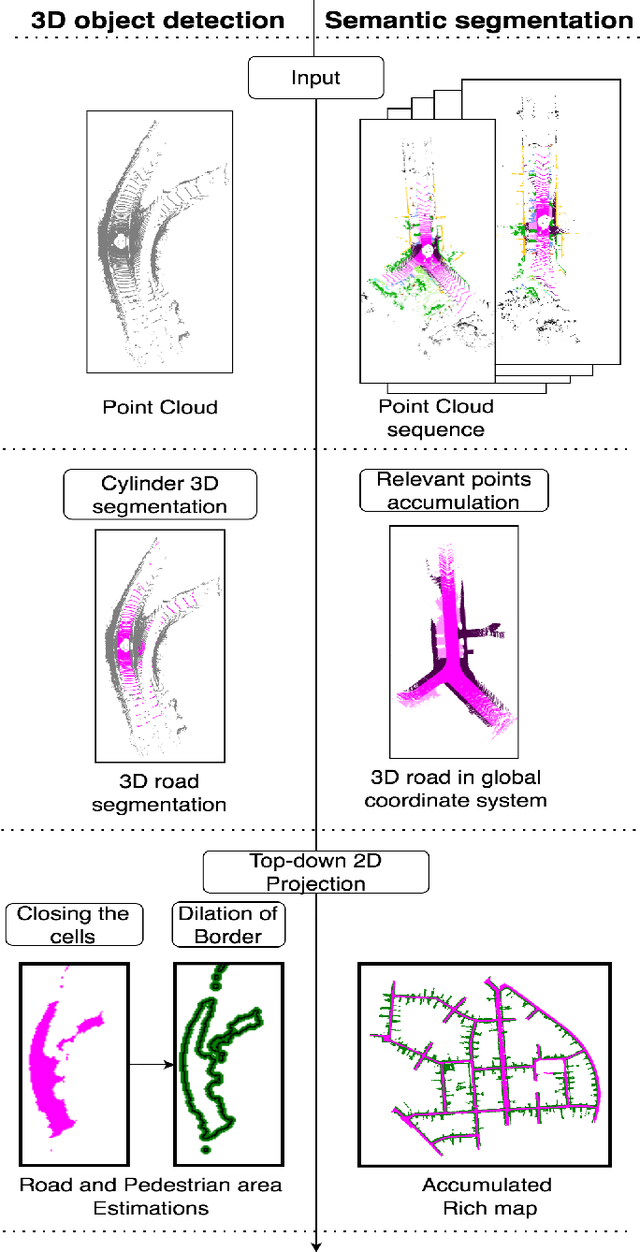
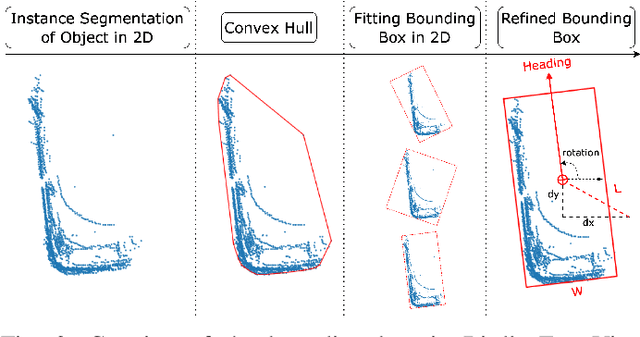
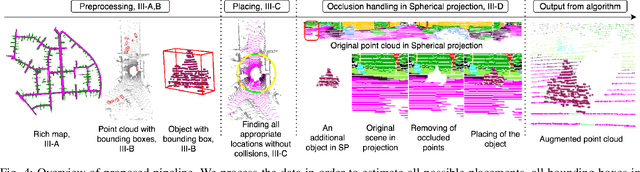
Object detection and semantic segmentation with the 3D lidar point cloud data require expensive annotation. We propose a data augmentation method that takes advantage of already annotated data multiple times. We propose an augmentation framework that reuses real data, automatically finds suitable placements in the scene to be augmented, and handles occlusions explicitly. Due to the usage of the real data, the scan points of newly inserted objects in augmentation sustain the physical characteristics of the lidar, such as intensity and raydrop. The pipeline proves competitive in training top-performing models for 3D object detection and semantic segmentation. The new augmentation provides a significant performance gain in rare and essential classes, notably 6.65% average precision gain for "Hard" pedestrian class in KITTI object detection or 2.14 mean IoU gain in the SemanticKITTI segmentation challenge over the state of the art.