 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Self-supervised 3D Scene Flows with Surface Awareness and Cyclic Consistency
Dec 12, 2023



Learning without supervision how to predict 3D scene flows from point clouds is central to many vision systems. We propose a novel learning framework for this task which improves the necessary regularization. Relying on the assumption that scene elements are mostly rigid, current smoothness losses are built on the definition of ``rigid clusters" in the input point clouds. The definition of these clusters is challenging and has a major impact on the quality of predicted flows. We introduce two new consistency losses that enlarge clusters while preventing them from spreading over distinct objects. In particular, we enforce \emph{temporal} consistency with a forward-backward cyclic loss and \emph{spatial} consistency by considering surface orientation similarity in addition to spatial proximity. The proposed losses are model-independent and can thus be used in a plug-and-play fashion to significantly improve the performance of existing models, as demonstrated on two top-performing ones. We also showcase the effectiveness and generalization capability of our framework on four standard sensor-unique driving datasets, achieving state-of-the-art performance in 3D scene flow estimation. Our codes are available anonymously on \url{https://github.com/vacany/sac-flow}.
UAVs Beneath the Surface: Cooperative Autonomy for Subterranean Search and Rescue in DARPA SubT
Jun 16, 2022

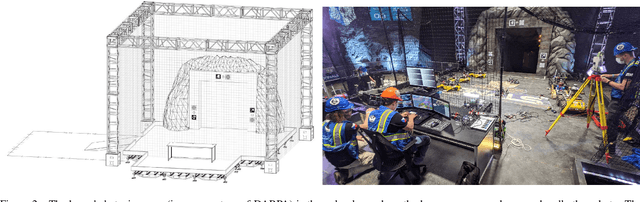

This paper presents a novel approach for autonomous cooperating UAVs in search and rescue operations in subterranean domains with complex topology. The proposed system was ranked second in the Virtual Track of the DARPA SubT Finals as part of the team CTU-CRAS-NORLAB. In contrast to the winning solution that was developed specifically for the Virtual Track, the proposed solution also proved to be a robust system for deployment onboard physical UAVs flying in the extremely harsh and confined environment of the real-world competition. The proposed approach enables fully autonomous and decentralized deployment of a UAV team with seamless simulation-to-world transfer, and proves its advantage over less mobile UGV teams in the flyable space of diverse environments. The main contributions of the paper are present in the mapping and navigation pipelines. The mapping approach employs novel map representations -- SphereMap for efficient risk-aware long-distance planning, FacetMap for surface coverage, and the compressed topological-volumetric LTVMap for allowing multi-robot cooperation under low-bandwidth communication. These representations are used in navigation together with novel methods for visibility-constrained informed search in a general 3D environment with no assumptions about the environment structure, while balancing deep exploration with sensor-coverage exploitation. The proposed solution also includes a visual-perception pipeline for on-board detection and localization of objects of interest in four RGB stream at 5 Hz each without a dedicated GPU. Apart from participation in the DARPA SubT, the performance of the UAV system is supported by extensive experimental verification in diverse environments with both qualitative and quantitative evaluation.
PreCNet: Next Frame Video Prediction Based on Predictive Coding
Apr 30, 2020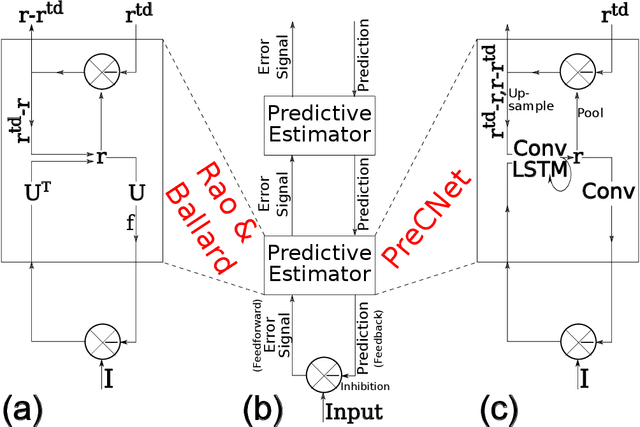
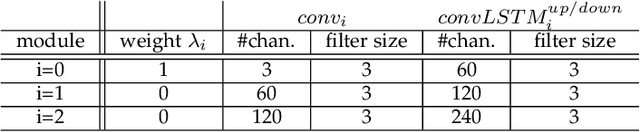
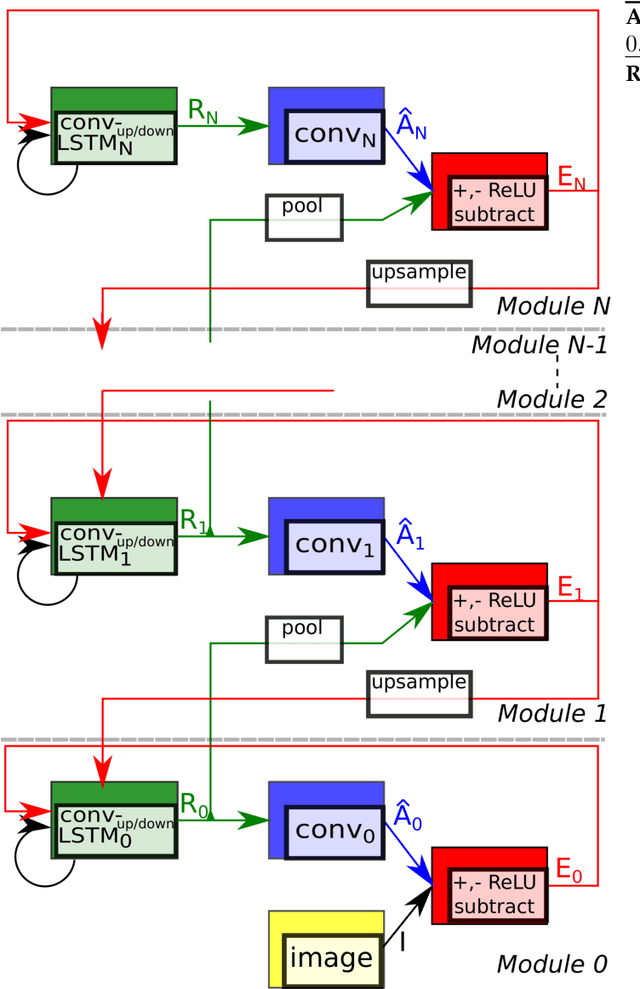
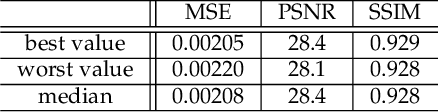
Predictive coding, currently a highly influential theory in neuroscience, has not been widely adopted in machine learning yet. In this work, we transform the seminal model of Rao and Ballard (1999) into a modern deep learning framework while remaining maximally faithful to the original schema. The resulting network we propose (PreCNet) is tested on a widely used next frame video prediction benchmark, which consists of images from an urban environment recorded from a car-mounted camera. On this benchmark (training: 41k images from KITTI dataset; testing: Caltech Pedestrian dataset), we achieve to our knowledge the best performance to date when measured with the Structural Similarity Index (SSIM). On two other common measures, MSE and PSNR, the model ranked third and fourth, respectively. Performance was further improved when a larger training set (2M images from BDD100k), pointing to the limitations of the KITTI training set. This work demonstrates that an architecture carefully based in a neuroscience model, without being explicitly tailored to the task at hand, can exhibit unprecedented performance.
Learning for Active 3D Mapping
Aug 07, 2017
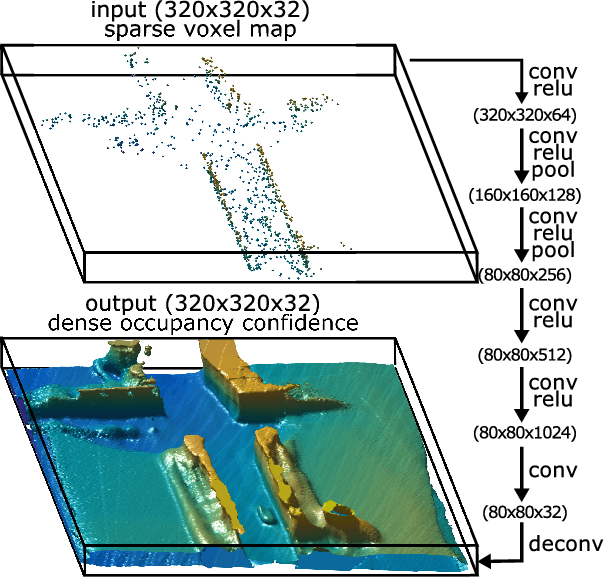
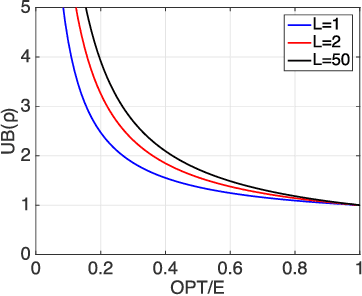
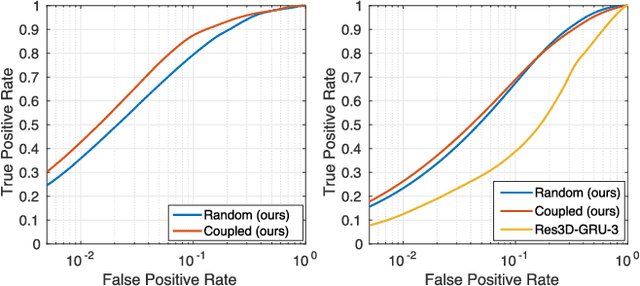
We propose an active 3D mapping method for depth sensors, which allow individual control of depth-measuring rays, such as the newly emerging solid-state lidars. The method simultaneously (i) learns to reconstruct a dense 3D occupancy map from sparse depth measurements, and (ii) optimizes the reactive control of depth-measuring rays. To make the first step towards the online control optimization, we propose a fast prioritized greedy algorithm, which needs to update its cost function in only a small fraction of pos- sible rays. The approximation ratio of the greedy algorithm is derived. An experimental evaluation on the subset of the KITTI dataset demonstrates significant improve- ment in the 3D map accuracy when learning-to-reconstruct from sparse measurements is coupled with the optimization of depth-measuring rays.