 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-grasp deformable object discrimination: the effect of gripper morphology, sensing modalities, and action parameters
Apr 13, 2022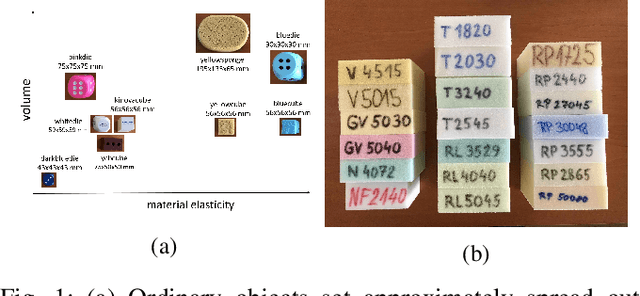

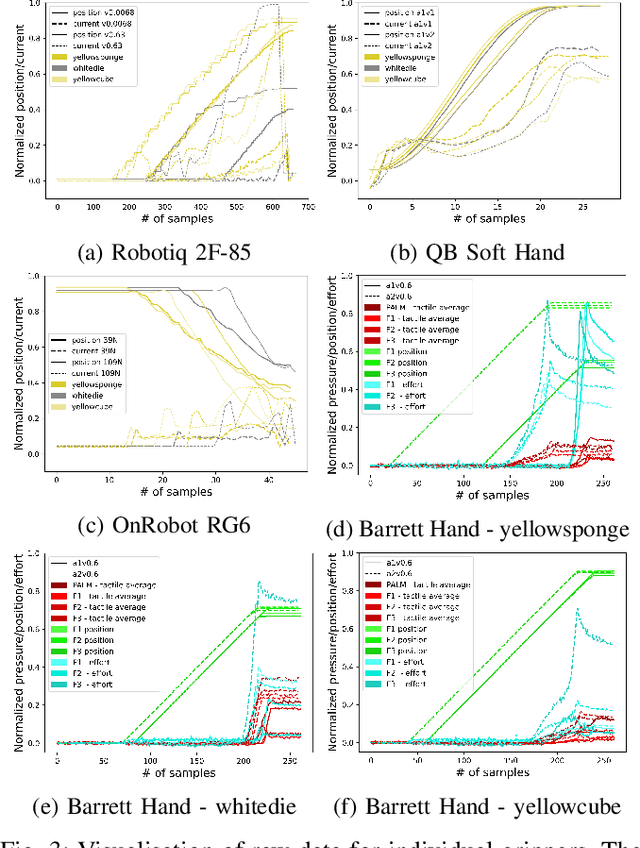
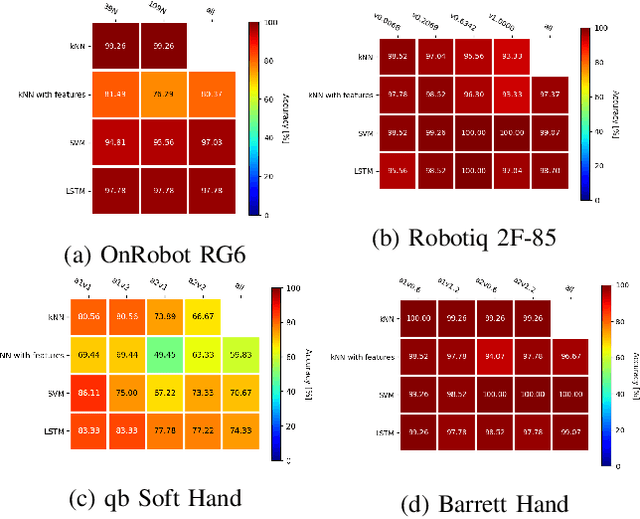
We studied the discrimination of deformable objects by grasping them using 4 different robot hands / grippers: Barrett hand (3 fingers with adjustable configuration, 96 tactile, 8 position, 3 torque sensors), qb SoftHand (5 fingers, 1 motor, position and current feedback), and two industrial type parallel jaw grippers with position and effort feedback (Robotiq 2F-85 and OnRobot RG6). A set of 9 ordinary objects differing in size and stiffness and another highly challenging set of 20 polyurethane foams differing in material properties only was used. We systematically compare the grippers' performance, together with the effects of: (1) type of classifier (k-NN, SVM, LSTM) operating on raw time series or on features, (2) action parameters (grasping configuration and speed of squeezing), (3) contribution of sensory modalities. Classification results are complemented by visualization of the data using PCA. We found: (i) all the grippers but the qb SoftHand could reliably distinguish the ordinary objects set; (ii) Barrett Hand reached around 95% accuracy on the foams; OnRobot RG6 around 75% and Robotiq 2F-85 around 70%; (iii) across all grippers, SVM over features and LSTM on raw time series performed best; (iv) faster compression speeds degrade classification performance; (v) transfer learning between compression speeds worked well for the Barrett Hand only; transfer between grasping configurations is limited; (vi) ablation experiments provided intriguing insights -- sometimes a single sensory channel suffices for discrimination. Overall, the Barrett Hand as a complex and expensive device with rich sensory feedback provided best results, but uncalibrated parallel jaw grippers without tactile sensors can have sufficient performance for single-grasp object discrimination based on position and effort data only. Transfer learning between the different robot hands remains a challenge.
PreCNet: Next Frame Video Prediction Based on Predictive Coding
Apr 30, 2020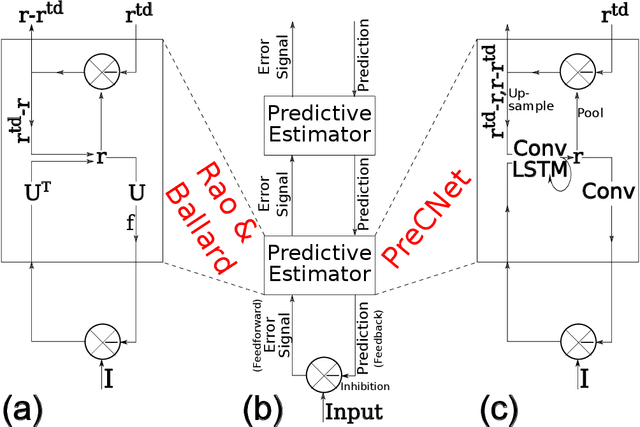
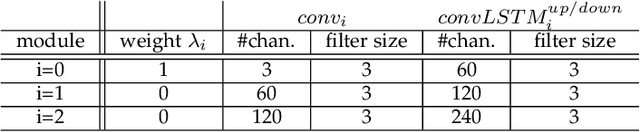
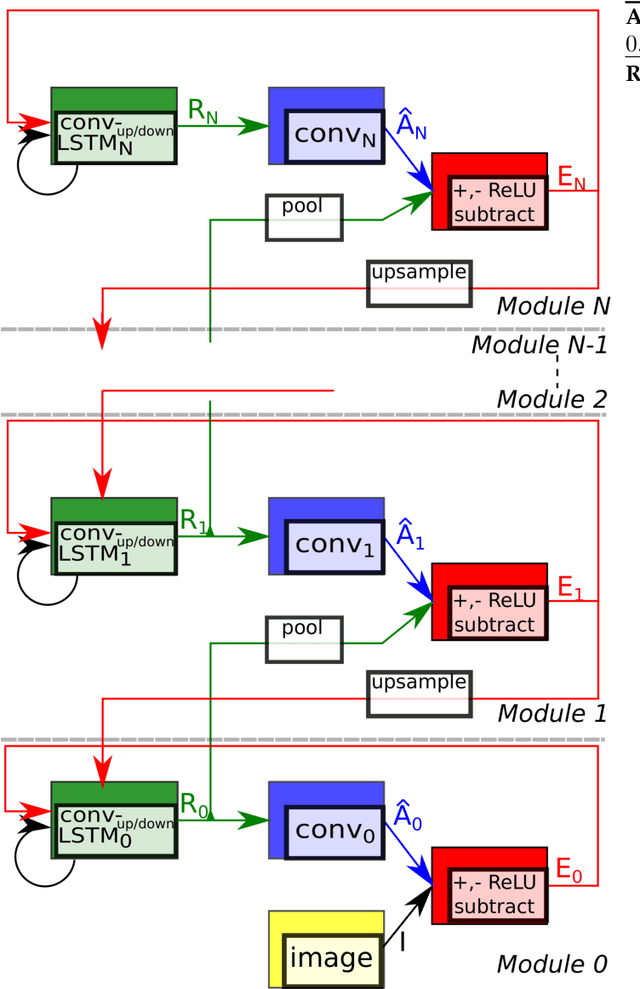
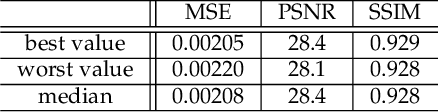
Predictive coding, currently a highly influential theory in neuroscience, has not been widely adopted in machine learning yet. In this work, we transform the seminal model of Rao and Ballard (1999) into a modern deep learning framework while remaining maximally faithful to the original schema. The resulting network we propose (PreCNet) is tested on a widely used next frame video prediction benchmark, which consists of images from an urban environment recorded from a car-mounted camera. On this benchmark (training: 41k images from KITTI dataset; testing: Caltech Pedestrian dataset), we achieve to our knowledge the best performance to date when measured with the Structural Similarity Index (SSIM). On two other common measures, MSE and PSNR, the model ranked third and fourth, respectively. Performance was further improved when a larger training set (2M images from BDD100k), pointing to the limitations of the KITTI training set. This work demonstrates that an architecture carefully based in a neuroscience model, without being explicitly tailored to the task at hand, can exhibit unprecedented performance.
Where is my forearm? Clustering of body parts from simultaneous tactile and linguistic input using sequential mapping
Jun 08, 2017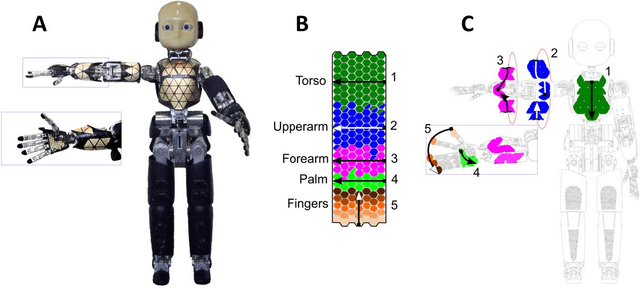
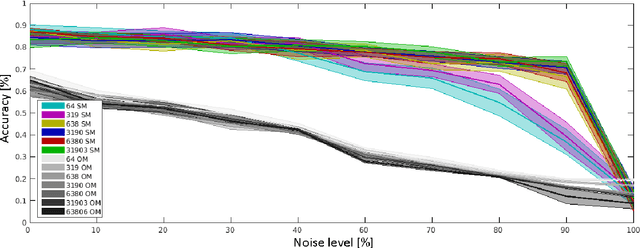
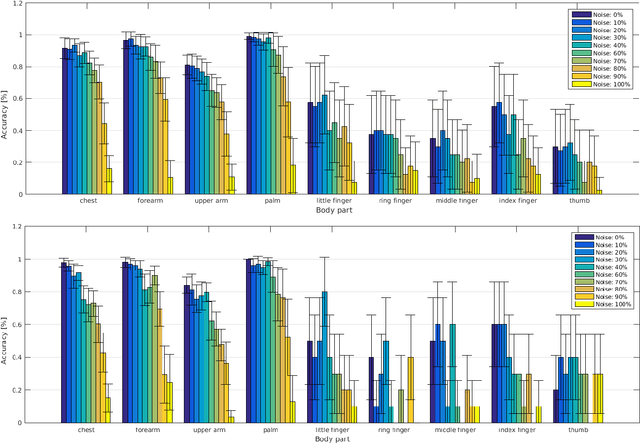
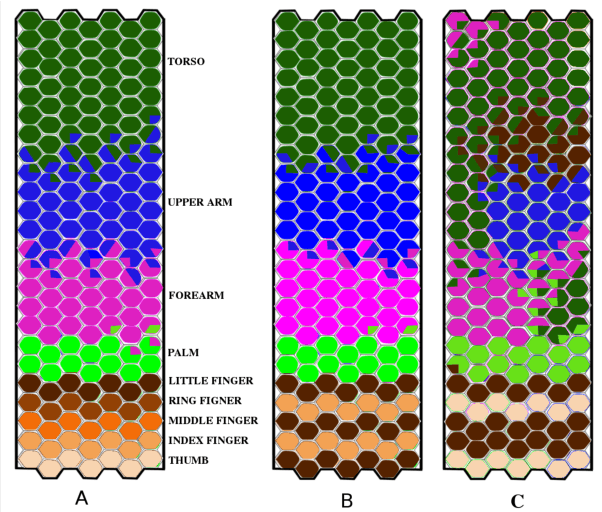
Humans and animals are constantly exposed to a continuous stream of sensory information from different modalities. At the same time, they form more compressed representations like concepts or symbols. In species that use language, this process is further structured by this interaction, where a mapping between the sensorimotor concepts and linguistic elements needs to be established. There is evidence that children might be learning language by simply disambiguating potential meanings based on multiple exposures to utterances in different contexts (cross-situational learning). In existing models, the mapping between modalities is usually found in a single step by directly using frequencies of referent and meaning co-occurrences. In this paper, we present an extension of this one-step mapping and introduce a newly proposed sequential mapping algorithm together with a publicly available Matlab implementation. For demonstration, we have chosen a less typical scenario: instead of learning to associate objects with their names, we focus on body representations. A humanoid robot is receiving tactile stimulations on its body, while at the same time listening to utterances of the body part names (e.g., hand, forearm and torso). With the goal at arriving at the correct "body categories", we demonstrate how a sequential mapping algorithm outperforms one-step mapping. In addition, the effect of data set size and noise in the linguistic input are studied.