 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the legibility of humanoid robot arm movements in a pointing task
Aug 07, 2025Human--robot interaction requires robots whose actions are legible, allowing humans to interpret, predict, and feel safe around them. This study investigates the legibility of humanoid robot arm movements in a pointing task, aiming to understand how humans predict robot intentions from truncated movements and bodily cues. We designed an experiment using the NICO humanoid robot, where participants observed its arm movements towards targets on a touchscreen. Robot cues varied across conditions: gaze, pointing, and pointing with congruent or incongruent gaze. Arm trajectories were stopped at 60\% or 80\% of their full length, and participants predicted the final target. We tested the multimodal superiority and ocular primacy hypotheses, both of which were supported by the experiment.
Bridging Language, Vision and Action: Multimodal VAEs in Robotic Manipulation Tasks
Apr 02, 2024
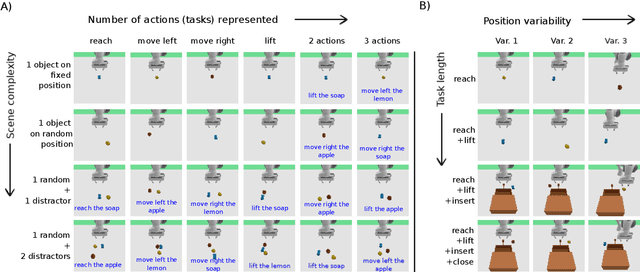

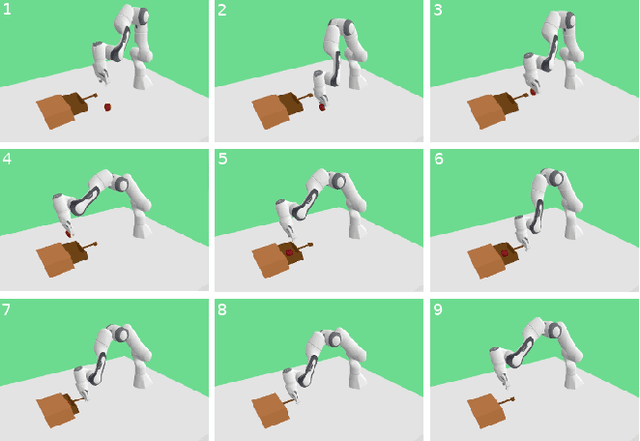
In this work, we focus on unsupervised vision-language-action mapping in the area of robotic manipulation. Recently, multiple approaches employing pre-trained large language and vision models have been proposed for this task. However, they are computationally demanding and require careful fine-tuning of the produced outputs. A more lightweight alternative would be the implementation of multimodal Variational Autoencoders (VAEs) which can extract the latent features of the data and integrate them into a joint representation, as has been demonstrated mostly on image-image or image-text data for the state-of-the-art models. Here we explore whether and how can multimodal VAEs be employed in unsupervised robotic manipulation tasks in a simulated environment. Based on the obtained results, we propose a model-invariant training alternative that improves the models' performance in a simulator by up to 55%. Moreover, we systematically evaluate the challenges raised by the individual tasks such as object or robot position variability, number of distractors or the task length. Our work thus also sheds light on the potential benefits and limitations of using the current multimodal VAEs for unsupervised learning of robotic motion trajectories based on vision and language.
Adaptive Compression of the Latent Space in Variational Autoencoders
Dec 11, 2023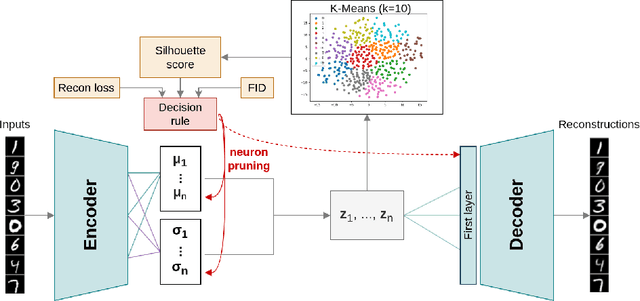
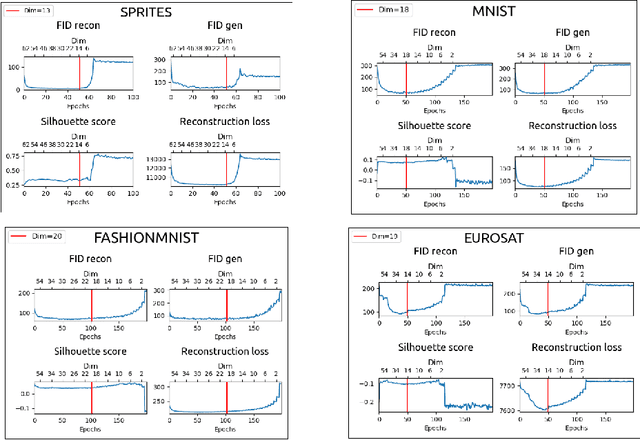
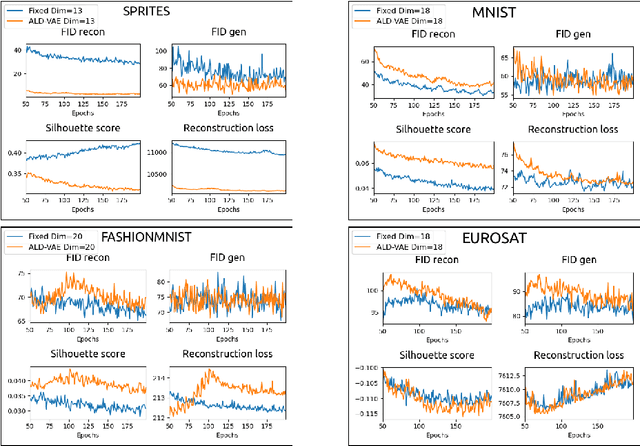
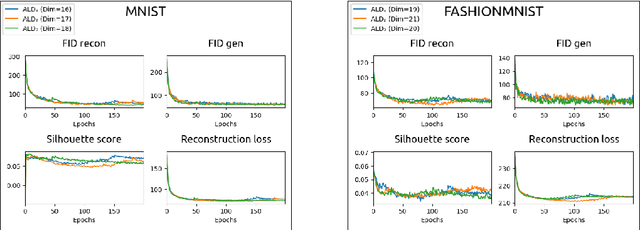
Variational Autoencoders (VAEs) are powerful generative models that have been widely used in various fields, including image and text generation. However, one of the known challenges in using VAEs is the model's sensitivity to its hyperparameters, such as the latent space size. This paper presents a simple extension of VAEs for automatically determining the optimal latent space size during the training process by gradually decreasing the latent size through neuron removal and observing the model performance. The proposed method is compared to traditional hyperparameter grid search and is shown to be significantly faster while still achieving the best optimal dimensionality on four image datasets. Furthermore, we show that the final performance of our method is comparable to training on the optimal latent size from scratch, and might thus serve as a convenient substitute.
How language of interaction affects the user perception of a robot
Oct 23, 2023



Spoken language is the most natural way for a human to communicate with a robot. It may seem intuitive that a robot should communicate with users in their native language. However, it is not clear if a user's perception of a robot is affected by the language of interaction. We investigated this question by conducting a study with twenty-three native Czech participants who were also fluent in English. The participants were tasked with instructing the Pepper robot on where to place objects on a shelf. The robot was controlled remotely using the Wizard-of-Oz technique. We collected data through questionnaires, video recordings, and a post-experiment feedback session. The results of our experiment show that people perceive an English-speaking robot as more intelligent than a Czech-speaking robot (z = 18.00, p-value = 0.02). This finding highlights the influence of language on human-robot interaction. Furthermore, we discuss the feedback obtained from the participants via the post-experiment sessions and its implications for HRI design.
Benchmarking Multimodal Variational Autoencoders: GeBiD Dataset and Toolkit
Sep 07, 2022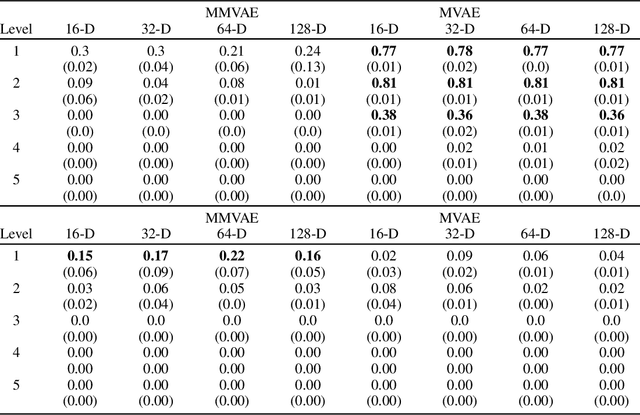

Multimodal Variational Autoencoders (VAEs) have been a subject of intense research in the past years as they can integrate multiple modalities into a joint representation and can thus serve as a promising tool for both data classification and generation. Several approaches toward multimodal VAE learning have been proposed so far, their comparison and evaluation have however been rather inconsistent. One reason is that the models differ at the implementation level, another problem is that the datasets commonly used in these cases were not initially designed for the evaluation of multimodal generative models. This paper addresses both mentioned issues. First, we propose a toolkit for systematic multimodal VAE training and comparison. Second, we present a synthetic bimodal dataset designed for a comprehensive evaluation of the joint generation and cross-generation capabilities. We demonstrate the utility of the dataset by comparing state-of-the-art models.
myGym: Modular Toolkit for Visuomotor Robotic Tasks
Dec 21, 2020



We introduce a novel virtual robotic toolkit myGym, developed for reinforcement learning (RL), intrinsic motivation and imitation learning tasks trained in a 3D simulator. The trained tasks can then be easily transferred to real-world robotic scenarios. The modular structure of the simulator enables users to train and validate their algorithms on a large number of scenarios with various robots, environments and tasks. Compared to existing toolkits (e.g. OpenAI Gym, Roboschool) which are suitable for classical RL, myGym is also prepared for visuomotor (combining vision & movement) unsupervised tasks that require intrinsic motivation, i.e. the robots are able to generate their own goals. There are also collaborative scenarios intended for human-robot interaction. The toolkit provides pretrained visual modules for visuomotor tasks allowing rapid prototyping, and, moreover, users can customize the visual submodules and retrain with their own set of objects. In practice, the user selects the desired environment, robot, objects, task and type of reward as simulation parameters, and the training, visualization and testing themselves are handled automatically. The user can thus fully focus on development of the neural network architecture while controlling the behaviour of the environment using predefined parameters.
Teaching robots to imitate a human with no on-teacher sensors. What are the key challenges?
Jan 24, 2019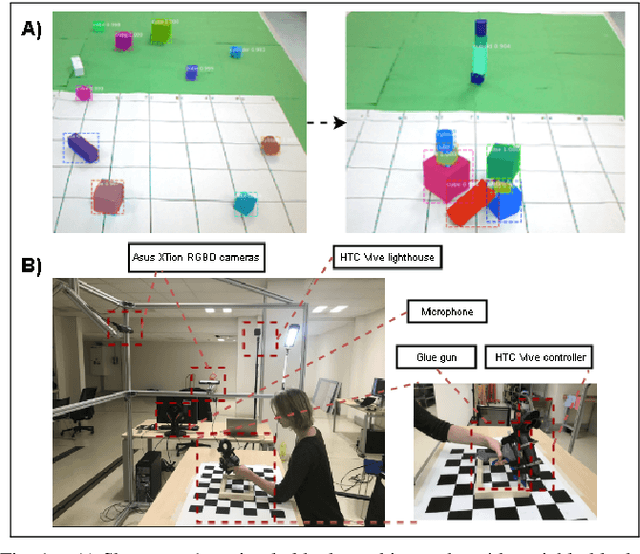



In this paper, we consider the problem of learning object manipulation tasks from human demonstration using RGB or RGB-D cameras. We highlight the key challenges in capturing sufficiently good data with no tracking devices - starting from sensor selection and accurate 6DoF pose estimation to natural language processing. In particular, we focus on two showcases: gluing task with a glue gun and simple block-stacking with variable blocks. Furthermore, we discuss how a linguistic description of the task could help to improve the accuracy of task description. We also present the whole architecture of our transfer of the imitated task to the simulated and real robot environment.
Where is my forearm? Clustering of body parts from simultaneous tactile and linguistic input using sequential mapping
Jun 08, 2017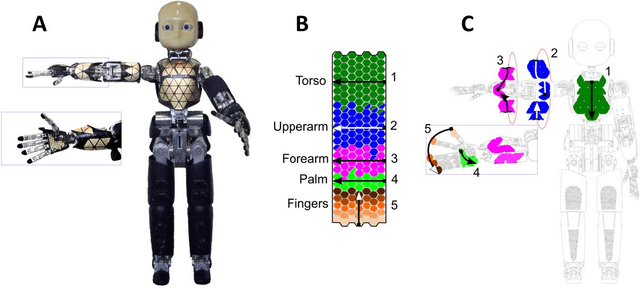
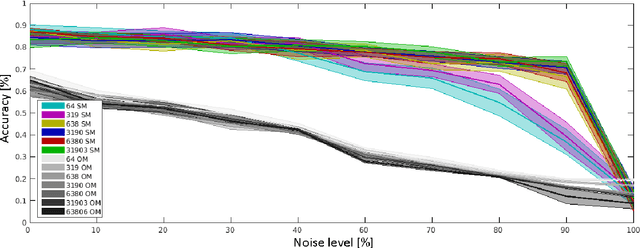
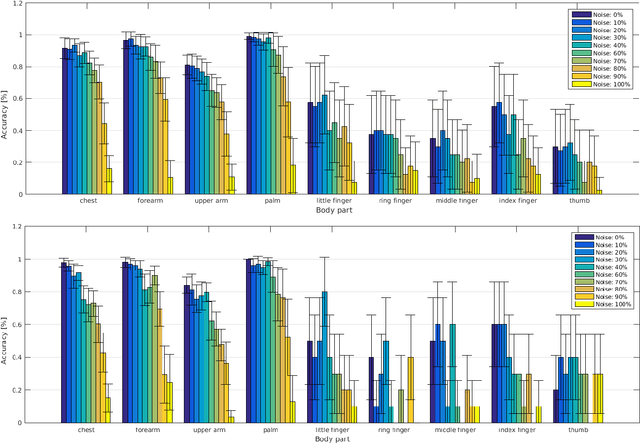
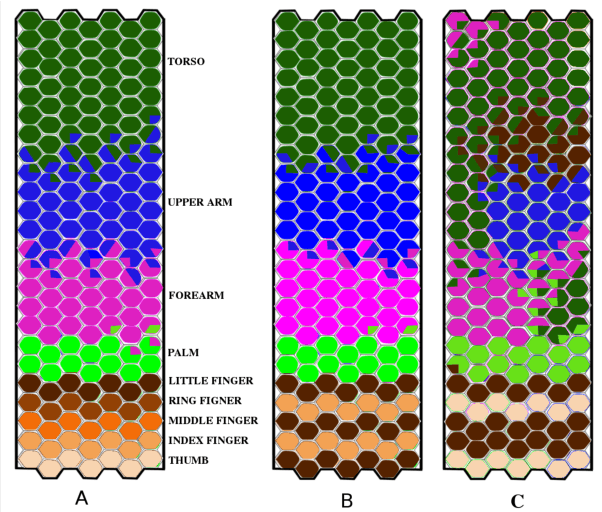
Humans and animals are constantly exposed to a continuous stream of sensory information from different modalities. At the same time, they form more compressed representations like concepts or symbols. In species that use language, this process is further structured by this interaction, where a mapping between the sensorimotor concepts and linguistic elements needs to be established. There is evidence that children might be learning language by simply disambiguating potential meanings based on multiple exposures to utterances in different contexts (cross-situational learning). In existing models, the mapping between modalities is usually found in a single step by directly using frequencies of referent and meaning co-occurrences. In this paper, we present an extension of this one-step mapping and introduce a newly proposed sequential mapping algorithm together with a publicly available Matlab implementation. For demonstration, we have chosen a less typical scenario: instead of learning to associate objects with their names, we focus on body representations. A humanoid robot is receiving tactile stimulations on its body, while at the same time listening to utterances of the body part names (e.g., hand, forearm and torso). With the goal at arriving at the correct "body categories", we demonstrate how a sequential mapping algorithm outperforms one-step mapping. In addition, the effect of data set size and noise in the linguistic input are studied.