 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Language, Vision and Action: Multimodal VAEs in Robotic Manipulation Tasks
Paper and Code

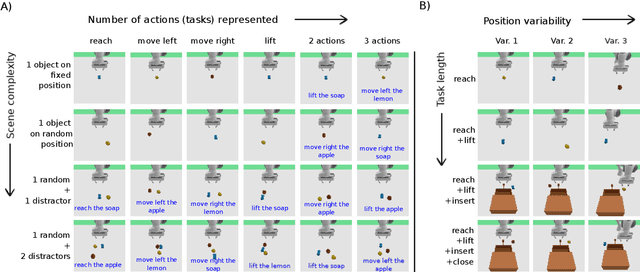

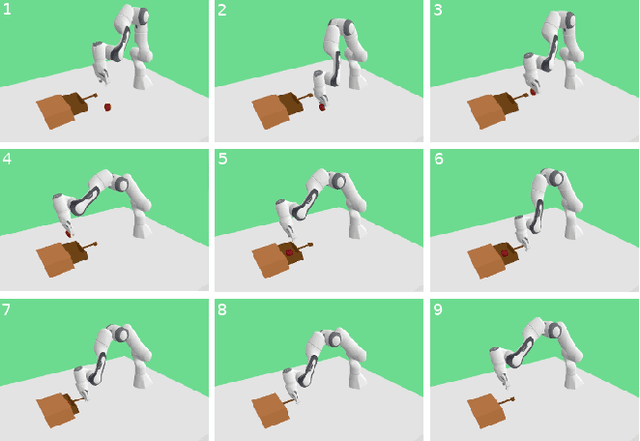
In this work, we focus on unsupervised vision-language-action mapping in the area of robotic manipulation. Recently, multiple approaches employing pre-trained large language and vision models have been proposed for this task. However, they are computationally demanding and require careful fine-tuning of the produced outputs. A more lightweight alternative would be the implementation of multimodal Variational Autoencoders (VAEs) which can extract the latent features of the data and integrate them into a joint representation, as has been demonstrated mostly on image-image or image-text data for the state-of-the-art models. Here we explore whether and how can multimodal VAEs be employed in unsupervised robotic manipulation tasks in a simulated environment. Based on the obtained results, we propose a model-invariant training alternative that improves the models' performance in a simulator by up to 55%. Moreover, we systematically evaluate the challenges raised by the individual tasks such as object or robot position variability, number of distractors or the task length. Our work thus also sheds light on the potential benefits and limitations of using the current multimodal VAEs for unsupervised learning of robotic motion trajectories based on vision and language.