 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell and show: Combining multiple modalities to communicate manipulation tasks to a robot
Apr 02, 2024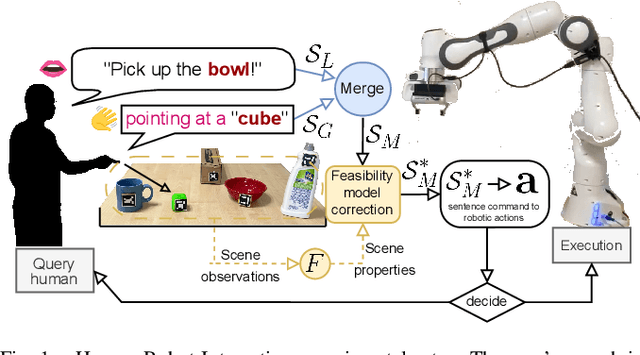
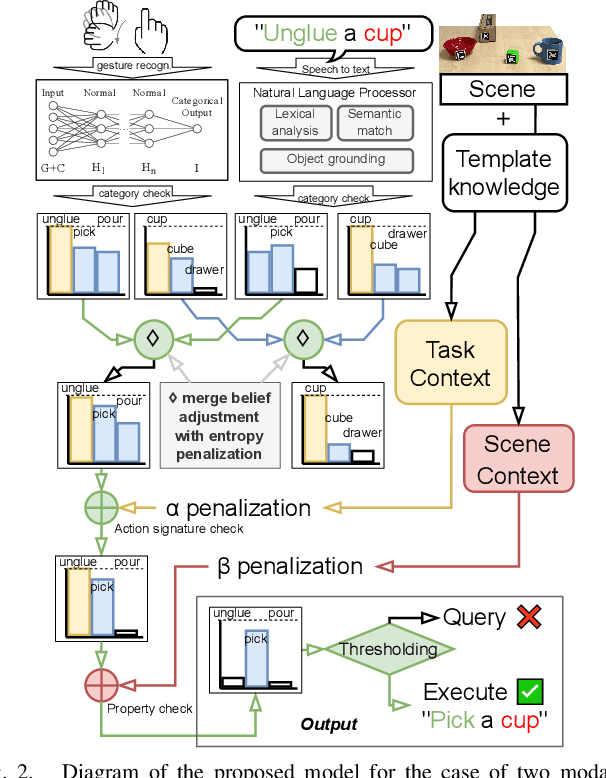
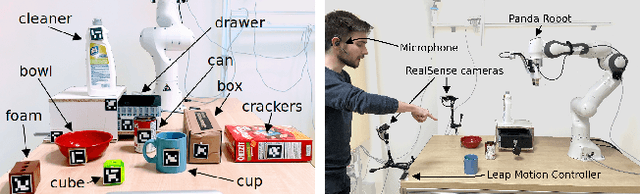
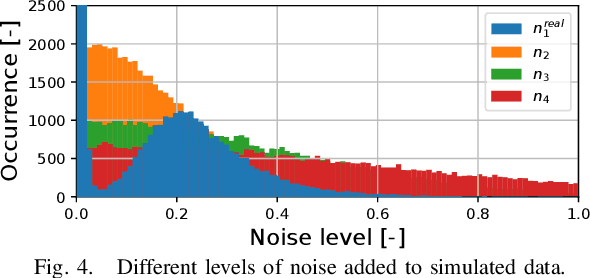
As human-robot collaboration is becoming more widespread, there is a need for a more natural way of communicating with the robot. This includes combining data from several modalities together with the context of the situation and background knowledge. Current approaches to communication typically rely only on a single modality or are often very rigid and not robust to missing, misaligned, or noisy data. In this paper, we propose a novel method that takes inspiration from sensor fusion approaches to combine uncertain information from multiple modalities and enhance it with situational awareness (e.g., considering object properties or the scene setup). We first evaluate the proposed solution on simulated bimodal datasets (gestures and language) and show by several ablation experiments the importance of various components of the system and its robustness to noisy, missing, or misaligned observations. Then we implement and evaluate the model on the real setup. In human-robot interaction, we must also consider whether the selected action is probable enough to be executed or if we should better query humans for clarification. For these purposes, we enhance our model with adaptive entropy-based thresholding that detects the appropriate thresholds for different types of interaction showing similar performance as fine-tuned fixed thresholds.
Imitrob: Imitation Learning Dataset for Training and Evaluating 6D Object Pose Estimators
Sep 19, 2022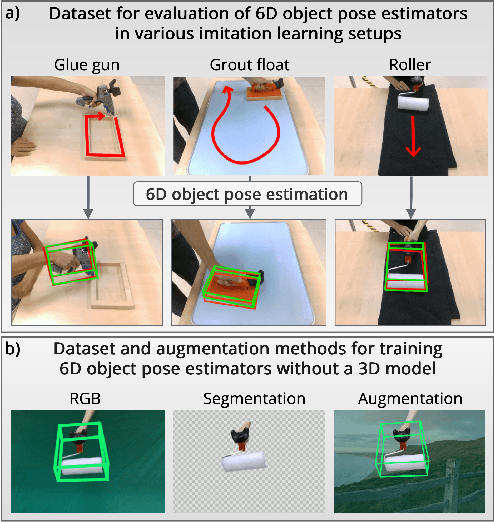


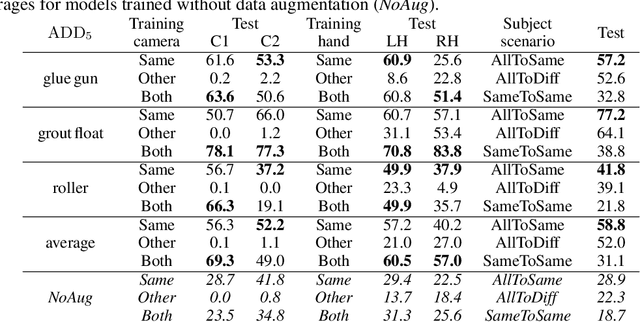
This paper introduces a dataset for training and evaluating methods for 6D pose estimation of hand-held tools in task demonstrations captured by a standard RGB camera. Despite the significant progress of 6D pose estimation methods, their performance is usually limited for heavily occluded objects, which is a common case in imitation learning where the object is typically partially occluded by the manipulating hand. Currently, there is a lack of datasets that would enable the development of robust 6D pose estimation methods for these conditions. To overcome this problem, we collect a new dataset (Imitrob) aimed at 6D pose estimation in imitation learning and other applications where a human holds a tool and performs a task. The dataset contains image sequences of three different tools and six manipulation tasks with two camera viewpoints, four human subjects, and left/right hand. Each image is accompanied by an accurate ground truth measurement of the 6D object pose, obtained by the HTC Vive motion tracking device. The use of the dataset is demonstrated by training and evaluating a recent 6D object pose estimation method (DOPE) in various setups. The dataset and code are publicly available at http://imitrob.ciirc.cvut.cz/imitrobdataset.php.
Teaching robots to imitate a human with no on-teacher sensors. What are the key challenges?
Jan 24, 2019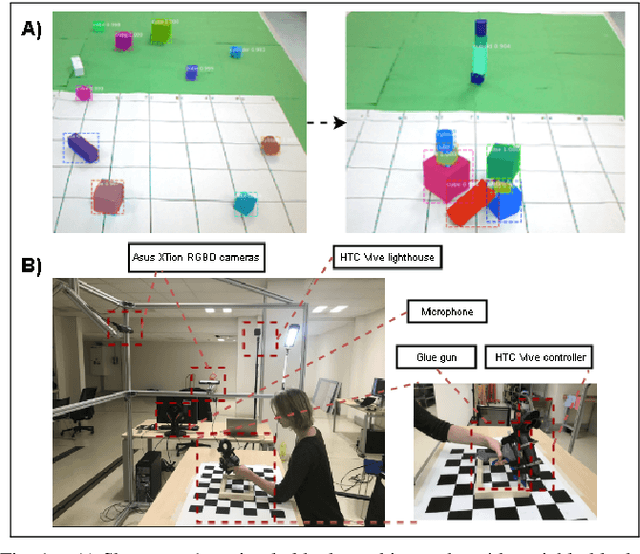



In this paper, we consider the problem of learning object manipulation tasks from human demonstration using RGB or RGB-D cameras. We highlight the key challenges in capturing sufficiently good data with no tracking devices - starting from sensor selection and accurate 6DoF pose estimation to natural language processing. In particular, we focus on two showcases: gluing task with a glue gun and simple block-stacking with variable blocks. Furthermore, we discuss how a linguistic description of the task could help to improve the accuracy of task description. We also present the whole architecture of our transfer of the imitated task to the simulated and real robot environment.