 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell and show: Combining multiple modalities to communicate manipulation tasks to a robot
Paper and Code
Apr 02, 2024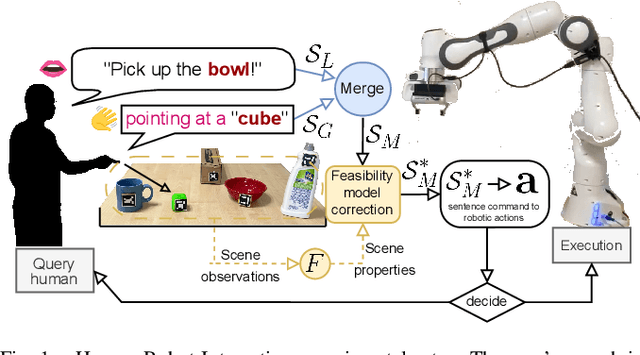
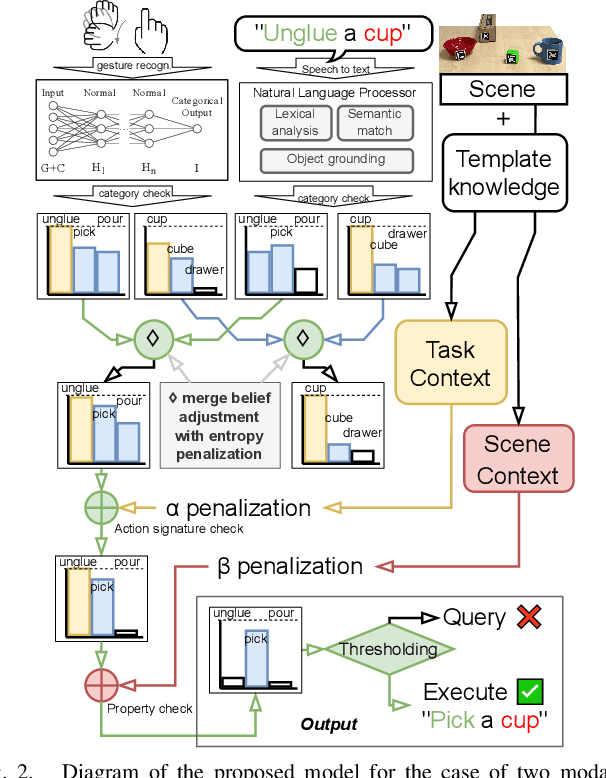
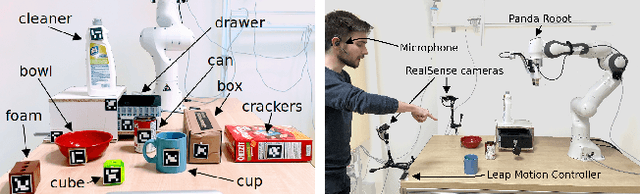
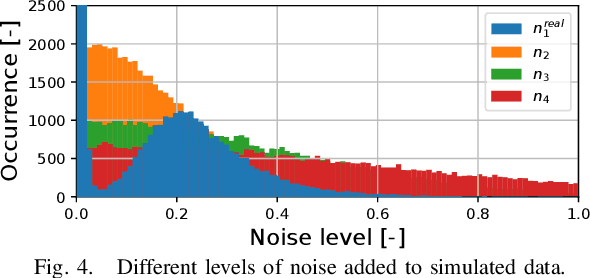
As human-robot collaboration is becoming more widespread, there is a need for a more natural way of communicating with the robot. This includes combining data from several modalities together with the context of the situation and background knowledge. Current approaches to communication typically rely only on a single modality or are often very rigid and not robust to missing, misaligned, or noisy data. In this paper, we propose a novel method that takes inspiration from sensor fusion approaches to combine uncertain information from multiple modalities and enhance it with situational awareness (e.g., considering object properties or the scene setup). We first evaluate the proposed solution on simulated bimodal datasets (gestures and language) and show by several ablation experiments the importance of various components of the system and its robustness to noisy, missing, or misaligned observations. Then we implement and evaluate the model on the real setup. In human-robot interaction, we must also consider whether the selected action is probable enough to be executed or if we should better query humans for clarification. For these purposes, we enhance our model with adaptive entropy-based thresholding that detects the appropriate thresholds for different types of interaction showing similar performance as fine-tuned fixed thresholds.