 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Should We Teach Robots? A Comparison of Kinesthetic, Joystick, and Gesture-Based Teaching
May 27, 2026Instructing robots from demonstrations can be done through different teaching modalities, each with different usability and performance trade-offs. This paper compares kinesthetic guidance, joystick teleoperation, and hand gestures in a user study with eight participants. We evaluate replay success, modified NASA-TLX workload, and common teaching errors across three manipulation tasks. Kinesthetic guidance produced the shortest demonstrations, lowest workload, and highest success on the more orientation-sensitive and contact-rich tasks. Joystick teleoperation performed best on simple peg picking. Hand-gesture teaching, although less reliable overall, performed better than expected and in some cases achieved results comparable to kinesthetic guidance.
See and Switch: Vision-Based Branching for Interactive Robot-Skill Programming
Mar 09, 2026Programming robots by demonstration (PbD) is an intuitive concept, but scaling it to real-world variability remains a challenge for most current teaching frameworks. Conditional task graphs are very expressive and can be defined incrementally, which fits very well with the PbD idea. However, acting using conditional task graphs requires reliable perception-grounded online branch selection. In this paper, we present See & Switch, an interactive teaching-and-execution framework that represents tasks as user-extendable graphs of skill parts connected via decision states (DS), enabling conditional branching during replay. Unlike prior approaches that rely on manual branching or low-dimensional signals (e.g., proprioception), our vision-based Switcher uses eye-in-hand images (high-dimensional) to select among competing successor skill parts and to detect out-of-distribution contexts that require new demonstrations. We integrate kinesthetic teaching, joystick control, and hand gestures via an input-modality-abstraction layer and demonstrate that our proposed method is teaching modality-independent, enabling efficient in-situ recovery demonstrations. The system is validated in experiments on three challenging dexterous manipulation tasks. We evaluate our method under diverse conditions and furthermore conduct user studies with 8 participants. We show that the proposed method reliably performs branch selection and anomaly detection for novice users, achieving 90.7 % and 87.9 % accuracy, respectively, across 576 real-robot rollouts. We provide all code and data required to reproduce our experiments at http://imitrob.ciirc.cvut.cz/publications/seeandswitch.
TransforMerger: Transformer-based Voice-Gesture Fusion for Robust Human-Robot Communication
Apr 02, 2025



As human-robot collaboration advances, natural and flexible communication methods are essential for effective robot control. Traditional methods relying on a single modality or rigid rules struggle with noisy or misaligned data as well as with object descriptions that do not perfectly fit the predefined object names (e.g. 'Pick that red object'). We introduce TransforMerger, a transformer-based reasoning model that infers a structured action command for robotic manipulation based on fused voice and gesture inputs. Our approach merges multimodal data into a single unified sentence, which is then processed by the language model. We employ probabilistic embeddings to handle uncertainty and we integrate contextual scene understanding to resolve ambiguous references (e.g., gestures pointing to multiple objects or vague verbal cues like "this"). We evaluate TransforMerger in simulated and real-world experiments, demonstrating its robustness to noise, misalignment, and missing information. Our results show that TransforMerger outperforms deterministic baselines, especially in scenarios requiring more contextual knowledge, enabling more robust and flexible human-robot communication. Code and datasets are available at: http://imitrob.ciirc.cvut.cz/publications/transformerger.
ILeSiA: Interactive Learning of Situational Awareness from Camera Input
Sep 30, 2024Learning from demonstration is a promising way of teaching robots new skills. However, a central problem when executing acquired skills is to recognize risks and failures. This is essential since the demonstrations usually cover only a few mostly successful cases. Inevitable errors during execution require specific reactions that were not apparent in the demonstrations. In this paper, we focus on teaching the robot situational awareness from an initial skill demonstration via kinesthetic teaching and sparse labeling of autonomous skill executions as safe or risky. At runtime, our system, called ILeSiA, detects risks based on the perceived camera images by encoding the images into a low-dimensional latent space representation and training a classifier based on the encoding and the provided labels. In this way, ILeSiA boosts the confidence and safety with which robotic skills can be executed. Our experiments demonstrate that classifiers, trained with only a small amount of user-provided data, can successfully detect numerous risks. The system is flexible because the risk cases are defined by labeling data. This also means that labels can be added as soon as risks are identified by a human supervisor. We provide all code and data required to reproduce our experiments at imitrob.ciirc.cvut.cz/publications/ilesia.
Tell and show: Combining multiple modalities to communicate manipulation tasks to a robot
Apr 02, 2024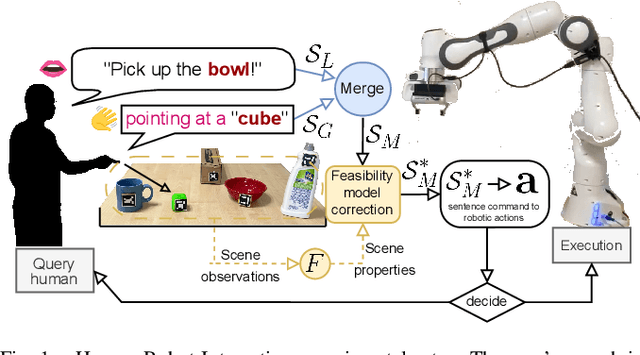
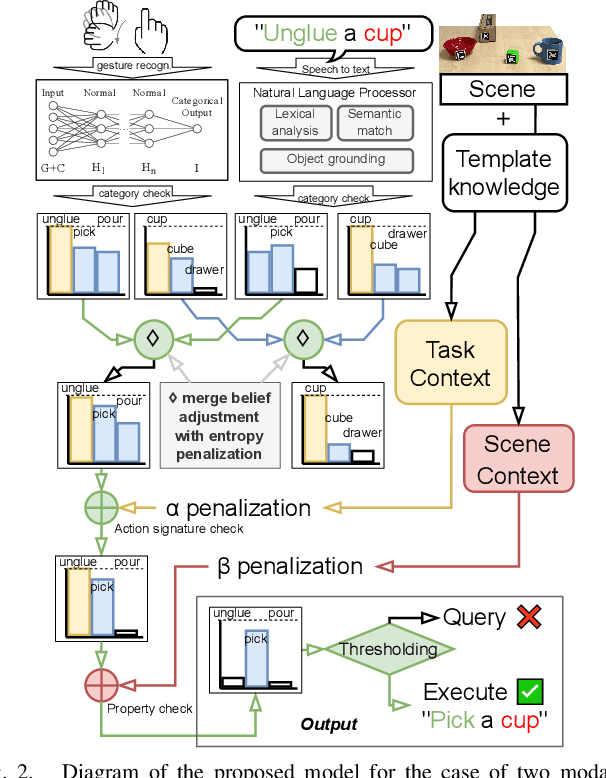
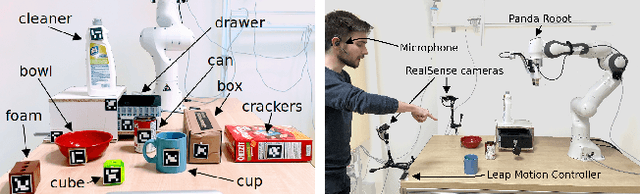
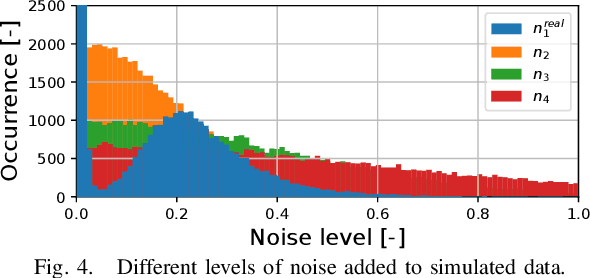
As human-robot collaboration is becoming more widespread, there is a need for a more natural way of communicating with the robot. This includes combining data from several modalities together with the context of the situation and background knowledge. Current approaches to communication typically rely only on a single modality or are often very rigid and not robust to missing, misaligned, or noisy data. In this paper, we propose a novel method that takes inspiration from sensor fusion approaches to combine uncertain information from multiple modalities and enhance it with situational awareness (e.g., considering object properties or the scene setup). We first evaluate the proposed solution on simulated bimodal datasets (gestures and language) and show by several ablation experiments the importance of various components of the system and its robustness to noisy, missing, or misaligned observations. Then we implement and evaluate the model on the real setup. In human-robot interaction, we must also consider whether the selected action is probable enough to be executed or if we should better query humans for clarification. For these purposes, we enhance our model with adaptive entropy-based thresholding that detects the appropriate thresholds for different types of interaction showing similar performance as fine-tuned fixed thresholds.
Communicating human intent to a robotic companion by multi-type gesture sentences
Mar 08, 2023


Human-Robot collaboration in home and industrial workspaces is on the rise. However, the communication between robots and humans is a bottleneck. Although people use a combination of different types of gestures to complement speech, only a few robotic systems utilize gestures for communication. In this paper, we propose a gesture pseudo-language and show how multiple types of gestures can be combined to express human intent to a robot (i.e., expressing both the desired action and its parameters - e.g., pointing to an object and showing that the object should be emptied into a bowl). The demonstrated gestures and the perceived table-top scene (object poses detected by CosyPose) are processed in real-time) to extract the human's intent. We utilize behavior trees to generate reactive robot behavior that handles various possible states of the world (e.g., a drawer has to be opened before an object is placed into it) and recovers from errors (e.g., when the scene changes). Furthermore, our system enables switching between direct teleoperation of the end-effector and high-level operation using the proposed gesture sentences. The system is evaluated on increasingly complex tasks using a real 7-DoF Franka Emika Panda manipulator. Controlling the robot via action gestures lowered the execution time by up to 60%, compared to direct teleoperation.
Context-aware robot control using gesture episodes
Jan 24, 2023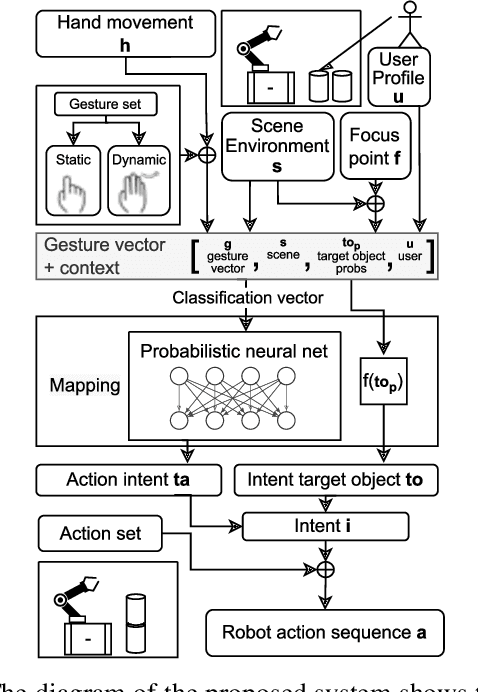
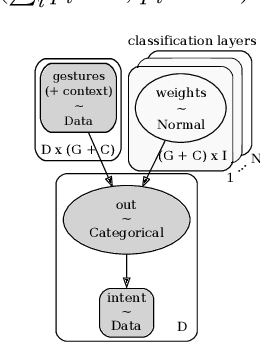
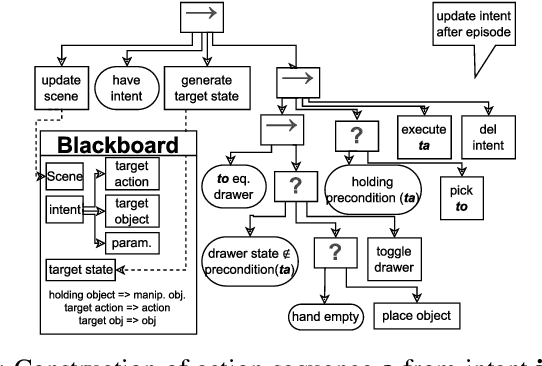
Collaborative robots became a popular tool for increasing productivity in partly automated manufacturing plants. Intuitive robot teaching methods are required to quickly and flexibly adapt the robot programs to new tasks. Gestures have an essential role in human communication. However, in human-robot-interaction scenarios, gesture-based user interfaces are so far used rarely, and if they employ a one-to-one mapping of gestures to robot control variables. In this paper, we propose a method that infers the user's intent based on gesture episodes, the context of the situation, and common sense. The approach is evaluated in a simulated table-top manipulation setting. We conduct deterministic experiments with simulated users and show that the system can even handle personal preferences of each user.