 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA machine learning framework for uncovering stochastic nonlinear dynamics from noisy data
Apr 07, 2026Modeling real-world systems requires accounting for noise - whether it arises from unpredictable fluctuations in financial markets, irregular rhythms in biological systems, or environmental variability in ecosystems. While the behavior of such systems can often be described by stochastic differential equations, a central challenge is understanding how noise influences the inference of system parameters and dynamics from data. Traditional symbolic regression methods can uncover governing equations but typically ignore uncertainty. Conversely, Gaussian processes provide principled uncertainty quantification but offer little insight into the underlying dynamics. In this work, we bridge this gap with a hybrid symbolic regression-probabilistic machine learning framework that recovers the symbolic form of the governing equations while simultaneously inferring uncertainty in the system parameters. The framework combines deep symbolic regression with Gaussian process-based maximum likelihood estimation to separately model the deterministic dynamics and the noise structure, without requiring prior assumptions about their functional forms. We verify the approach on numerical benchmarks, including harmonic, Duffing, and van der Pol oscillators, and validate it on an experimental system of coupled biological oscillators exhibiting synchronization, where the algorithm successfully identifies both the symbolic and stochastic components. The framework is data-efficient, requiring as few as 100-1000 data points, and robust to noise - demonstrating its broad potential in domains where uncertainty is intrinsic and both the structure and variability of dynamical systems must be understood.
MUKCa: Accurate and Affordable Cobot Calibration Without External Measurement Devices
Mar 16, 2025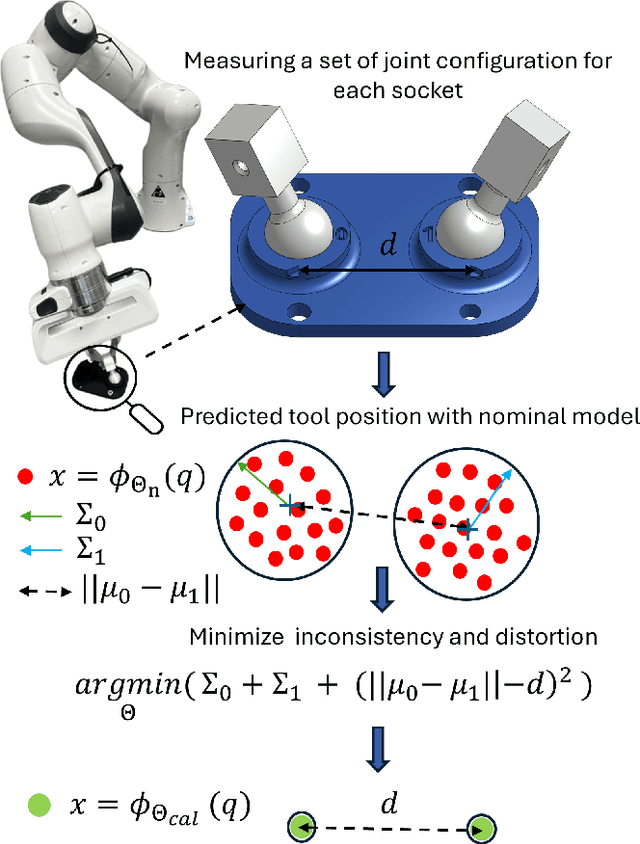

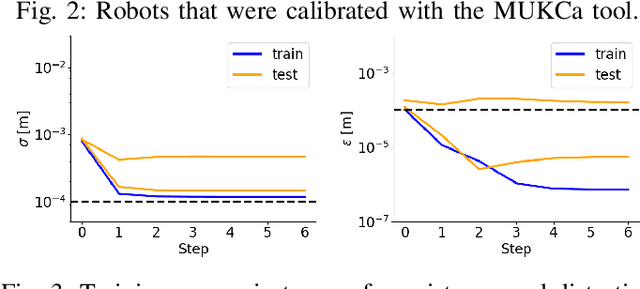
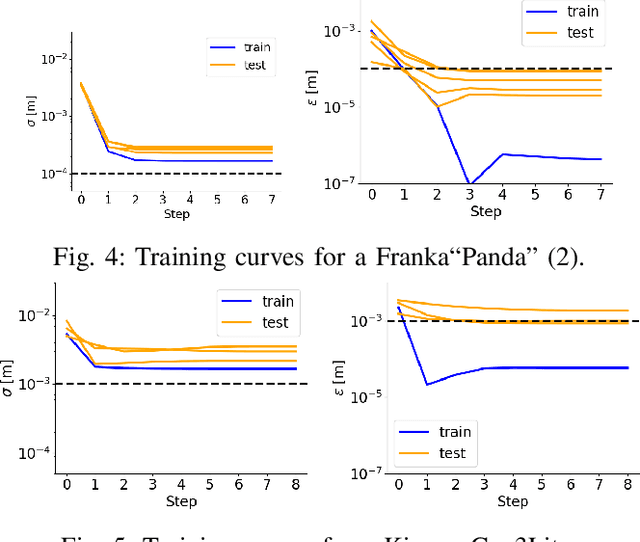
To increase the reliability of collaborative robots in performing daily tasks, we require them to be accurate and not only repeatable. However, having a calibrated kinematics model is regrettably a luxury, as available calibration tools are usually more expensive than the robots themselves. With this work, we aim to contribute to the democratization of cobots calibration by providing an inexpensive yet highly effective alternative to existing tools. The proposed minimalist calibration routine relies on a 3D-printable tool as the only physical aid to the calibration process. This two-socket spherical-joint tool kinematically constrains the robot at the end effector while collecting the training set. An optimization routine updates the nominal model to ensure a consistent prediction for each socket and the undistorted mean distance between them. We validated the algorithm on three robotic platforms: Franka, Kuka, and Kinova Cobots. The calibrated models reduce the mean absolute error from the order of 10 mm to 0.2 mm for both Franka and Kuka robots. We provide two additional experimental campaigns with the Franka Robot to render the improvements more tangible. First, we implement Cartesian control with and without the calibrated model and use it to perform a standard peg-in-the-hole task with a tolerance of 0.4 mm between the peg and the hole. Second, we perform a repeated drawing task combining Cartesian control with learning from demonstration. Both tasks consistently failed when the model was not calibrated, while they consistently succeeded after calibration.
Real-Time Generation of Near-Minimum-Energy Trajectories via Constraint-Informed Residual Learning
Jan 16, 2025Industrial robotics demands significant energy to operate, making energy-reduction methodologies increasingly important. Strategies for planning minimum-energy trajectories typically involve solving nonlinear optimal control problems (OCPs), which rarely cope with real-time requirements. In this paper, we propose a paradigm for generating near minimum-energy trajectories for manipulators by learning from optimal solutions. Our paradigm leverages a residual learning approach, which embeds boundary conditions while focusing on learning only the adjustments needed to steer a standard solution to an optimal one. Compared to a computationally expensive OCP-based planner, our paradigm achieves 87.3% of the performance near the training dataset and 50.8% far from the dataset, while being two to three orders of magnitude faster.
Mastering Contact-rich Tasks by Combining Soft and Rigid Robotics with Imitation Learning
Oct 10, 2024



Soft robots have the potential to revolutionize the use of robotic systems with their capability of establishing safe, robust, and adaptable interactions with their environment, but their precise control remains challenging. In contrast, traditional rigid robots offer high accuracy and repeatability but lack the flexibility of soft robots. We argue that combining these characteristics in a hybrid robotic platform can significantly enhance overall capabilities. This work presents a novel hybrid robotic platform that integrates a rigid manipulator with a fully developed soft arm. This system is equipped with the intelligence necessary to perform flexible and generalizable tasks through imitation learning autonomously. The physical softness and machine learning enable our platform to achieve highly generalizable skills, while the rigid components ensure precision and repeatability.
ILeSiA: Interactive Learning of Situational Awareness from Camera Input
Sep 30, 2024Learning from demonstration is a promising way of teaching robots new skills. However, a central problem when executing acquired skills is to recognize risks and failures. This is essential since the demonstrations usually cover only a few mostly successful cases. Inevitable errors during execution require specific reactions that were not apparent in the demonstrations. In this paper, we focus on teaching the robot situational awareness from an initial skill demonstration via kinesthetic teaching and sparse labeling of autonomous skill executions as safe or risky. At runtime, our system, called ILeSiA, detects risks based on the perceived camera images by encoding the images into a low-dimensional latent space representation and training a classifier based on the encoding and the provided labels. In this way, ILeSiA boosts the confidence and safety with which robotic skills can be executed. Our experiments demonstrate that classifiers, trained with only a small amount of user-provided data, can successfully detect numerous risks. The system is flexible because the risk cases are defined by labeling data. This also means that labels can be added as soon as risks are identified by a human supervisor. We provide all code and data required to reproduce our experiments at imitrob.ciirc.cvut.cz/publications/ilesia.
Generalization of Task Parameterized Dynamical Systems using Gaussian Process Transportation
Apr 20, 2024Learning from Interactive Demonstrations has revolutionized the way non-expert humans teach robots. It is enough to kinesthetically move the robot around to teach pick-and-place, dressing, or cleaning policies. However, the main challenge is correctly generalizing to novel situations, e.g., different surfaces to clean or different arm postures to dress. This article proposes a novel task parameterization and generalization to transport the original robot policy, i.e., position, velocity, orientation, and stiffness. Unlike the state of the art, only a set of points are tracked during the demonstration and the execution, e.g., a point cloud of the surface to clean. We then propose to fit a non-linear transformation that would deform the space and then the original policy using the paired source and target point sets. The use of function approximators like Gaussian Processes allows us to generalize, or transport, the policy from every space location while estimating the uncertainty of the resulting policy due to the limited points in the task parameterization point set and the reduced number of demonstrations. We compare the algorithm's performance with state-of-the-art task parameterization alternatives and analyze the effect of different function approximators. We also validated the algorithm on robot manipulation tasks, i.e., different posture arm dressing, different location product reshelving, and different shape surface cleaning.
A Unifying Variational Framework for Gaussian Process Motion Planning
Sep 02, 2023To control how a robot moves, motion planning algorithms must compute paths in high-dimensional state spaces while accounting for physical constraints related to motors and joints, generating smooth and stable motions, avoiding obstacles, and preventing collisions. A motion planning algorithm must therefore balance competing demands, and should ideally incorporate uncertainty to handle noise, model errors, and facilitate deployment in complex environments. To address these issues, we introduce a framework for robot motion planning based on variational Gaussian Processes, which unifies and generalizes various probabilistic-inference-based motion planning algorithms. Our framework provides a principled and flexible way to incorporate equality-based, inequality-based, and soft motion-planning constraints during end-to-end training, is straightforward to implement, and provides both interval-based and Monte-Carlo-based uncertainty estimates. We conduct experiments using different environments and robots, comparing against baseline approaches based on the feasibility of the planned paths, and obstacle avoidance quality. Results show that our proposed approach yields a good balance between success rates and path quality.
Do You Need a Hand? -- a Bimanual Robotic Dressing Assistance Scheme
Jan 19, 2023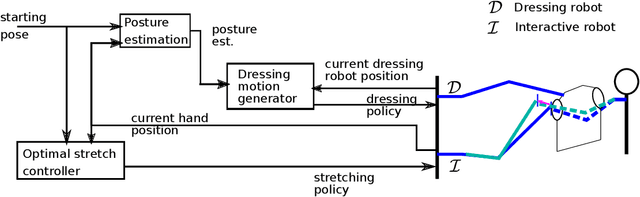
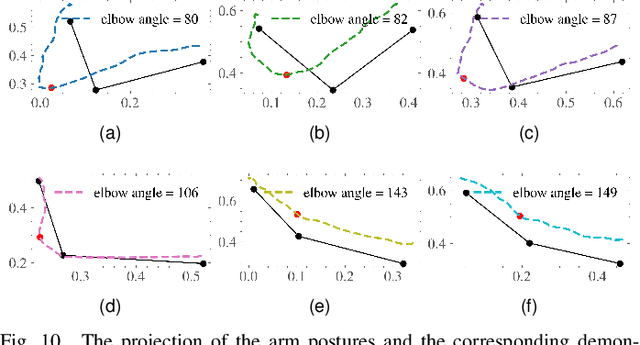
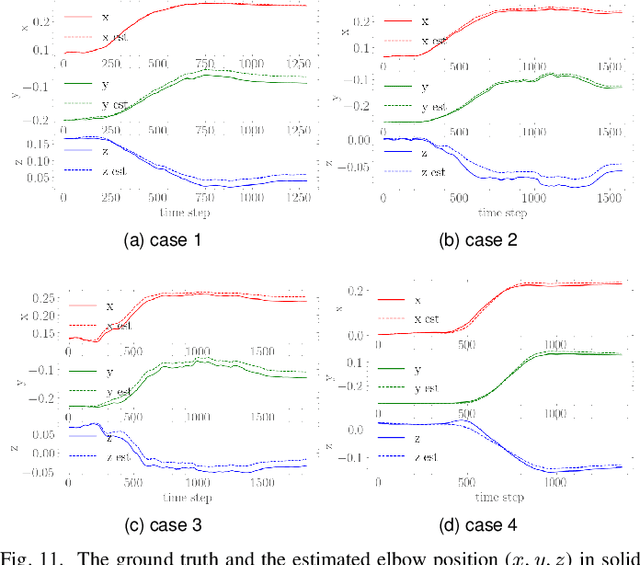
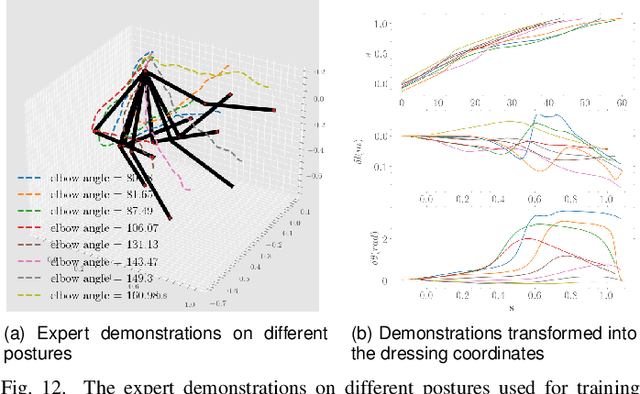
Developing physically assistive robots capable of dressing assistance has the potential to significantly improve the lives of the elderly and disabled population. However, most robotics dressing strategies considered a single robot only, which greatly limited the performance of the dressing assistance. In fact, healthcare professionals perform the task bimanually. Inspired by them, we propose a bimanual cooperative scheme for robotic dressing assistance. In the scheme, an interactive robot joins hands with the human thus supporting/guiding the human in the dressing process, while the dressing robot performs the dressing task. We identify a key feature that affects the dressing action and propose an optimal strategy for the interactive robot using the feature. A dressing coordinate based on the posture of the arm is defined to better encode the dressing policy. We validate the interactive dressing scheme with extensive experiments and also an ablation study. The experiment video is available on https://sites.google.com/view/bimanualassitdressing/home
Interactive Imitation Learning in Robotics: A Survey
Oct 31, 2022



Interactive Imitation Learning (IIL) is a branch of Imitation Learning (IL) where human feedback is provided intermittently during robot execution allowing an online improvement of the robot's behavior. In recent years, IIL has increasingly started to carve out its own space as a promising data-driven alternative for solving complex robotic tasks. The advantages of IIL are its data-efficient, as the human feedback guides the robot directly towards an improved behavior, and its robustness, as the distribution mismatch between the teacher and learner trajectories is minimized by providing feedback directly over the learner's trajectories. Nevertheless, despite the opportunities that IIL presents, its terminology, structure, and applicability are not clear nor unified in the literature, slowing down its development and, therefore, the research of innovative formulations and discoveries. In this article, we attempt to facilitate research in IIL and lower entry barriers for new practitioners by providing a survey of the field that unifies and structures it. In addition, we aim to raise awareness of its potential, what has been accomplished and what are still open research questions. We organize the most relevant works in IIL in terms of human-robot interaction (i.e., types of feedback), interfaces (i.e., means of providing feedback), learning (i.e., models learned from feedback and function approximators), user experience (i.e., human perception about the learning process), applications, and benchmarks. Furthermore, we analyze similarities and differences between IIL and RL, providing a discussion on how the concepts offline, online, off-policy and on-policy learning should be transferred to IIL from the RL literature. We particularly focus on robotic applications in the real world and discuss their implications, limitations, and promising future areas of research.
Interactive Imitation Learning of Bimanual Movement Primitives
Oct 28, 2022



Performing bimanual tasks with dual robotic setups can drastically increase the impact on industrial and daily life applications. However, performing a bimanual task brings many challenges, like synchronization and coordination of the single-arm policies. This article proposes the Safe, Interactive Movement Primitives Learning (SIMPLe) algorithm, to teach and correct single or dual arm impedance policies directly from human kinesthetic demonstrations. Moreover, it proposes a novel graph encoding of the policy based on Gaussian Process Regression (GPR) where the single-arm motion is guaranteed to converge close to the trajectory and then towards the demonstrated goal. A modulation of the robot stiffness according to the epistemic uncertainty of the policy allows for easily reshaping the motion with human feedback and/or adapting to external perturbations. We tested the SIMPLe algorithm on a real dual arm set up where the teacher gave separate single-arm demonstrations and then successfully synchronized them only using kinesthetic feedback or where the original bimanual demonstration was locally reshaped to pick a box at a different height.