 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Meaningful Collaboration: Worker-centered Design of a Physical Human-Robot Collaborative Blending Task
Oct 14, 2025
The use of robots in industrial settings continues to grow, driven by the need to address complex societal challenges such as labor shortages, aging populations, and ever-increasing production demands. In this abstract, we advocate for (and demonstrate) a transdisciplinary approach when considering robotics in the workplace. Transdisciplinarity emphasizes the integration of academic research with pragmatic expertise and embodied experiential knowledge, that prioritize values such as worker wellbeing and job attractiveness. In the following, we describe an ongoing multi-pronged effort to explore the potential of collaborative robots in the context of airplane engine repair and maintenance operations.
Visio-Verbal Teleimpedance Interface: Enabling Semi-Autonomous Control of Physical Interaction via Eye Tracking and Speech
Aug 27, 2025The paper presents a visio-verbal teleimpedance interface for commanding 3D stiffness ellipsoids to the remote robot with a combination of the operator's gaze and verbal interaction. The gaze is detected by an eye-tracker, allowing the system to understand the context in terms of what the operator is currently looking at in the scene. Along with verbal interaction, a Visual Language Model (VLM) processes this information, enabling the operator to communicate their intended action or provide corrections. Based on these inputs, the interface can then generate appropriate stiffness matrices for different physical interaction actions. To validate the proposed visio-verbal teleimpedance interface, we conducted a series of experiments on a setup including a Force Dimension Sigma.7 haptic device to control the motion of the remote Kuka LBR iiwa robotic arm. The human operator's gaze is tracked by Tobii Pro Glasses 2, while human verbal commands are processed by a VLM using GPT-4o. The first experiment explored the optimal prompt configuration for the interface. The second and third experiments demonstrated different functionalities of the interface on a slide-in-the-groove task.
Fitts' List Revisited: An Empirical Study on Function Allocation in a Two-Agent Physical Human-Robot Collaborative Position/Force Task
May 07, 2025In this letter, we investigate whether the classical function allocation holds for physical Human-Robot Collaboration, which is important for providing insights for Industry 5.0 to guide how to best augment rather than replace workers. This study empirically tests the applicability of Fitts' List within physical Human-Robot Collaboration, by conducting a user study (N=26, within-subject design) to evaluate four distinct allocations of position/force control between human and robot in an abstract blending task. We hypothesize that the function in which humans control the position achieves better performance and receives higher user ratings. When allocating position control to the human and force control to the robot, compared to the opposite case, we observed a significant improvement in preventing overblending. This was also perceived better in terms of physical demand and overall system acceptance, while participants experienced greater autonomy, more engagement and less frustration. An interesting insight was that the supervisory role (when the robot controls both position and force control) was rated second best in terms of subjective acceptance. Another surprising insight was that if position control was delegated to the robot, the participants perceived much lower autonomy than when the force control was delegated to the robot. These findings empirically support applying Fitts' principles to static function allocation for physical collaboration, while also revealing important nuanced user experience trade-offs, particularly regarding perceived autonomy when delegating position control.
Autonomous Navigation Of Quadrupeds Using Coverage Path Planning
Apr 24, 2025This paper proposes a novel method of coverage path planning for the purpose of scanning an unstructured environment autonomously. The method uses the morphological skeleton of the prior 2D navigation map via SLAM to generate a sequence of points of interest (POIs). This sequence is then ordered to create an optimal path given the robot's current position. To control the high-level operation, a finite state machine is used to switch between two modes: navigating towards a POI using Nav2, and scanning the local surrounding. We validate the method in a leveled indoor obstacle-free non-convex environment on time efficiency and reachability over five trials. The map reader and the path planner can quickly process maps of width and height ranging between [196,225] pixels and [185,231] pixels in 2.52 ms/pixel and 1.7 ms/pixel, respectively, where their computation time increases with 22.0 ns/pixel and 8.17 $\mu$s/pixel, respectively. The robot managed to reach 86.5\% of all waypoints over all five runs. The proposed method suffers from drift occurring in the 2D navigation map.
Planning Human-Robot Co-manipulation with Human Motor Control Objectives and Multi-component Reaching Strategies
Dec 18, 2024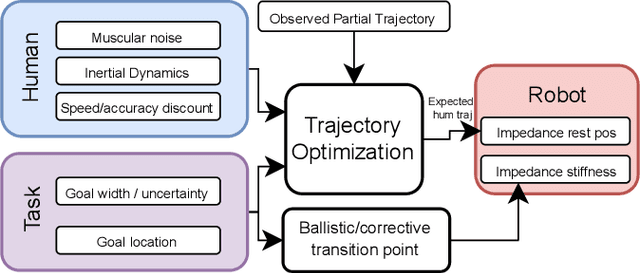
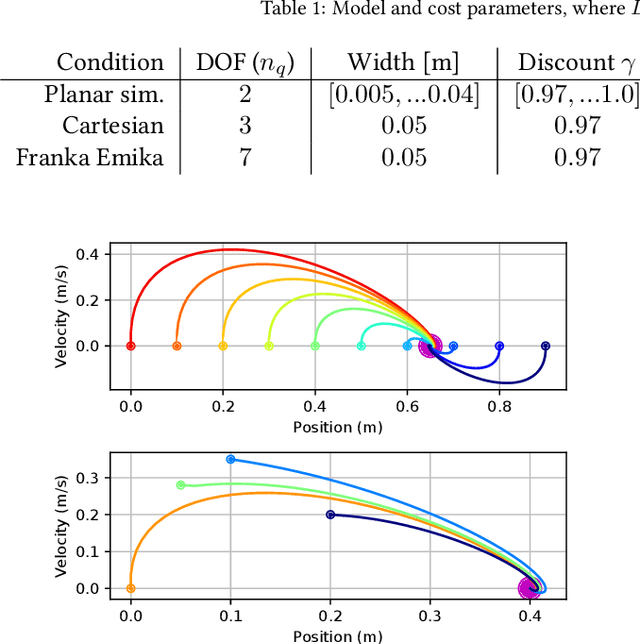
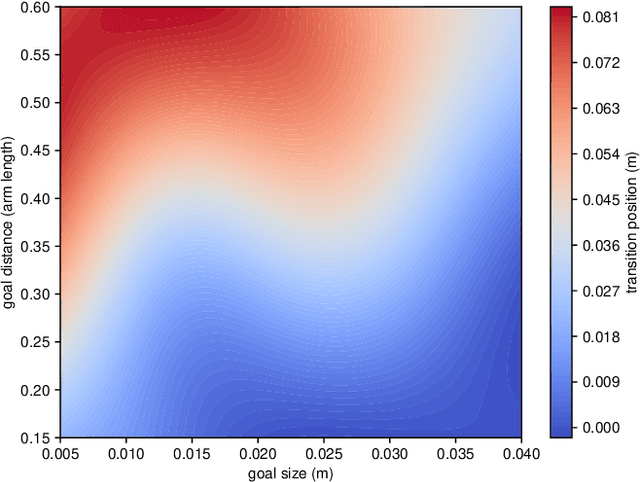
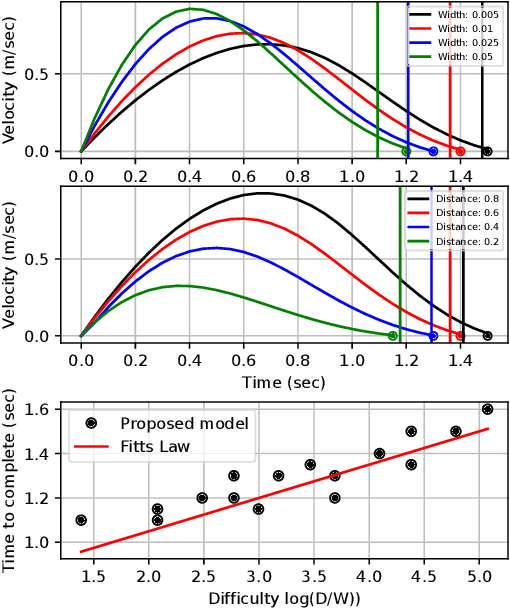
For successful goal-directed human-robot interaction, the robot should adapt to the intentions and actions of the collaborating human. This can be supported by musculoskeletal or data-driven human models, where the former are limited to lower-level functioning such as ergonomics, and the latter have limited generalizability or data efficiency. What is missing, is the inclusion of human motor control models that can provide generalizable human behavior estimates and integrate into robot planning methods. We use well-studied models from human motor control based on the speed-accuracy and cost-benefit trade-offs to plan collaborative robot motions. In these models, the human trajectory minimizes an objective function, a formulation we adapt to numerical trajectory optimization. This can then be extended with constraints and new variables to realize collaborative motion planning and goal estimation. We deploy this model, as well as a multi-component movement strategy, in physical collaboration with uncertain goal-reaching and synchronized motion tasks, showing the ability of the approach to produce human-like trajectories over a range of conditions.
Biomechanics-Aware Trajectory Optimization for Navigation during Robotic Physiotherapy
Nov 06, 2024



Robotic devices hold promise for aiding patients in orthopedic rehabilitation. However, current robotic-assisted physiotherapy methods struggle including biomechanical metrics in their control algorithms, crucial for safe and effective therapy. This paper introduces BATON, a Biomechanics-Aware Trajectory Optimization approach to robotic Navigation of human musculoskeletal loads. The method integrates a high-fidelity musculoskeletal model of the human shoulder into real-time control of robot-patient interaction during rotator cuff tendon rehabilitation. We extract skeletal dynamics and tendon loading information from an OpenSim shoulder model to solve an optimal control problem, generating strain-minimizing trajectories. Trajectories were realized on a healthy subject by an impedance-controlled robot while estimating the state of the subject's shoulder. Target poses were prescribed to design personalized rehabilitation across a wide range of shoulder motion avoiding high-strain areas. BATON was designed with real-time capabilities, enabling continuous trajectory replanning to address unforeseen variations in tendon strain, such as those from changing muscle activation of the subject.
Enhancing Supermarket Robot Interaction: A Multi-Level LLM Conversational Interface for Handling Diverse Customer Intents
Jun 16, 2024



This paper presents the design and evaluation of a novel multi-level LLM interface for supermarket robots to assist customers. The proposed interface allows customers to convey their needs through both generic and specific queries. While state-of-the-art systems like OpenAI's GPTs are highly adaptable and easy to build and deploy, they still face challenges such as increased response times and limitations in strategic control of the underlying model for tailored use-case and cost optimization. Driven by the goal of developing faster and more efficient conversational agents, this paper advocates for using multiple smaller, specialized LLMs fine-tuned to handle different user queries based on their specificity and user intent. We compare this approach to a specialized GPT model powered by GPT-4 Turbo, using the Artificial Social Agent Questionnaire (ASAQ) and qualitative participant feedback in a counterbalanced within-subjects experiment. Our findings show that our multi-LLM chatbot architecture outperformed the benchmarked GPT model across all 13 measured criteria, with statistically significant improvements in four key areas: performance, user satisfaction, user-agent partnership, and self-image enhancement. The paper also presents a method for supermarket robot navigation by mapping the final chatbot response to correct shelf numbers, enabling the robot to sequentially navigate towards the respective products, after which lower-level robot perception, control, and planning can be used for automated object retrieval. We hope this work encourages more efforts into using multiple, specialized smaller models instead of relying on a single powerful, but more expensive and slower model.
An Incremental Inverse Reinforcement Learning Approach for Motion Planning with Human Preferences
Jan 25, 2023Humans often demonstrate diverse behaviors due to their personal preferences, for instance related to their individual execution style or personal margin for safety. In this paper, we consider the problem of integrating such preferences into trajectory planning for robotic manipulators. We first learn reward functions that represent the user path and motion preferences from kinesthetic demonstration. We then use a discrete-time trajectory optimization scheme to produce trajectories that adhere to both task requirements and user preferences. We go beyond the state of art by designing a feature set that captures the fundamental preferences in a manipulation task, such as timing of the motion. We further demonstrate that our method is capable of generalizing such preferences to new scenarios. We implement our algorithm on a Franka Emika 7-DoF robot arm, and validate the functionality and flexibility of our approach in a user study. The results show that non-expert users are able to teach the robot their preferences with just a few iterations of feedback.
Interactive Imitation Learning of Bimanual Movement Primitives
Oct 28, 2022



Performing bimanual tasks with dual robotic setups can drastically increase the impact on industrial and daily life applications. However, performing a bimanual task brings many challenges, like synchronization and coordination of the single-arm policies. This article proposes the Safe, Interactive Movement Primitives Learning (SIMPLe) algorithm, to teach and correct single or dual arm impedance policies directly from human kinesthetic demonstrations. Moreover, it proposes a novel graph encoding of the policy based on Gaussian Process Regression (GPR) where the single-arm motion is guaranteed to converge close to the trajectory and then towards the demonstrated goal. A modulation of the robot stiffness according to the epistemic uncertainty of the policy allows for easily reshaping the motion with human feedback and/or adapting to external perturbations. We tested the SIMPLe algorithm on a real dual arm set up where the teacher gave separate single-arm demonstrations and then successfully synchronized them only using kinesthetic feedback or where the original bimanual demonstration was locally reshaped to pick a box at a different height.
Model Predictive Impedance Control with Gaussian Processes for Human and Environment Interaction
Aug 15, 2022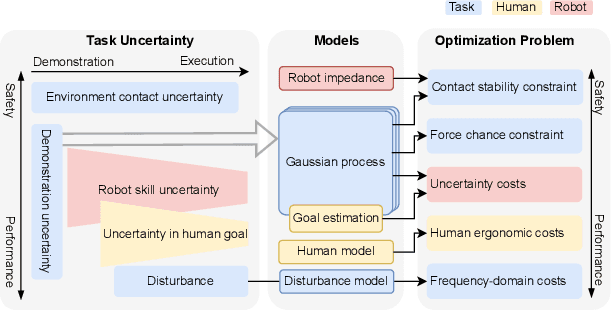
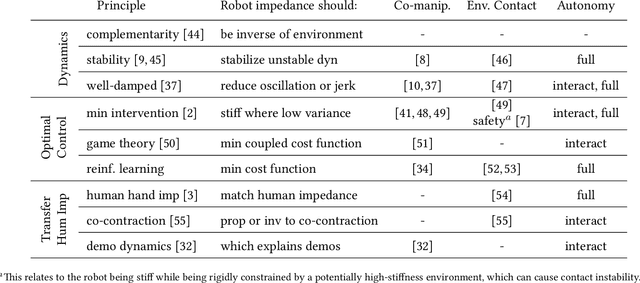
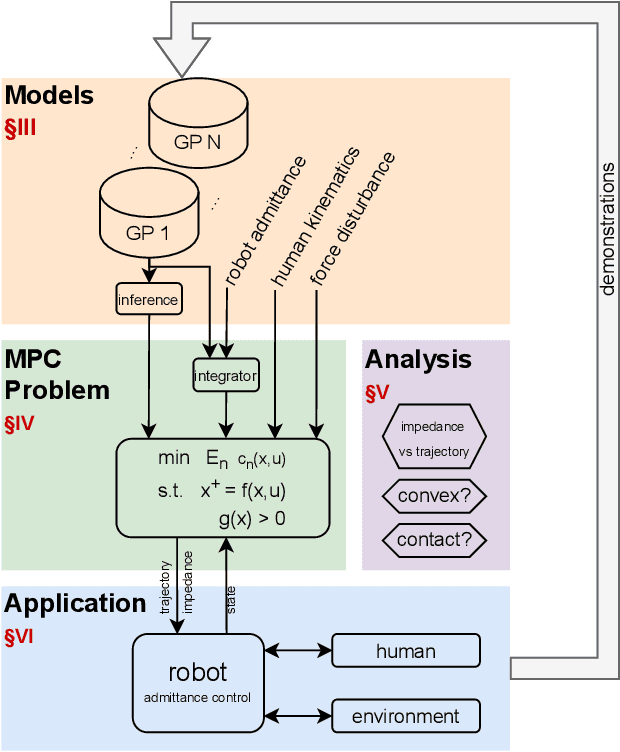
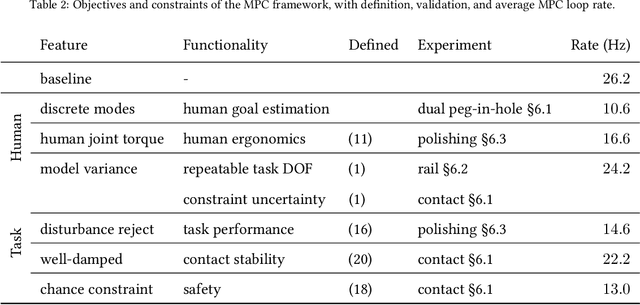
In tasks where the goal or configuration varies between iterations, human-robot interaction (HRI) can allow the robot to handle repeatable aspects and the human to provide information which adapts to the current state. Advanced interactive robot behaviors are currently realized by inferring human goal or, for physical interaction, adapting robot impedance. While many application-specific heuristics have been proposed for interactive robot behavior, they are often limited in scope, e.g. only considering human ergonomics or task performance. To improve generality, this paper proposes a framework which plans both trajectory and impedance online, handles a mix of task and human objectives, and can be efficiently applied to a new task. This framework can consider many types of uncertainty: contact constraint variation, uncertainty in human goals, or task disturbances. An uncertainty-aware task model is learned from a few demonstrations using Gaussian Processes. This task model is used in a nonlinear model predictive control (MPC) problem to optimize robot trajectory and impedance according to belief in discrete human goals, human kinematics, safety constraints, contact stability, and frequency-domain disturbance rejection. This MPC formulation is introduced, analyzed with respect to convexity, and validated in co-manipulation with multiple goals, a collaborative polishing task, and a collaborative assembly task.