 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee and Switch: Vision-Based Branching for Interactive Robot-Skill Programming
Mar 09, 2026Programming robots by demonstration (PbD) is an intuitive concept, but scaling it to real-world variability remains a challenge for most current teaching frameworks. Conditional task graphs are very expressive and can be defined incrementally, which fits very well with the PbD idea. However, acting using conditional task graphs requires reliable perception-grounded online branch selection. In this paper, we present See & Switch, an interactive teaching-and-execution framework that represents tasks as user-extendable graphs of skill parts connected via decision states (DS), enabling conditional branching during replay. Unlike prior approaches that rely on manual branching or low-dimensional signals (e.g., proprioception), our vision-based Switcher uses eye-in-hand images (high-dimensional) to select among competing successor skill parts and to detect out-of-distribution contexts that require new demonstrations. We integrate kinesthetic teaching, joystick control, and hand gestures via an input-modality-abstraction layer and demonstrate that our proposed method is teaching modality-independent, enabling efficient in-situ recovery demonstrations. The system is validated in experiments on three challenging dexterous manipulation tasks. We evaluate our method under diverse conditions and furthermore conduct user studies with 8 participants. We show that the proposed method reliably performs branch selection and anomaly detection for novice users, achieving 90.7 % and 87.9 % accuracy, respectively, across 576 real-robot rollouts. We provide all code and data required to reproduce our experiments at http://imitrob.ciirc.cvut.cz/publications/seeandswitch.
MuBlE: MuJoCo and Blender simulation Environment and Benchmark for Task Planning in Robot Manipulation
Mar 04, 2025Current embodied reasoning agents struggle to plan for long-horizon tasks that require to physically interact with the world to obtain the necessary information (e.g. 'sort the objects from lightest to heaviest'). The improvement of the capabilities of such an agent is highly dependent on the availability of relevant training environments. In order to facilitate the development of such systems, we introduce a novel simulation environment (built on top of robosuite) that makes use of the MuJoCo physics engine and high-quality renderer Blender to provide realistic visual observations that are also accurate to the physical state of the scene. It is the first simulator focusing on long-horizon robot manipulation tasks preserving accurate physics modeling. MuBlE can generate mutlimodal data for training and enable design of closed-loop methods through environment interaction on two levels: visual - action loop, and control - physics loop. Together with the simulator, we propose SHOP-VRB2, a new benchmark composed of 10 classes of multi-step reasoning scenarios that require simultaneous visual and physical measurements.
ILeSiA: Interactive Learning of Situational Awareness from Camera Input
Sep 30, 2024Learning from demonstration is a promising way of teaching robots new skills. However, a central problem when executing acquired skills is to recognize risks and failures. This is essential since the demonstrations usually cover only a few mostly successful cases. Inevitable errors during execution require specific reactions that were not apparent in the demonstrations. In this paper, we focus on teaching the robot situational awareness from an initial skill demonstration via kinesthetic teaching and sparse labeling of autonomous skill executions as safe or risky. At runtime, our system, called ILeSiA, detects risks based on the perceived camera images by encoding the images into a low-dimensional latent space representation and training a classifier based on the encoding and the provided labels. In this way, ILeSiA boosts the confidence and safety with which robotic skills can be executed. Our experiments demonstrate that classifiers, trained with only a small amount of user-provided data, can successfully detect numerous risks. The system is flexible because the risk cases are defined by labeling data. This also means that labels can be added as soon as risks are identified by a human supervisor. We provide all code and data required to reproduce our experiments at imitrob.ciirc.cvut.cz/publications/ilesia.
Closed Loop Interactive Embodied Reasoning for Robot Manipulation
Apr 23, 2024Embodied reasoning systems integrate robotic hardware and cognitive processes to perform complex tasks typically in response to a natural language query about a specific physical environment. This usually involves changing the belief about the scene or physically interacting and changing the scene (e.g. 'Sort the objects from lightest to heaviest'). In order to facilitate the development of such systems we introduce a new simulating environment that makes use of MuJoCo physics engine and high-quality renderer Blender to provide realistic visual observations that are also accurate to the physical state of the scene. Together with the simulator we propose a new benchmark composed of 10 classes of multi-step reasoning scenarios that require simultaneous visual and physical measurements. Finally, we develop a new modular Closed Loop Interactive Reasoning (CLIER) approach that takes into account the measurements of non-visual object properties, changes in the scene caused by external disturbances as well as uncertain outcomes of robotic actions. We extensively evaluate our reasoning approach in simulation and in the real world manipulation tasks with a success rate above 76% and 64%, respectively.
Interactive Learning of Physical Object Properties Through Robot Manipulation and Database of Object Measurements
Apr 10, 2024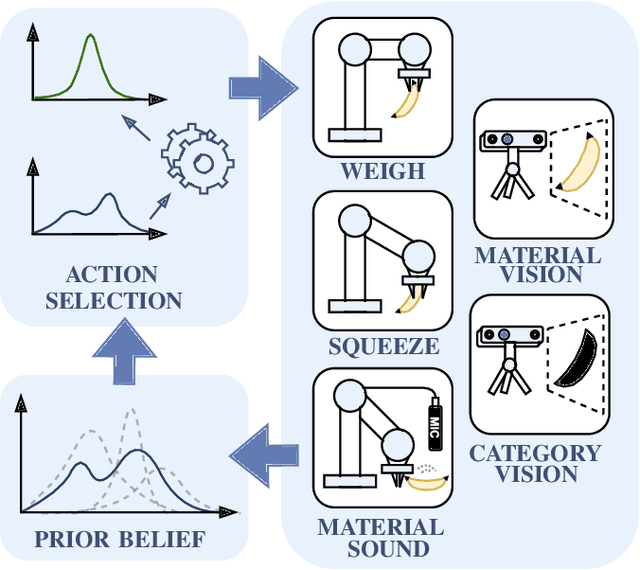
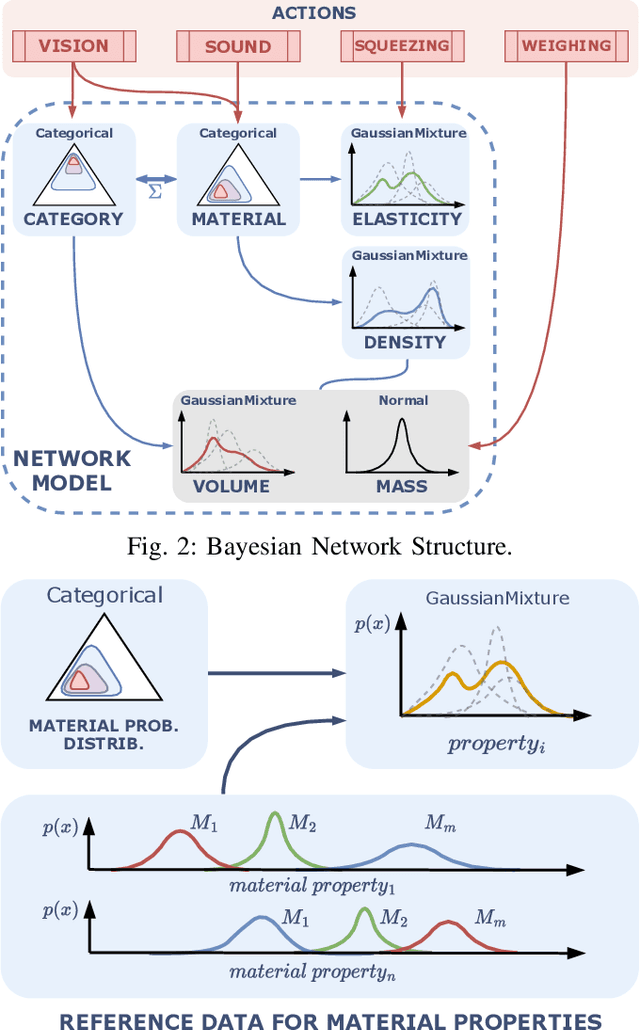

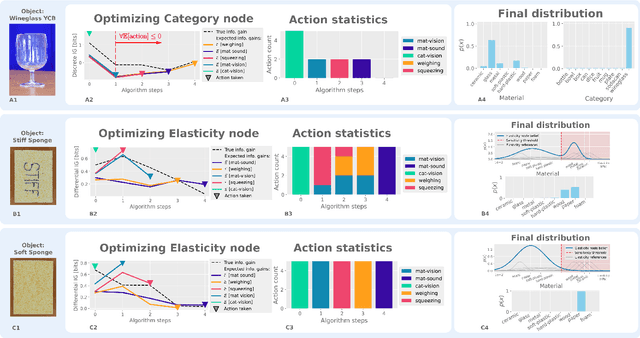
This work presents a framework for automatically extracting physical object properties, such as material composition, mass, volume, and stiffness, through robot manipulation and a database of object measurements. The framework involves exploratory action selection to maximize learning about objects on a table. A Bayesian network models conditional dependencies between object properties, incorporating prior probability distributions and uncertainty associated with measurement actions. The algorithm selects optimal exploratory actions based on expected information gain and updates object properties through Bayesian inference. Experimental evaluation demonstrates effective action selection compared to a baseline and correct termination of the experiments if there is nothing more to be learned. The algorithm proved to behave intelligently when presented with trick objects with material properties in conflict with their appearance. The robot pipeline integrates with a logging module and an online database of objects, containing over 24,000 measurements of 63 objects with different grippers. All code and data are publicly available, facilitating automatic digitization of objects and their physical properties through exploratory manipulations.
CoBOS: Constraint-Based Online Scheduler for Human-Robot Collaboration
Mar 27, 2024Assembly processes involving humans and robots are challenging scenarios because the individual activities and access to shared workspace have to be coordinated. Fixed robot programs leave no room to diverge from a fixed protocol. Working on such a process can be stressful for the user and lead to ineffective behavior or failure. We propose a novel approach of online constraint-based scheduling in a reactive execution control framework facilitating behavior trees called CoBOS. This allows the robot to adapt to uncertain events such as delayed activity completions and activity selection (by the human). The user will experience less stress as the robotic coworkers adapt their behavior to best complement the human-selected activities to complete the common task. In addition to the improved working conditions, our algorithm leads to increased efficiency, even in highly uncertain scenarios. We evaluate our algorithm using a probabilistic simulation study with 56000 experiments. We outperform all baselines by a margin of 4-10%. Initial real robot experiments using a Franka Emika Panda robot and human tracking based on HTC Vive VR gloves look promising.
Visually Guided Model Predictive Robot Control via 6D Object Pose Localization and Tracking
Nov 09, 2023



The objective of this work is to enable manipulation tasks with respect to the 6D pose of a dynamically moving object using a camera mounted on a robot. Examples include maintaining a constant relative 6D pose of the robot arm with respect to the object, grasping the dynamically moving object, or co-manipulating the object together with a human. Fast and accurate 6D pose estimation is crucial to achieve smooth and stable robot control in such situations. The contributions of this work are three fold. First, we propose a new visual perception module that asynchronously combines accurate learning-based 6D object pose localizer and a high-rate model-based 6D pose tracker. The outcome is a low-latency accurate and temporally consistent 6D object pose estimation from the input video stream at up to 120 Hz. Second, we develop a visually guided robot arm controller that combines the new visual perception module with a torque-based model predictive control algorithm. Asynchronous combination of the visual and robot proprioception signals at their corresponding frequencies results in stable and robust 6D object pose guided robot arm control. Third, we experimentally validate the proposed approach on a challenging 6D pose estimation benchmark and demonstrate 6D object pose-guided control with dynamically moving objects on a real 7 DoF Franka Emika Panda robot.
Communicating human intent to a robotic companion by multi-type gesture sentences
Mar 08, 2023


Human-Robot collaboration in home and industrial workspaces is on the rise. However, the communication between robots and humans is a bottleneck. Although people use a combination of different types of gestures to complement speech, only a few robotic systems utilize gestures for communication. In this paper, we propose a gesture pseudo-language and show how multiple types of gestures can be combined to express human intent to a robot (i.e., expressing both the desired action and its parameters - e.g., pointing to an object and showing that the object should be emptied into a bowl). The demonstrated gestures and the perceived table-top scene (object poses detected by CosyPose) are processed in real-time) to extract the human's intent. We utilize behavior trees to generate reactive robot behavior that handles various possible states of the world (e.g., a drawer has to be opened before an object is placed into it) and recovers from errors (e.g., when the scene changes). Furthermore, our system enables switching between direct teleoperation of the end-effector and high-level operation using the proposed gesture sentences. The system is evaluated on increasingly complex tasks using a real 7-DoF Franka Emika Panda manipulator. Controlling the robot via action gestures lowered the execution time by up to 60%, compared to direct teleoperation.
Context-aware robot control using gesture episodes
Jan 24, 2023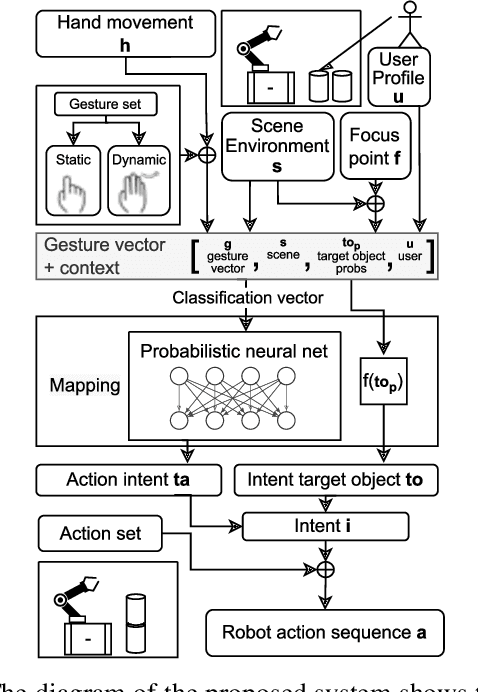
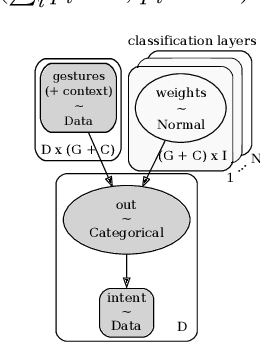
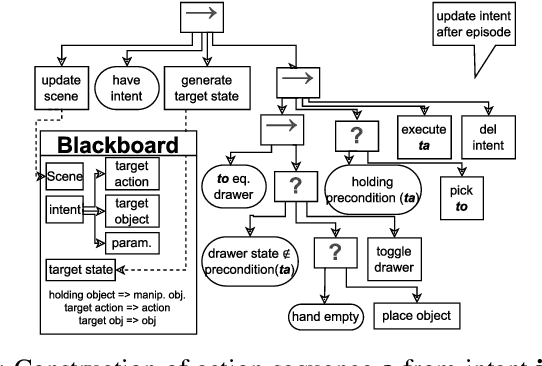
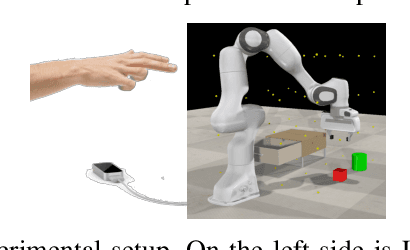
Collaborative robots became a popular tool for increasing productivity in partly automated manufacturing plants. Intuitive robot teaching methods are required to quickly and flexibly adapt the robot programs to new tasks. Gestures have an essential role in human communication. However, in human-robot-interaction scenarios, gesture-based user interfaces are so far used rarely, and if they employ a one-to-one mapping of gestures to robot control variables. In this paper, we propose a method that infers the user's intent based on gesture episodes, the context of the situation, and common sense. The approach is evaluated in a simulated table-top manipulation setting. We conduct deterministic experiments with simulated users and show that the system can even handle personal preferences of each user.
Imitrob: Imitation Learning Dataset for Training and Evaluating 6D Object Pose Estimators
Sep 19, 2022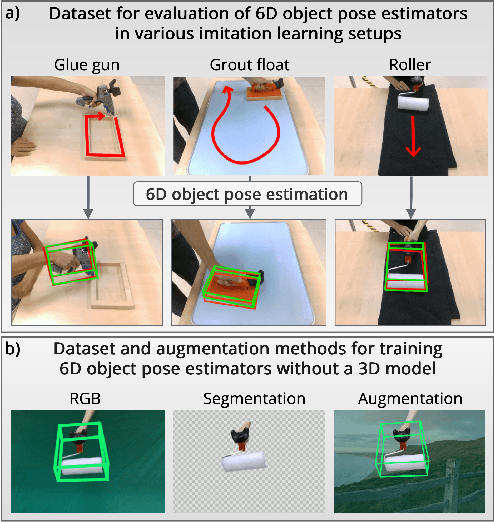


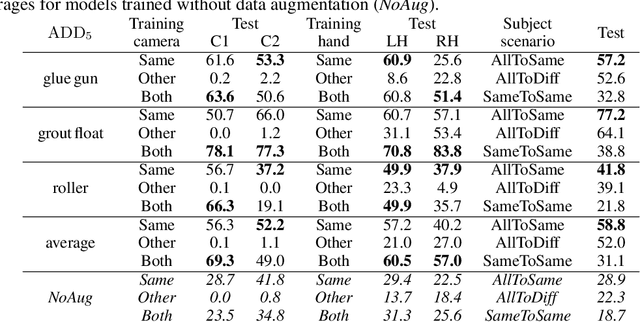
This paper introduces a dataset for training and evaluating methods for 6D pose estimation of hand-held tools in task demonstrations captured by a standard RGB camera. Despite the significant progress of 6D pose estimation methods, their performance is usually limited for heavily occluded objects, which is a common case in imitation learning where the object is typically partially occluded by the manipulating hand. Currently, there is a lack of datasets that would enable the development of robust 6D pose estimation methods for these conditions. To overcome this problem, we collect a new dataset (Imitrob) aimed at 6D pose estimation in imitation learning and other applications where a human holds a tool and performs a task. The dataset contains image sequences of three different tools and six manipulation tasks with two camera viewpoints, four human subjects, and left/right hand. Each image is accompanied by an accurate ground truth measurement of the 6D object pose, obtained by the HTC Vive motion tracking device. The use of the dataset is demonstrated by training and evaluating a recent 6D object pose estimation method (DOPE) in various setups. The dataset and code are publicly available at http://imitrob.ciirc.cvut.cz/imitrobdataset.php.