Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Policy Transfer with Imprecise Perception Simulation
Paper and Code
Apr 05, 2018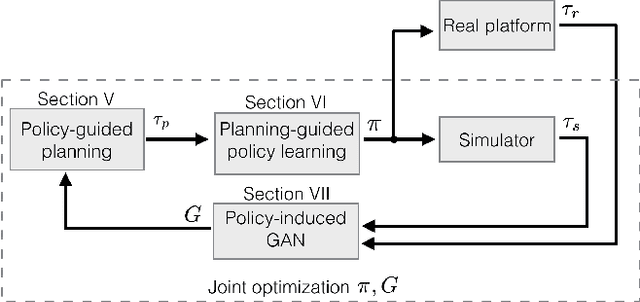

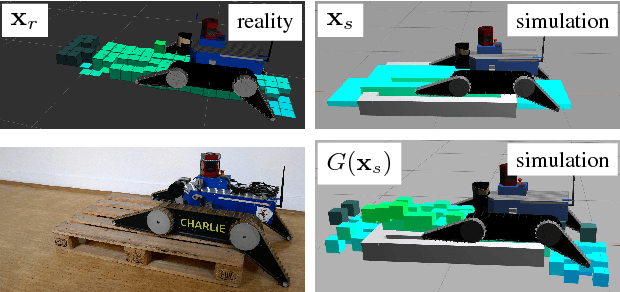
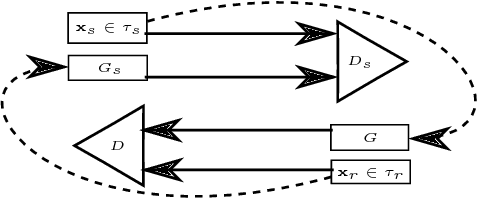
The paper presents a complete pipeline for learning continuous motion control policies for a mobile robot when only a non-differentiable physics simulator of robot-terrain interactions is available. The multi-modal state estimation of the robot is also complex and difficult to simulate, so we simultaneously learn a generative model which refines simulator outputs. We propose a coarse-to-fine learning paradigm, where the coarse motion planning is alternated with imitation learning and policy transfer to the real robot. The policy is jointly optimized with the generative model. We evaluate the method on a real-world platform in a batch of experiments.
* Submitted to IROS 2018 with RAL option
View paper on