 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural inpainting
Paper and Code
Mar 27, 2018


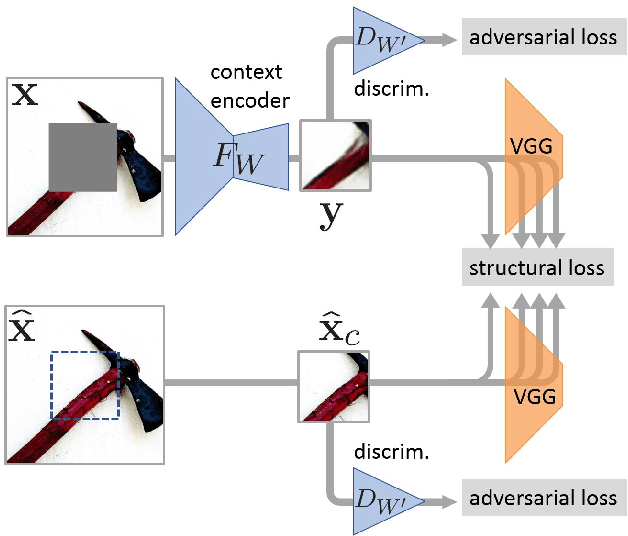
Scene-agnostic visual inpainting remains very challenging despite progress in patch-based methods. Recently, Pathak et al. 2016 have introduced convolutional "context encoders" (CEs) for unsupervised feature learning through image completion tasks. With the additional help of adversarial training, CEs turned out to be a promising tool to complete complex structures in real inpainting problems. In the present paper we propose to push further this key ability by relying on perceptual reconstruction losses at training time. We show on a wide variety of visual scenes the merit of the approach for structural inpainting, and confirm it through a user study. Combined with the optimization-based refinement of Yang et al. 2016 with neural patches, our context encoder opens up new opportunities for prior-free visual inpainting.