 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIESTA: Fisher Information-based Efficient Selective Test-time Adaptation
Mar 29, 2025Robust facial expression recognition in unconstrained, "in-the-wild" environments remains challenging due to significant domain shifts between training and testing distributions. Test-time adaptation (TTA) offers a promising solution by adapting pre-trained models during inference without requiring labeled test data. However, existing TTA approaches typically rely on manually selecting which parameters to update, potentially leading to suboptimal adaptation and high computational costs. This paper introduces a novel Fisher-driven selective adaptation framework that dynamically identifies and updates only the most critical model parameters based on their importance as quantified by Fisher information. By integrating this principled parameter selection approach with temporal consistency constraints, our method enables efficient and effective adaptation specifically tailored for video-based facial expression recognition. Experiments on the challenging AffWild2 benchmark demonstrate that our approach significantly outperforms existing TTA methods, achieving a 7.7% improvement in F1 score over the base model while adapting only 22,000 parameters-more than 20 times fewer than comparable methods. Our ablation studies further reveal that parameter importance can be effectively estimated from minimal data, with sampling just 1-3 frames sufficient for substantial performance gains. The proposed approach not only enhances recognition accuracy but also dramatically reduces computational overhead, making test-time adaptation more practical for real-world affective computing applications.
Challenges in the Differential Classification of Individual Diagnoses from Co-Occurring Autism and ADHD Using Survey Data
Nov 13, 2024



Autism and Attention-Deficit Hyperactivity Disorder (ADHD) are two of the most commonly observed neurodevelopmental conditions in childhood. Providing a specific computational assessment to distinguish between the two can prove difficult and time intensive. Given the high prevalence of their co-occurrence, there is a need for scalable and accessible methods for distinguishing the co-occurrence of autism and ADHD from individual diagnoses. The first step is to identify a core set of features that can serve as the basis for behavioral feature extraction. We trained machine learning models on data from the National Survey of Children's Health to identify behaviors to target as features in automated clinical decision support systems. A model trained on the binary task of distinguishing either developmental delay (autism or ADHD) vs. neither achieved sensitivity >92% and specificity >94%, while a model trained on the 4-way classification task of autism vs. ADHD vs. both vs. none demonstrated >65% sensitivity and >66% specificity. While the performance of the binary model was respectable, the relatively low performance in the differential classification of autism and ADHD highlights the challenges that persist in achieving specificity within clinical decision support tools for developmental delays. Nevertheless, this study demonstrates the potential of applying behavioral questionnaires not traditionally used for clinical purposes towards supporting digital screening assessments for pediatric developmental delays.
Ensemble Modeling of Multiple Physical Indicators to Dynamically Phenotype Autism Spectrum Disorder
Aug 23, 2024



Early detection of autism, a neurodevelopmental disorder marked by social communication challenges, is crucial for timely intervention. Recent advancements have utilized naturalistic home videos captured via the mobile application GuessWhat. Through interactive games played between children and their guardians, GuessWhat has amassed over 3,000 structured videos from 382 children, both diagnosed with and without Autism Spectrum Disorder (ASD). This collection provides a robust dataset for training computer vision models to detect ASD-related phenotypic markers, including variations in emotional expression, eye contact, and head movements. We have developed a protocol to curate high-quality videos from this dataset, forming a comprehensive training set. Utilizing this set, we trained individual LSTM-based models using eye gaze, head positions, and facial landmarks as input features, achieving test AUCs of 86%, 67%, and 78%, respectively. To boost diagnostic accuracy, we applied late fusion techniques to create ensemble models, improving the overall AUC to 90%. This approach also yielded more equitable results across different genders and age groups. Our methodology offers a significant step forward in the early detection of ASD by potentially reducing the reliance on subjective assessments and making early identification more accessibly and equitable.
TempT: Temporal consistency for Test-time adaptation
Mar 19, 2023



In this technical report, we introduce TempT, a novel method for test time adaptation on videos by ensuring temporal coherence of predictions across sequential frames. TempT is a powerful tool with broad applications in computer vision tasks, including facial expression recognition (FER) in videos. We evaluate TempT's performance on the AffWild2 dataset as part of the Expression Classification Challenge at the 5th Workshop and Competition on Affective Behavior Analysis in the wild (ABAW). Our approach focuses solely on the unimodal visual aspect of the data and utilizes a popular 2D CNN backbone, in contrast to larger sequential or attention based models. Our experimental results demonstrate that TempT has competitive performance in comparison to previous years reported performances, and its efficacy provides a compelling proof of concept for its use in various real world applications.
A Review of and Roadmap for Data Science and Machine Learning for the Neuropsychiatric Phenotype of Autism
Mar 07, 2023Autism Spectrum Disorder (autism) is a neurodevelopmental delay which affects at least 1 in 44 children. Like many neurological disorder phenotypes, the diagnostic features are observable, can be tracked over time, and can be managed or even eliminated through proper therapy and treatments. Yet, there are major bottlenecks in the diagnostic, therapeutic, and longitudinal tracking pipelines for autism and related delays, creating an opportunity for novel data science solutions to augment and transform existing workflows and provide access to services for more affected families. Several prior efforts conducted by a multitude of research labs have spawned great progress towards improved digital diagnostics and digital therapies for children with autism. We review the literature of digital health methods for autism behavior quantification using data science. We describe both case-control studies and classification systems for digital phenotyping. We then discuss digital diagnostics and therapeutics which integrate machine learning models of autism-related behaviors, including the factors which must be addressed for translational use. Finally, we describe ongoing challenges and potent opportunities for the field of autism data science. Given the heterogeneous nature of autism and the complexities of the relevant behaviors, this review contains insights which are relevant to neurological behavior analysis and digital psychiatry more broadly.
Mitigating Negative Transfer in Multi-Task Learning with Exponential Moving Average Loss Weighting Strategies
Nov 22, 2022



Multi-Task Learning (MTL) is a growing subject of interest in deep learning, due to its ability to train models more efficiently on multiple tasks compared to using a group of conventional single-task models. However, MTL can be impractical as certain tasks can dominate training and hurt performance in others, thus making some tasks perform better in a single-task model compared to a multi-task one. Such problems are broadly classified as negative transfer, and many prior approaches in the literature have been made to mitigate these issues. One such current approach to alleviate negative transfer is to weight each of the losses so that they are on the same scale. Whereas current loss balancing approaches rely on either optimization or complex numerical analysis, none directly scale the losses based on their observed magnitudes. We propose multiple techniques for loss balancing based on scaling by the exponential moving average and benchmark them against current best-performing methods on three established datasets. On these datasets, they achieve comparable, if not higher, performance compared to current best-performing methods.
An Exploration of Active Learning for Affective Digital Phenotyping
Apr 06, 2022
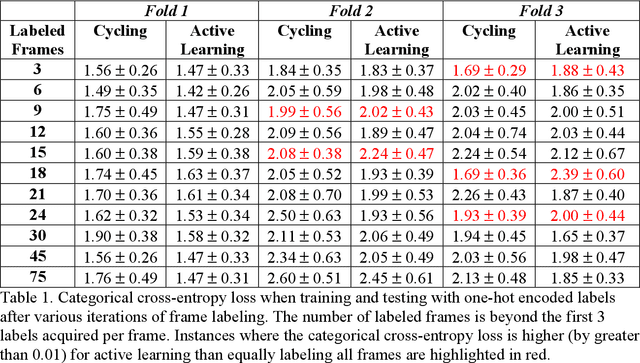
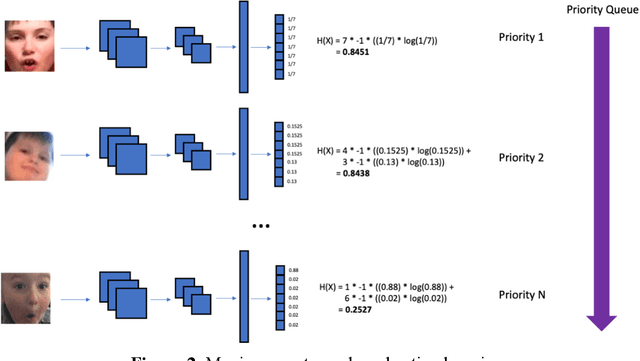
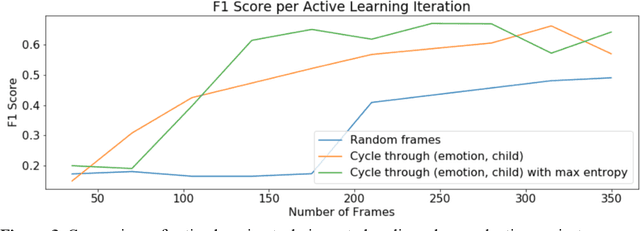
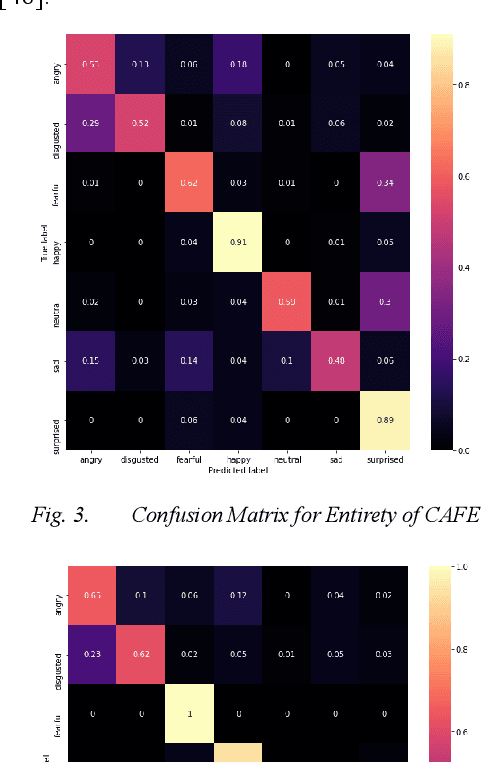
Some of the most severe bottlenecks preventing widespread development of machine learning models for human behavior include a dearth of labeled training data and difficulty of acquiring high quality labels. Active learning is a paradigm for using algorithms to computationally select a useful subset of data points to label using metrics for model uncertainty and data similarity. We explore active learning for naturalistic computer vision emotion data, a particularly heterogeneous and complex data space due to inherently subjective labels. Using frames collected from gameplay acquired from a therapeutic smartphone game for children with autism, we run a simulation of active learning using gameplay prompts as metadata to aid in the active learning process. We find that active learning using information generated during gameplay slightly outperforms random selection of the same number of labeled frames. We next investigate a method to conduct active learning with subjective data, such as in affective computing, and where multiple crowdsourced labels can be acquired for each image. Using the Child Affective Facial Expression (CAFE) dataset, we simulate an active learning process for crowdsourcing many labels and find that prioritizing frames using the entropy of the crowdsourced label distribution results in lower categorical cross-entropy loss compared to random frame selection. Collectively, these results demonstrate pilot evaluations of two novel active learning approaches for subjective affective data collected in noisy settings.
Challenges and Opportunities for Machine Learning Classification of Behavior and Mental State from Images
Jan 26, 2022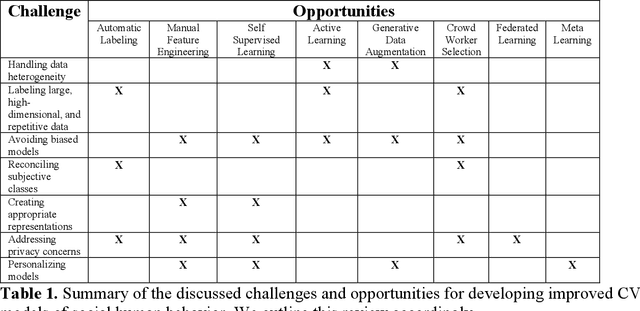
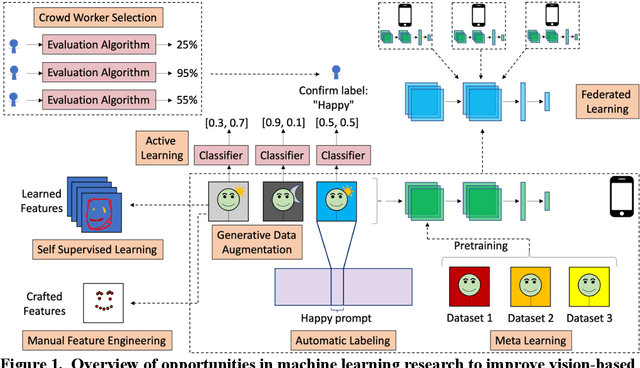
Computer Vision (CV) classifiers which distinguish and detect nonverbal social human behavior and mental state can aid digital diagnostics and therapeutics for psychiatry and the behavioral sciences. While CV classifiers for traditional and structured classification tasks can be developed with standard machine learning pipelines for supervised learning consisting of data labeling, preprocessing, and training a convolutional neural network, there are several pain points which arise when attempting this process for behavioral phenotyping. Here, we discuss the challenges and corresponding opportunities in this space, including handling heterogeneous data, avoiding biased models, labeling massive and repetitive data sets, working with ambiguous or compound class labels, managing privacy concerns, creating appropriate representations, and personalizing models. We discuss current state-of-the-art research endeavors in CV such as data curation, data augmentation, crowdsourced labeling, active learning, reinforcement learning, generative models, representation learning, federated learning, and meta-learning. We highlight at least some of the machine learning advancements needed for imaging classifiers to detect human social cues successfully and reliably.
Training and Profiling a Pediatric Emotion Recognition Classifier on Mobile Devices
Aug 22, 2021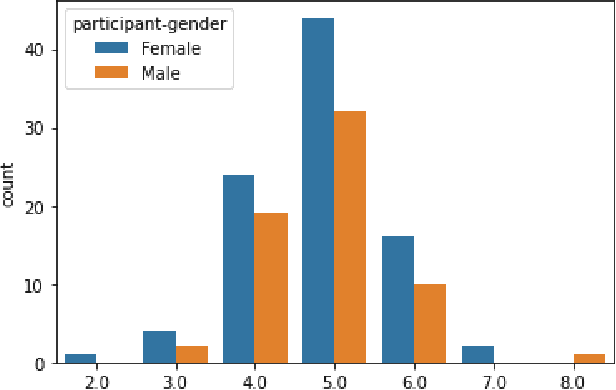
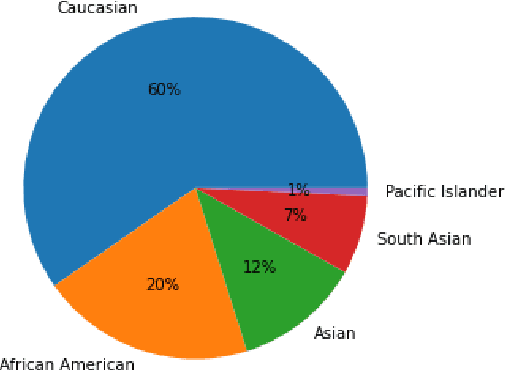
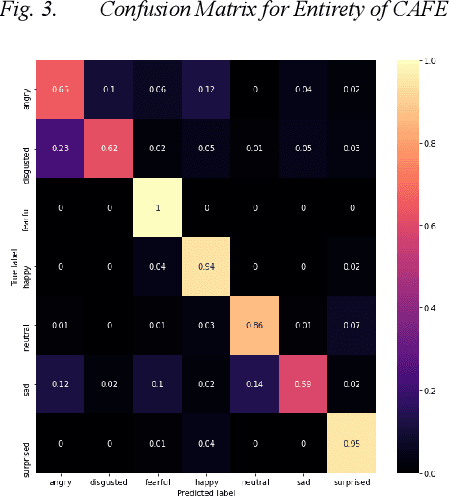
Implementing automated emotion recognition on mobile devices could provide an accessible diagnostic and therapeutic tool for those who struggle to recognize emotion, including children with developmental behavioral conditions such as autism. Although recent advances have been made in building more accurate emotion classifiers, existing models are too computationally expensive to be deployed on mobile devices. In this study, we optimized and profiled various machine learning models designed for inference on edge devices and were able to match previous state of the art results for emotion recognition on children. Our best model, a MobileNet-V2 network pre-trained on ImageNet, achieved 65.11% balanced accuracy and 64.19% F1-score on CAFE, while achieving a 45-millisecond inference latency on a Motorola Moto G6 phone. This balanced accuracy is only 1.79% less than the current state of the art for CAFE, which used a model that contains 26.62x more parameters and was unable to run on the Moto G6, even when fully optimized. This work validates that with specialized design and optimization techniques, machine learning models can become lightweight enough for deployment on mobile devices and still achieve high accuracies on difficult image classification tasks.
NetVec: A Scalable Hypergraph Embedding System
Mar 09, 2021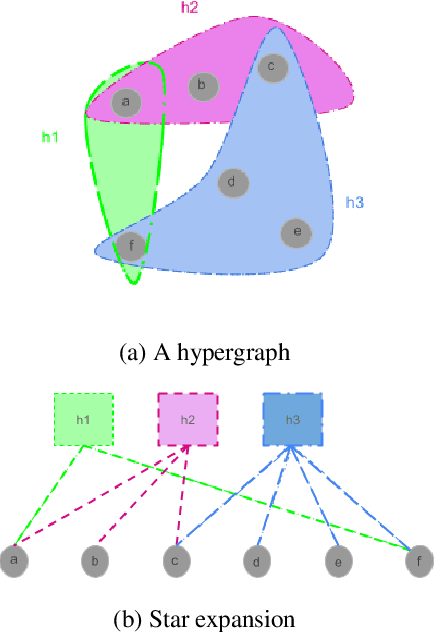
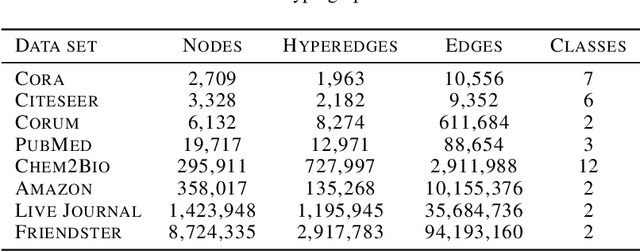
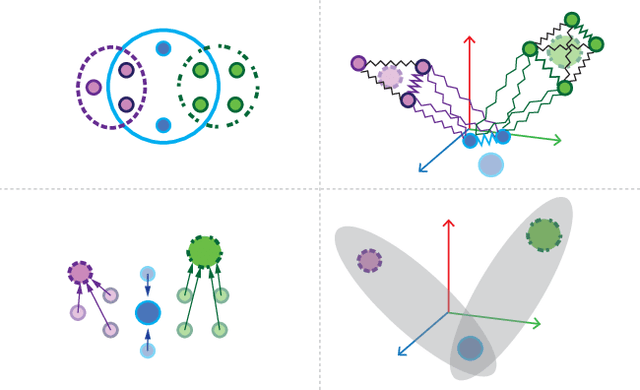

Many problems such as vertex classification andlink prediction in network data can be solvedusing graph embeddings, and a number of algo-rithms are known for constructing such embed-dings. However, it is difficult to use graphs tocapture non-binary relations such as communitiesof vertices. These kinds of complex relations areexpressed more naturally as hypergraphs. Whilehypergraphs are a generalization of graphs, state-of-the-art graph embedding techniques are notadequate for solving prediction and classificationtasks on large hypergraphs accurately in reason-able time. In this paper, we introduce NetVec,a novel multi-level framework for scalable un-supervised hypergraph embedding, that can becoupled with any graph embedding algorithm toproduce embeddings of hypergraphs with millionsof nodes and hyperedges in a few minutes.