 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Fair Feature Selection in Machine Learning for Healthcare
Paper and Code
Apr 01, 2024
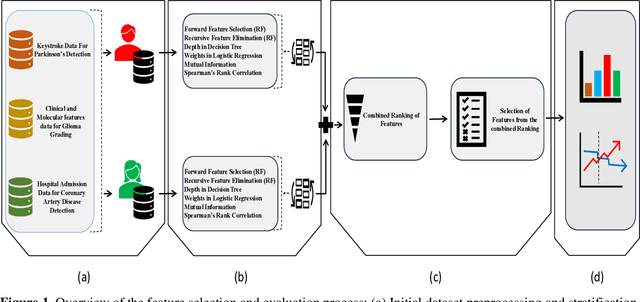
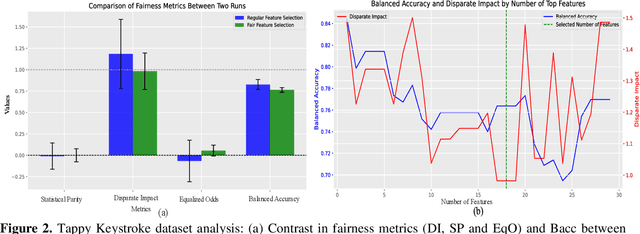
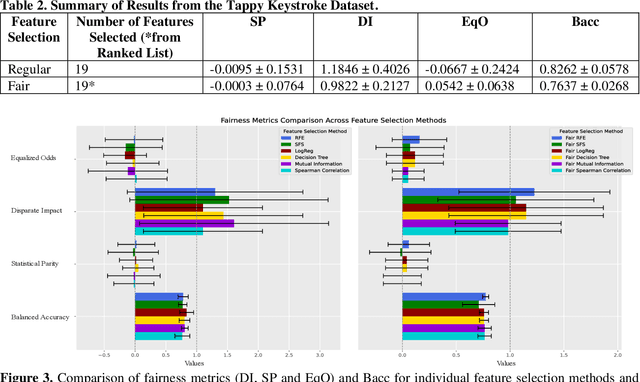
With the universal adoption of machine learning in healthcare, the potential for the automation of societal biases to further exacerbate health disparities poses a significant risk. We explore algorithmic fairness from the perspective of feature selection. Traditional feature selection methods identify features for better decision making by removing resource-intensive, correlated, or non-relevant features but overlook how these factors may differ across subgroups. To counter these issues, we evaluate a fair feature selection method that considers equal importance to all demographic groups. We jointly considered a fairness metric and an error metric within the feature selection process to ensure a balance between minimizing both bias and global classification error. We tested our approach on three publicly available healthcare datasets. On all three datasets, we observed improvements in fairness metrics coupled with a minimal degradation of balanced accuracy. Our approach addresses both distributive and procedural fairness within the fair machine learning context.