 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRhythm: Learning Interactive Whole-Body Control for Dual Humanoids
Mar 03, 2026Realizing interactive whole-body control for multi-humanoid systems is critical for unlocking complex collaborative capabilities in shared environments. Although recent advancements have significantly enhanced the agility of individual robots, bridging the gap to physically coupled multi-humanoid interaction remains challenging, primarily due to severe kinematic mismatches and complex contact dynamics. To address this, we introduce Rhythm, the first unified framework enabling real-world deployment of dual-humanoid systems for complex, physically plausible interactions. Our framework integrates three core components: (1) an Interaction-Aware Motion Retargeting (IAMR) module that generates feasible humanoid interaction references from human data; (2) an Interaction-Guided Reinforcement Learning (IGRL) policy that masters coupled dynamics via graph-based rewards; and (3) a real-world deployment system that enables robust transfer of dual-humanoid interaction. Extensive experiments on physical Unitree G1 robots demonstrate that our framework achieves robust interactive whole-body control, successfully transferring diverse behaviors such as hugging and dancing from simulation to reality.
World In Your Hands: A Large-Scale and Open-source Ecosystem for Learning Human-centric Manipulation in the Wild
Dec 30, 2025Large-scale pre-training is fundamental for generalization in language and vision models, but data for dexterous hand manipulation remains limited in scale and diversity, hindering policy generalization. Limited scenario diversity, misaligned modalities, and insufficient benchmarking constrain current human manipulation datasets. To address these gaps, we introduce World In Your Hands (WiYH), a large-scale open-source ecosystem for human-centric manipulation learning. WiYH includes (1) the Oracle Suite, a wearable data collection kit with an auto-labeling pipeline for accurate motion capture; (2) the WiYH Dataset, featuring over 1,000 hours of multi-modal manipulation data across hundreds of skills in diverse real-world scenarios; and (3) extensive annotations and benchmarks supporting tasks from perception to action. Furthermore, experiments based on the WiYH ecosystem show that integrating WiYH's human-centric data significantly enhances the generalization and robustness of dexterous hand policies in tabletop manipulation tasks. We believe that World In Your Hands will bring new insights into human-centric data collection and policy learning to the community.
Stackelberg Game Preference Optimization for Data-Efficient Alignment of Language Models
Feb 25, 2025Aligning language models with human preferences is critical for real-world deployment, but existing methods often require large amounts of high-quality human annotations. Aiming at a data-efficient alignment method, we propose Stackelberg Game Preference Optimization (SGPO), a framework that models alignment as a two-player Stackelberg game, where a policy (leader) optimizes against a worst-case preference distribution (follower) within an $\epsilon$-Wasserstein ball, ensuring robustness to (self-)annotation noise and distribution shifts. SGPO guarantees $O(\epsilon)$-bounded regret, unlike Direct Preference Optimization (DPO), which suffers from linear regret growth in the distribution mismatch. We instantiate SGPO with the Stackelberg Self-Annotated Preference Optimization (SSAPO) algorithm, which iteratively self-annotates preferences and adversarially reweights synthetic annotated preferences. Using only 2K seed preferences, from the UltraFeedback dataset, i.e., 1/30 of human labels in the dataset, our method achieves 35.82% GPT-4 win-rate with Mistral-7B and 40.12% with Llama3-8B-Instruct within three rounds of SSAPO.
IntelliCare: Improving Healthcare Analysis with Variance-Controlled Patient-Level Knowledge from Large Language Models
Aug 23, 2024While pioneering deep learning methods have made great strides in analyzing electronic health record (EHR) data, they often struggle to fully capture the semantics of diverse medical codes from limited data. The integration of external knowledge from Large Language Models (LLMs) presents a promising avenue for improving healthcare predictions. However, LLM analyses may exhibit significant variance due to ambiguity problems and inconsistency issues, hindering their effective utilization. To address these challenges, we propose IntelliCare, a novel framework that leverages LLMs to provide high-quality patient-level external knowledge and enhance existing EHR models. Concretely, IntelliCare identifies patient cohorts and employs task-relevant statistical information to augment LLM understanding and generation, effectively mitigating the ambiguity problem. Additionally, it refines LLM-derived knowledge through a hybrid approach, generating multiple analyses and calibrating them using both the EHR model and perplexity measures. Experimental evaluations on three clinical prediction tasks across two large-scale EHR datasets demonstrate that IntelliCare delivers significant performance improvements to existing methods, highlighting its potential in advancing personalized healthcare predictions and decision support systems.
SMART: Towards Pre-trained Missing-Aware Model for Patient Health Status Prediction
May 15, 2024



Electronic health record (EHR) data has emerged as a valuable resource for analyzing patient health status. However, the prevalence of missing data in EHR poses significant challenges to existing methods, leading to spurious correlations and suboptimal predictions. While various imputation techniques have been developed to address this issue, they often obsess unnecessary details and may introduce additional noise when making clinical predictions. To tackle this problem, we propose SMART, a Self-Supervised Missing-Aware RepresenTation Learning approach for patient health status prediction, which encodes missing information via elaborated attentions and learns to impute missing values through a novel self-supervised pre-training approach that reconstructs missing data representations in the latent space. By adopting missing-aware attentions and focusing on learning higher-order representations, SMART promotes better generalization and robustness to missing data. We validate the effectiveness of SMART through extensive experiments on six EHR tasks, demonstrating its superiority over state-of-the-art methods.
LoRA Dropout as a Sparsity Regularizer for Overfitting Control
Apr 15, 2024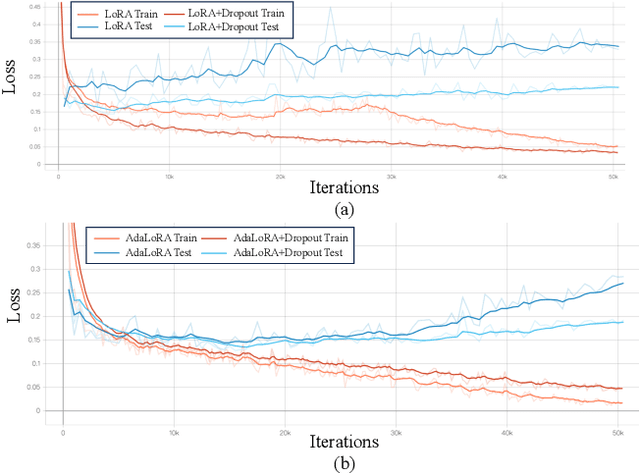
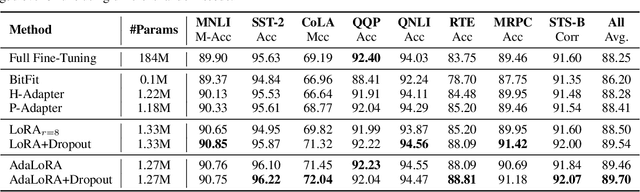
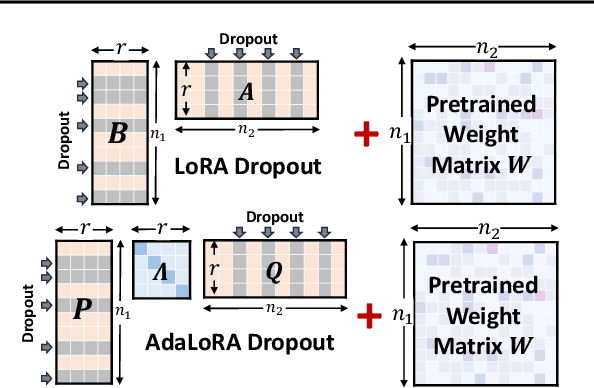
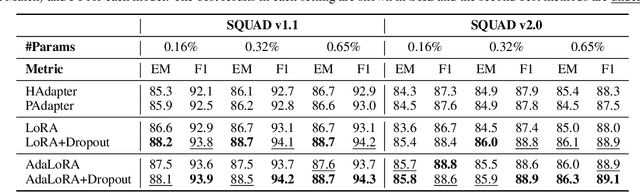
Parameter-efficient fine-tuning methods, represented by LoRA, play an essential role in adapting large-scale pre-trained models to downstream tasks. However, fine-tuning LoRA-series models also faces the risk of overfitting on the training dataset, and yet there's still a lack of theoretical guidance and practical mechanism to control overfitting on LoRA-based PEFT methods. In this paper, we propose a LoRA Dropout mechanism for the LoRA-based methods by introducing random noises to the learnable low-rank matrices and increasing parameter sparsity. We then demonstrate the theoretical mechanism of our LoRA Dropout mechanism from the perspective of sparsity regularization by providing a generalization error bound under this framework. Theoretical results show that appropriate sparsity would help tighten the gap between empirical and generalization risks and thereby control overfitting. Furthermore, based on the LoRA Dropout framework, we introduce a test-time ensemble strategy and provide theoretical evidence demonstrating that the ensemble method can further compress the error bound, and lead to better performance during inference time. Extensive experiments on various NLP tasks provide practical validations of the effectiveness of our LoRA Dropout framework in improving model accuracy and calibration.
Domain Generalization through the Lens of Angular Invariance
Oct 28, 2022



Domain generalization (DG) aims at generalizing a classifier trained on multiple source domains to an unseen target domain with domain shift. A common pervasive theme in existing DG literature is domain-invariant representation learning with various invariance assumptions. However, prior works restrict themselves to a radical assumption for realworld challenges: If a mapping induced by a deep neural network (DNN) could align the source domains well, then such a mapping aligns a target domain as well. In this paper, we simply take DNNs as feature extractors to relax the requirement of distribution alignment. Specifically, we put forward a novel angular invariance and the accompanied norm shift assumption. Based on the proposed term of invariance, we propose a novel deep DG method called Angular Invariance Domain Generalization Network (AIDGN). The optimization objective of AIDGN is developed with a von-Mises Fisher (vMF) mixture model. Extensive experiments on multiple DG benchmark datasets validate the effectiveness of the proposed AIDGN method.