 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially and Robustly Hybrid Mixture Regression Model for Inference of Spatial Dependence
Sep 28, 2021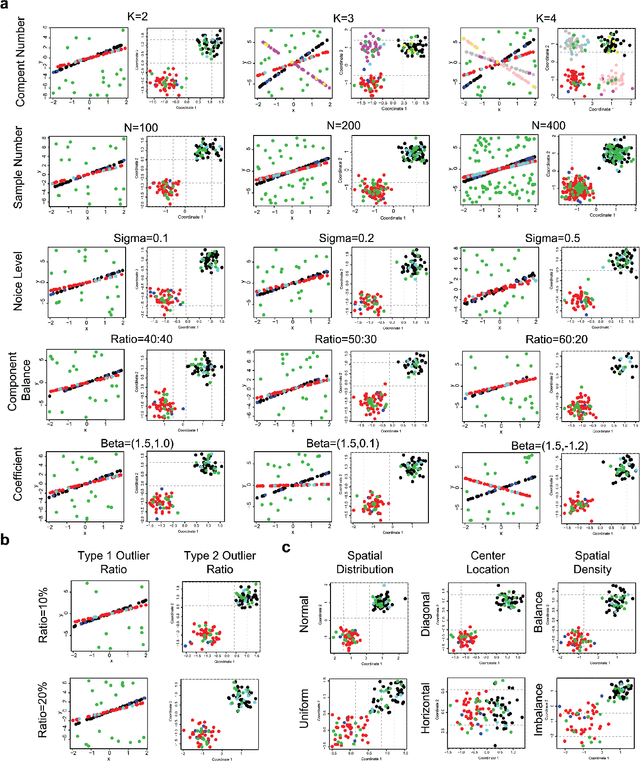
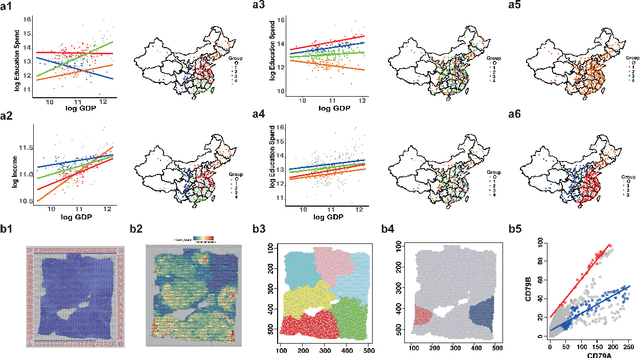
In this paper, we propose a Spatial Robust Mixture Regression model to investigate the relationship between a response variable and a set of explanatory variables over the spatial domain, assuming that the relationships may exhibit complex spatially dynamic patterns that cannot be captured by constant regression coefficients. Our method integrates the robust finite mixture Gaussian regression model with spatial constraints, to simultaneously handle the spatial nonstationarity, local homogeneity, and outlier contaminations. Compared with existing spatial regression models, our proposed model assumes the existence a few distinct regression models that are estimated based on observations that exhibit similar response-predictor relationships. As such, the proposed model not only accounts for nonstationarity in the spatial trend, but also clusters observations into a few distinct and homogenous groups. This provides an advantage on interpretation with a few stationary sub-processes identified that capture the predominant relationships between response and predictor variables. Moreover, the proposed method incorporates robust procedures to handle contaminations from both regression outliers and spatial outliers. By doing so, we robustly segment the spatial domain into distinct local regions with similar regression coefficients, and sporadic locations that are purely outliers. Rigorous statistical hypothesis testing procedure has been designed to test the significance of such segmentation. Experimental results on many synthetic and real-world datasets demonstrate the robustness, accuracy, and effectiveness of our proposed method, compared with other robust finite mixture regression, spatial regression and spatial segmentation methods.
Supervised clustering of high dimensional data using regularized mixture modeling
Jul 19, 2020
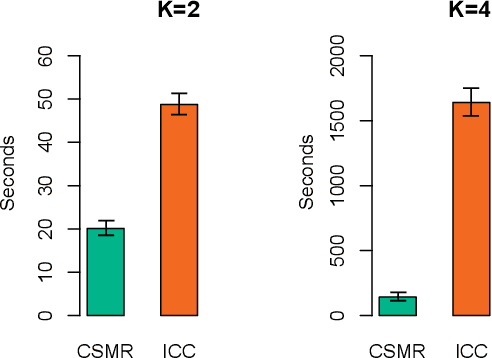
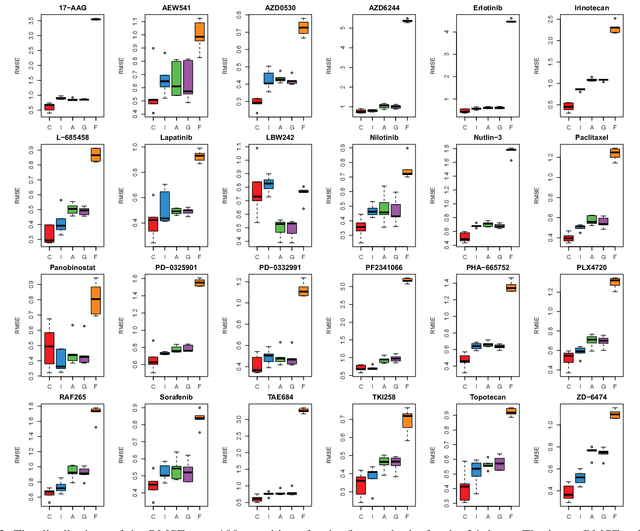
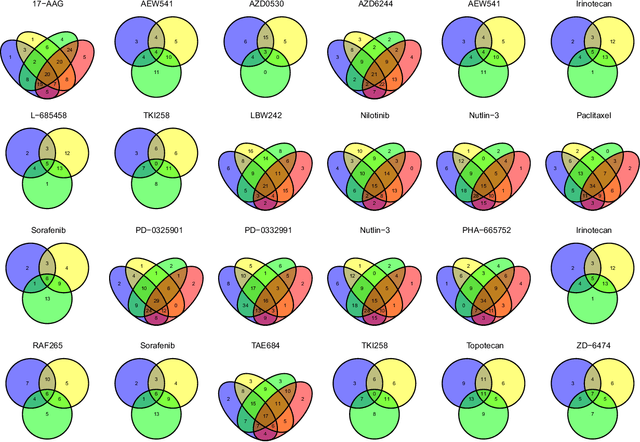
Identifying relationships between molecular variations and their clinical presentations has been challenged by the heterogeneous causes of a disease. It is imperative to unveil the relationship between the high dimensional molecular manifestations and the clinical presentations, while taking into account the possible heterogeneity of the study subjects. We proposed a novel supervised clustering algorithm using penalized mixture regression model, called CSMR, to deal with the challenges in studying the heterogeneous relationships between high dimensional molecular features to a phenotype. The algorithm was adapted from the classification expectation maximization algorithm, which offers a novel supervised solution to the clustering problem, with substantial improvement on both the computational efficiency and biological interpretability. Experimental evaluation on simulated benchmark datasets demonstrated that the CSMR can accurately identify the subspaces on which subset of features are explanatory to the response variables, and it outperformed the baseline methods. Application of CSMR on a drug sensitivity dataset again demonstrated the superior performance of CSMR over the others, where CSMR is powerful in recapitulating the distinct subgroups hidden in the pool of cell lines with regards to their coping mechanisms to different drugs. CSMR represents a big data analysis tool with the potential to resolve the complexity of translating the clinical manifestations of the disease to the real causes underpinning it. We believe that it will bring new understanding to the molecular basis of a disease, and could be of special relevance in the growing field of personalized medicine.
A New Algorithm using Component-wise Adaptive Trimming For Robust Mixture Regression
Jun 10, 2020
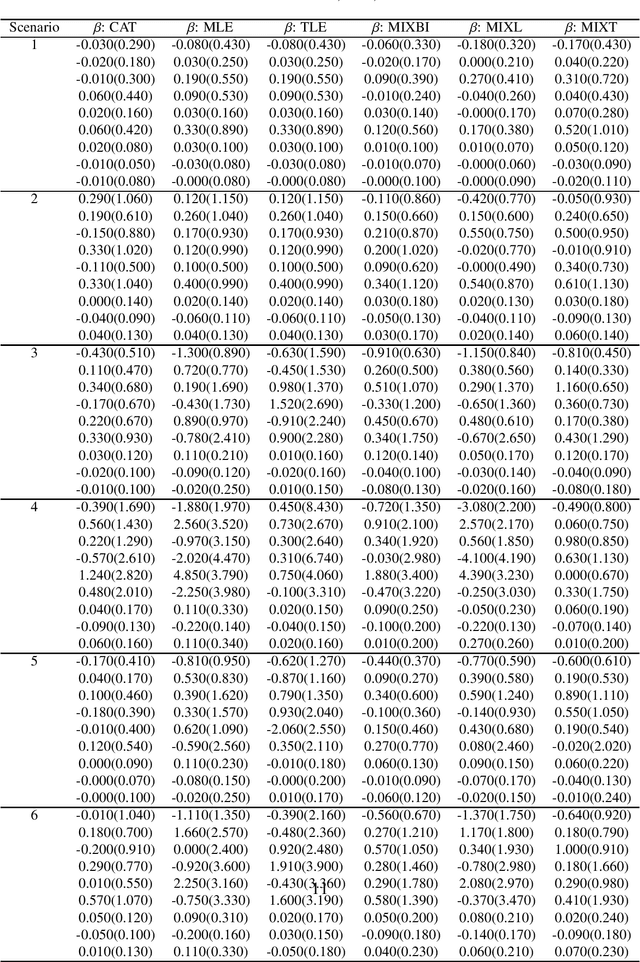
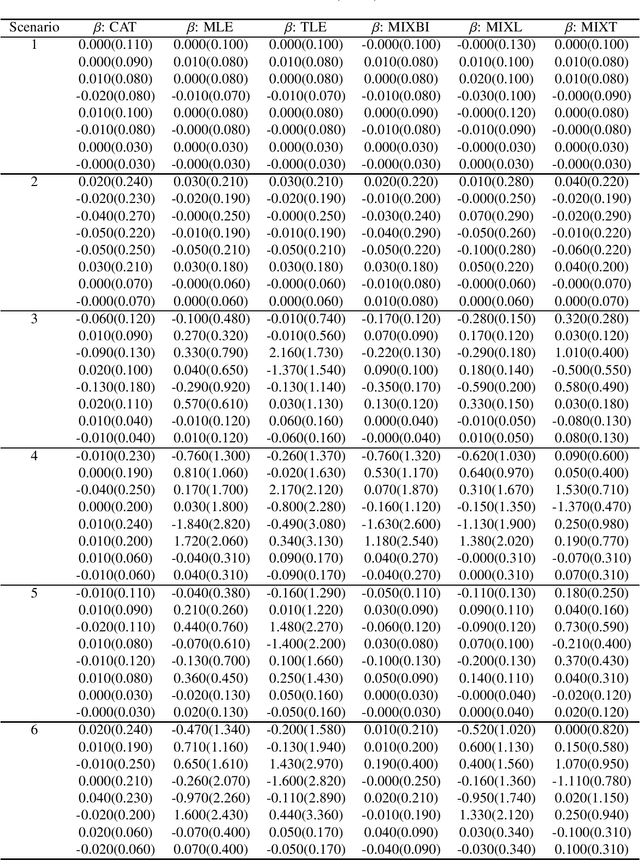

Mixture regression provides a statistical model for teasing out latent heterogeneous relationships between response and independent variables. Solving mixture regression relying on EM algorithm is highly sensitive to outliers. To enable simultaneous outlier detection and robust parameter estimation, we proposed a fast and efficient robust mixture regression algorithm, considering Component-wise Adaptive Trimming (CAT). Compared with multiple existing algorithms, it grasps a good balance of computational efficiency and robustness, in different scenarios of simulated data, where unequal component proportions and variances, different levels of outlier contaminations and sample sizes, occur. The adaptive trimming ability of CAT makes it a highly potential tool for mining the latent relationships among variables in the big data era. CAT has been implemented in an R package 'RobMixReg' available in CRAN.