 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-Constraint In-Context Generation for Instructional Video Editing
Dec 19, 2025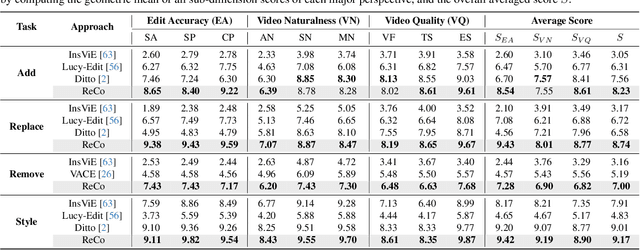
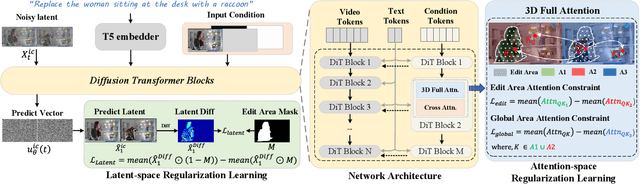

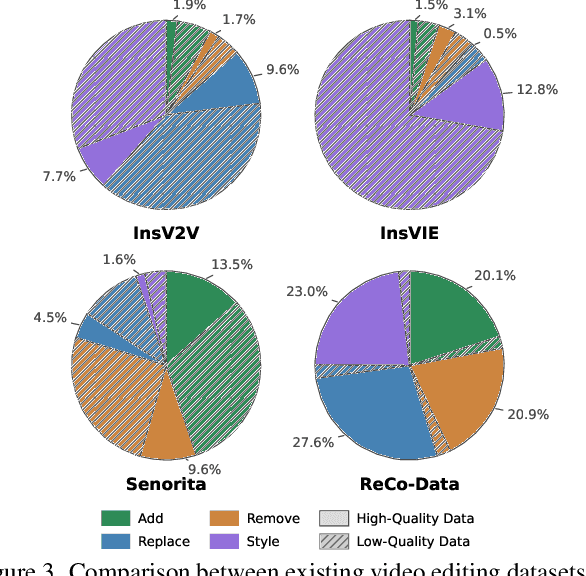
The In-context generation paradigm recently has demonstrated strong power in instructional image editing with both data efficiency and synthesis quality. Nevertheless, shaping such in-context learning for instruction-based video editing is not trivial. Without specifying editing regions, the results can suffer from the problem of inaccurate editing regions and the token interference between editing and non-editing areas during denoising. To address these, we present ReCo, a new instructional video editing paradigm that novelly delves into constraint modeling between editing and non-editing regions during in-context generation. Technically, ReCo width-wise concatenates source and target video for joint denoising. To calibrate video diffusion learning, ReCo capitalizes on two regularization terms, i.e., latent and attention regularization, conducting on one-step backward denoised latents and attention maps, respectively. The former increases the latent discrepancy of the editing region between source and target videos while reducing that of non-editing areas, emphasizing the modification on editing area and alleviating outside unexpected content generation. The latter suppresses the attention of tokens in the editing region to the tokens in counterpart of the source video, thereby mitigating their interference during novel object generation in target video. Furthermore, we propose a large-scale, high-quality video editing dataset, i.e., ReCo-Data, comprising 500K instruction-video pairs to benefit model training. Extensive experiments conducted on four major instruction-based video editing tasks demonstrate the superiority of our proposal.
MotionPro: A Precise Motion Controller for Image-to-Video Generation
May 26, 2025



Animating images with interactive motion control has garnered popularity for image-to-video (I2V) generation. Modern approaches typically rely on large Gaussian kernels to extend motion trajectories as condition without explicitly defining movement region, leading to coarse motion control and failing to disentangle object and camera moving. To alleviate these, we present MotionPro, a precise motion controller that novelly leverages region-wise trajectory and motion mask to regulate fine-grained motion synthesis and identify target motion category (i.e., object or camera moving), respectively. Technically, MotionPro first estimates the flow maps on each training video via a tracking model, and then samples the region-wise trajectories to simulate inference scenario. Instead of extending flow through large Gaussian kernels, our region-wise trajectory approach enables more precise control by directly utilizing trajectories within local regions, thereby effectively characterizing fine-grained movements. A motion mask is simultaneously derived from the predicted flow maps to capture the holistic motion dynamics of the movement regions. To pursue natural motion control, MotionPro further strengthens video denoising by incorporating both region-wise trajectories and motion mask through feature modulation. More remarkably, we meticulously construct a benchmark, i.e., MC-Bench, with 1.1K user-annotated image-trajectory pairs, for the evaluation of both fine-grained and object-level I2V motion control. Extensive experiments conducted on WebVid-10M and MC-Bench demonstrate the effectiveness of MotionPro. Please refer to our project page for more results: https://zhw-zhang.github.io/MotionPro-page/.
Validating Deep-Learning Weather Forecast Models on Recent High-Impact Extreme Events
Apr 26, 2024



The forecast accuracy of deep-learning-based weather prediction models is improving rapidly, leading many to speak of a "second revolution in weather forecasting". With numerous methods being developed, and limited physical guarantees offered by deep-learning models, there is a critical need for comprehensive evaluation of these emerging techniques. While this need has been partly fulfilled by benchmark datasets, they provide little information on rare and impactful extreme events, or on compound impact metrics, for which model accuracy might degrade due to misrepresented dependencies between variables. To address these issues, we compare deep-learning weather prediction models (GraphCast, PanguWeather, FourCastNet) and ECMWF's high-resolution forecast (HRES) system in three case studies: the 2021 Pacific Northwest heatwave, the 2023 South Asian humid heatwave, and the North American winter storm in 2021. We find evidence that machine learning (ML) weather prediction models can locally achieve similar accuracy to HRES on record-shattering events such as the 2021 Pacific Northwest heatwave and even forecast the compound 2021 North American winter storm substantially better. However, extrapolating to extreme conditions may impact machine learning models more severely than HRES, as evidenced by the comparable or superior spatially- and temporally-aggregated forecast accuracy of HRES for the two heatwaves studied. The ML forecasts also lack variables required to assess the health risks of events such as the 2023 South Asian humid heatwave. Generally, case-study-driven, impact-centric evaluation can complement existing research, increase public trust, and aid in developing reliable ML weather prediction models.
TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models
Mar 25, 2024Recent advances in text-to-video generation have demonstrated the utility of powerful diffusion models. Nevertheless, the problem is not trivial when shaping diffusion models to animate static image (i.e., image-to-video generation). The difficulty originates from the aspect that the diffusion process of subsequent animated frames should not only preserve the faithful alignment with the given image but also pursue temporal coherence among adjacent frames. To alleviate this, we present TRIP, a new recipe of image-to-video diffusion paradigm that pivots on image noise prior derived from static image to jointly trigger inter-frame relational reasoning and ease the coherent temporal modeling via temporal residual learning. Technically, the image noise prior is first attained through one-step backward diffusion process based on both static image and noised video latent codes. Next, TRIP executes a residual-like dual-path scheme for noise prediction: 1) a shortcut path that directly takes image noise prior as the reference noise of each frame to amplify the alignment between the first frame and subsequent frames; 2) a residual path that employs 3D-UNet over noised video and static image latent codes to enable inter-frame relational reasoning, thereby easing the learning of the residual noise for each frame. Furthermore, both reference and residual noise of each frame are dynamically merged via attention mechanism for final video generation. Extensive experiments on WebVid-10M, DTDB and MSR-VTT datasets demonstrate the effectiveness of our TRIP for image-to-video generation. Please see our project page at https://trip-i2v.github.io/TRIP/.