 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Visual Correspondence into Diffusion Model for Virtual Try-On
May 22, 2025



Diffusion models have shown preliminary success in virtual try-on (VTON) task. The typical dual-branch architecture comprises two UNets for implicit garment deformation and synthesized image generation respectively, and has emerged as the recipe for VTON task. Nevertheless, the problem remains challenging to preserve the shape and every detail of the given garment due to the intrinsic stochasticity of diffusion model. To alleviate this issue, we novelly propose to explicitly capitalize on visual correspondence as the prior to tame diffusion process instead of simply feeding the whole garment into UNet as the appearance reference. Specifically, we interpret the fine-grained appearance and texture details as a set of structured semantic points, and match the semantic points rooted in garment to the ones over target person through local flow warping. Such 2D points are then augmented into 3D-aware cues with depth/normal map of target person. The correspondence mimics the way of putting clothing on human body and the 3D-aware cues act as semantic point matching to supervise diffusion model training. A point-focused diffusion loss is further devised to fully take the advantage of semantic point matching. Extensive experiments demonstrate strong garment detail preservation of our approach, evidenced by state-of-the-art VTON performances on both VITON-HD and DressCode datasets. Code is publicly available at: https://github.com/HiDream-ai/SPM-Diff.
Improving Virtual Try-On with Garment-focused Diffusion Models
Sep 12, 2024


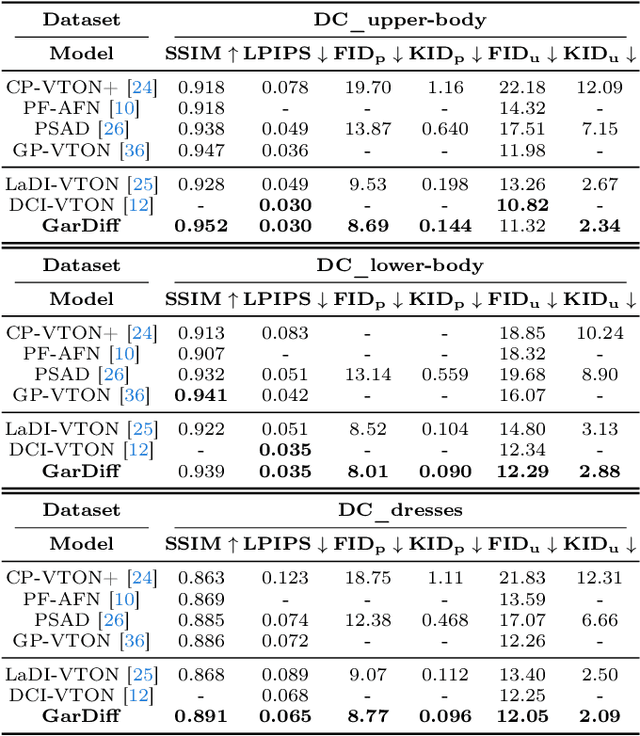
Diffusion models have led to the revolutionizing of generative modeling in numerous image synthesis tasks. Nevertheless, it is not trivial to directly apply diffusion models for synthesizing an image of a target person wearing a given in-shop garment, i.e., image-based virtual try-on (VTON) task. The difficulty originates from the aspect that the diffusion process should not only produce holistically high-fidelity photorealistic image of the target person, but also locally preserve every appearance and texture detail of the given garment. To address this, we shape a new Diffusion model, namely GarDiff, which triggers the garment-focused diffusion process with amplified guidance of both basic visual appearance and detailed textures (i.e., high-frequency details) derived from the given garment. GarDiff first remoulds a pre-trained latent diffusion model with additional appearance priors derived from the CLIP and VAE encodings of the reference garment. Meanwhile, a novel garment-focused adapter is integrated into the UNet of diffusion model, pursuing local fine-grained alignment with the visual appearance of reference garment and human pose. We specifically design an appearance loss over the synthesized garment to enhance the crucial, high-frequency details. Extensive experiments on VITON-HD and DressCode datasets demonstrate the superiority of our GarDiff when compared to state-of-the-art VTON approaches. Code is publicly available at: \href{https://github.com/siqi0905/GarDiff/tree/master}{https://github.com/siqi0905/GarDiff/tree/master}.