 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Need a Transition Plane: Bridging Continuous Panoramic 3D Reconstruction with Perspective Gaussian Splatting
Apr 12, 2025Recently, reconstructing scenes from a single panoramic image using advanced 3D Gaussian Splatting (3DGS) techniques has attracted growing interest. Panoramic images offer a 360$\times$ 180 field of view (FoV), capturing the entire scene in a single shot. However, panoramic images introduce severe distortion, making it challenging to render 3D Gaussians into 2D distorted equirectangular space directly. Converting equirectangular images to cubemap projections partially alleviates this problem but introduces new challenges, such as projection distortion and discontinuities across cube-face boundaries. To address these limitations, we present a novel framework, named TPGS, to bridge continuous panoramic 3D scene reconstruction with perspective Gaussian splatting. Firstly, we introduce a Transition Plane between adjacent cube faces to enable smoother transitions in splatting directions and mitigate optimization ambiguity in the boundary region. Moreover, an intra-to-inter face optimization strategy is proposed to enhance local details and restore visual consistency across cube-face boundaries. Specifically, we optimize 3D Gaussians within individual cube faces and then fine-tune them in the stitched panoramic space. Additionally, we introduce a spherical sampling technique to eliminate visible stitching seams. Extensive experiments on indoor and outdoor, egocentric, and roaming benchmark datasets demonstrate that our approach outperforms existing state-of-the-art methods. Code and models will be available at https://github.com/zhijieshen-bjtu/TPGS.
What Really Matters for Learning-based LiDAR-Camera Calibration
Jan 28, 2025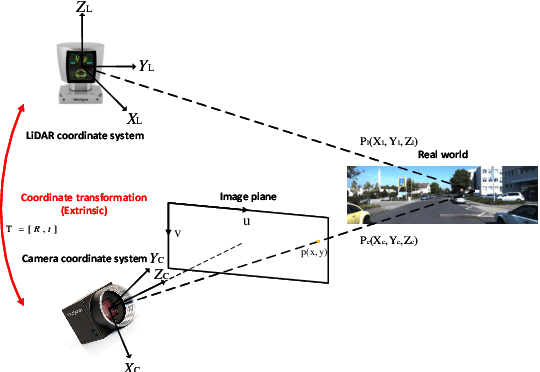
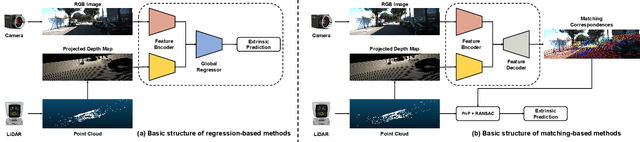
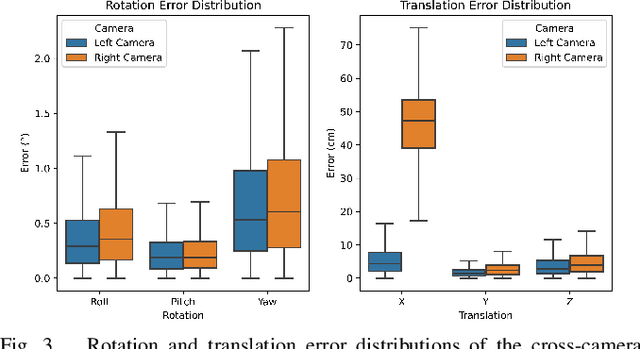
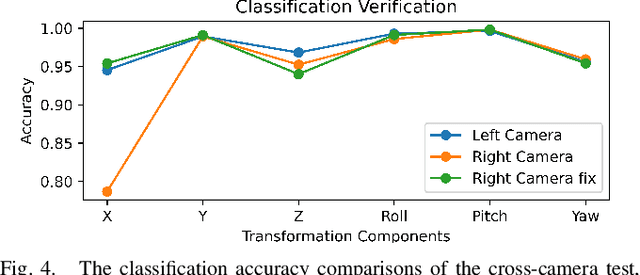
Calibration is an essential prerequisite for the accurate data fusion of LiDAR and camera sensors. Traditional calibration techniques often require specific targets or suitable scenes to obtain reliable 2D-3D correspondences. To tackle the challenge of target-less and online calibration, deep neural networks have been introduced to solve the problem in a data-driven manner. While previous learning-based methods have achieved impressive performance on specific datasets, they still struggle in complex real-world scenarios. Most existing works focus on improving calibration accuracy but overlook the underlying mechanisms. In this paper, we revisit the development of learning-based LiDAR-Camera calibration and encourage the community to pay more attention to the underlying principles to advance practical applications. We systematically analyze the paradigm of mainstream learning-based methods, and identify the critical limitations of regression-based methods with the widely used data generation pipeline. Our findings reveal that most learning-based methods inadvertently operate as retrieval networks, focusing more on single-modality distributions rather than cross-modality correspondences. We also investigate how the input data format and preprocessing operations impact network performance and summarize the regression clues to inform further improvements.
Str-L Pose: Integrating Point and Structured Line for Relative Pose Estimation in Dual-Graph
Aug 28, 2024

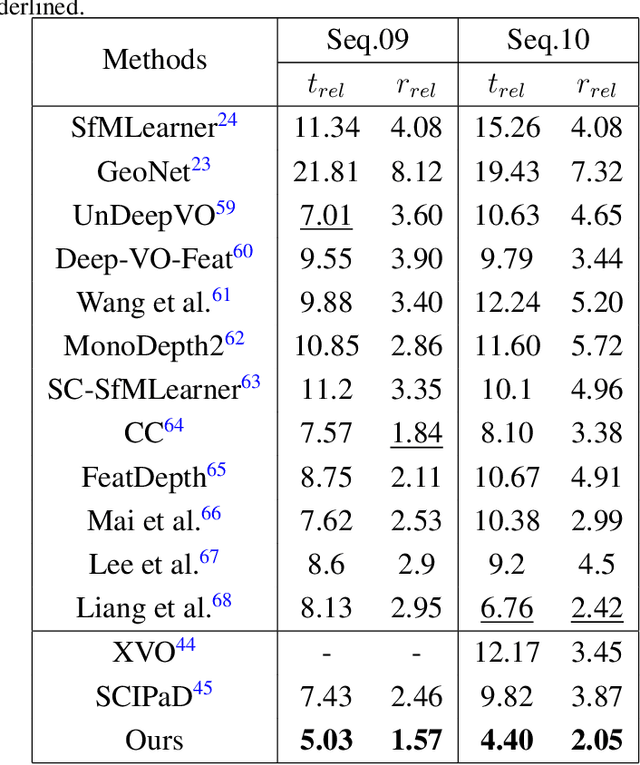

Relative pose estimation is crucial for various computer vision applications, including Robotic and Autonomous Driving. Current methods primarily depend on selecting and matching feature points prone to incorrect matches, leading to poor performance. Consequently, relying solely on point-matching relationships for pose estimation is a huge challenge. To overcome these limitations, we propose a Geometric Correspondence Graph neural network that integrates point features with extra structured line segments. This integration of matched points and line segments further exploits the geometry constraints and enhances model performance across different environments. We employ the Dual-Graph module and Feature Weighted Fusion Module to aggregate geometric and visual features effectively, facilitating complex scene understanding. We demonstrate our approach through extensive experiments on the DeMoN and KITTI Odometry datasets. The results show that our method is competitive with state-of-the-art techniques.
Deep Learning for Camera Calibration and Beyond: A Survey
Mar 19, 2023



Camera calibration involves estimating camera parameters to infer geometric features from captured sequences, which is crucial for computer vision and robotics. However, conventional calibration is laborious and requires dedicated collection. Recent efforts show that learning-based solutions have the potential to be used in place of the repeatability works of manual calibrations. Among these solutions, various learning strategies, networks, geometric priors, and datasets have been investigated. In this paper, we provide a comprehensive survey of learning-based camera calibration techniques, by analyzing their strengths and limitations. Our main calibration categories include the standard pinhole camera model, distortion camera model, cross-view model, and cross-sensor model, following the research trend and extended applications. As there is no benchmark in this community, we collect a holistic calibration dataset that can serve as a public platform to evaluate the generalization of existing methods. It comprises both synthetic and real-world data, with images and videos captured by different cameras in diverse scenes. Toward the end of this paper, we discuss the challenges and provide further research directions. To our knowledge, this is the first survey for the learning-based camera calibration (spanned 8 years). The summarized methods, datasets, and benchmarks are available and will be regularly updated at https://github.com/KangLiao929/Awesome-Deep-Camera-Calibration.