 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStr-L Pose: Integrating Point and Structured Line for Relative Pose Estimation in Dual-Graph
Aug 28, 2024


Relative pose estimation is crucial for various computer vision applications, including Robotic and Autonomous Driving. Current methods primarily depend on selecting and matching feature points prone to incorrect matches, leading to poor performance. Consequently, relying solely on point-matching relationships for pose estimation is a huge challenge. To overcome these limitations, we propose a Geometric Correspondence Graph neural network that integrates point features with extra structured line segments. This integration of matched points and line segments further exploits the geometry constraints and enhances model performance across different environments. We employ the Dual-Graph module and Feature Weighted Fusion Module to aggregate geometric and visual features effectively, facilitating complex scene understanding. We demonstrate our approach through extensive experiments on the DeMoN and KITTI Odometry datasets. The results show that our method is competitive with state-of-the-art techniques.
Spatiotemporal Deformation Perception for Fisheye Video Rectification
Feb 08, 2023Although the distortion correction of fisheye images has been extensively studied, the correction of fisheye videos is still an elusive challenge. For different frames of the fisheye video, the existing image correction methods ignore the correlation of sequences, resulting in temporal jitter in the corrected video. To solve this problem, we propose a temporal weighting scheme to get a plausible global optical flow, which mitigates the jitter effect by progressively reducing the weight of frames. Subsequently, we observe that the inter-frame optical flow of the video is facilitated to perceive the local spatial deformation of the fisheye video. Therefore, we derive the spatial deformation through the flows of fisheye and distorted-free videos, thereby enhancing the local accuracy of the predicted result. However, the independent correction for each frame disrupts the temporal correlation. Due to the property of fisheye video, a distorted moving object may be able to find its distorted-free pattern at another moment. To this end, a temporal deformation aggregator is designed to reconstruct the deformation correlation between frames and provide a reliable global feature. Our method achieves an end-to-end correction and demonstrates superiority in correction quality and stability compared with the SOTA correction methods.
Dual Diffusion Architecture for Fisheye Image Rectification: Synthetic-to-Real Generalization
Jan 26, 2023
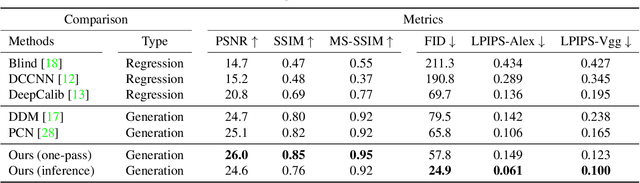
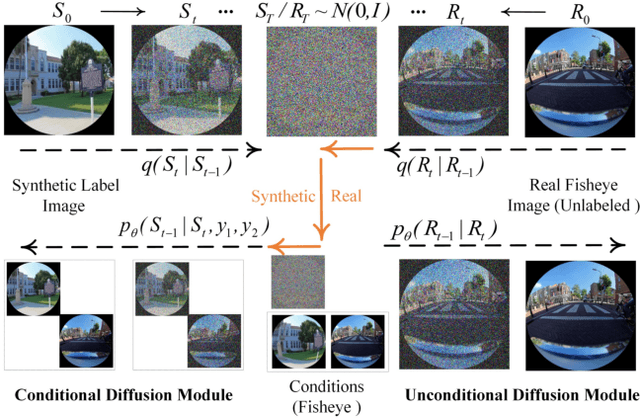
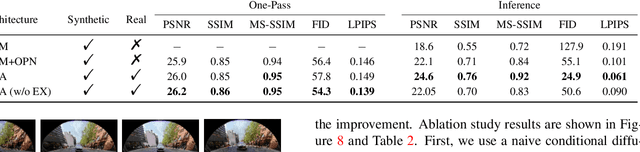
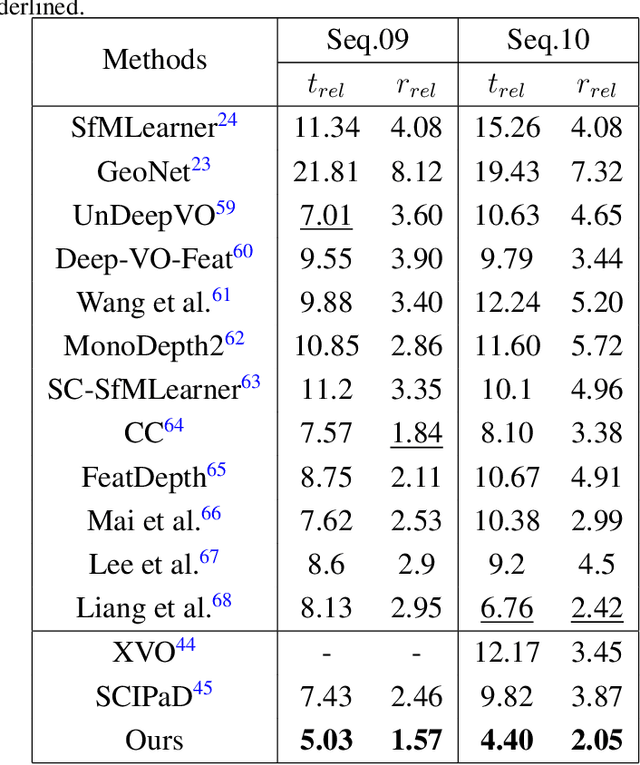
Fisheye image rectification has a long-term unresolved issue with synthetic-to-real generalization. In most previous works, the model trained on the synthetic images obtains unsatisfactory performance on the real-world fisheye image. To this end, we propose a Dual Diffusion Architecture (DDA) for the fisheye rectification with a better generalization ability. The proposed DDA is simultaneously trained with paired synthetic fisheye images and unlabeled real fisheye images. By gradually introducing noises, the synthetic and real fisheye images can eventually develop into a consistent noise distribution, improving the generalization and achieving unlabeled real fisheye correction. The original image serves as the prior guidance in existing DDPMs (Denoising Diffusion Probabilistic Models). However, the non-negligible indeterminate relationship between the prior condition and the target affects the generation performance. Especially in the rectification task, the radial distortion can cause significant artifacts. Therefore, we provide an unsupervised one-pass network that produces a plausible new condition to strengthen guidance. This network can be regarded as an alternate scheme for fast producing reliable results without iterative inference. Compared with the state-of-the-art methods, our approach can reach superior performance in both synthetic and real fisheye image corrections.
FishFormer: Annulus Slicing-based Transformer for Fisheye Rectification with Efficacy Domain Exploration
Jul 05, 2022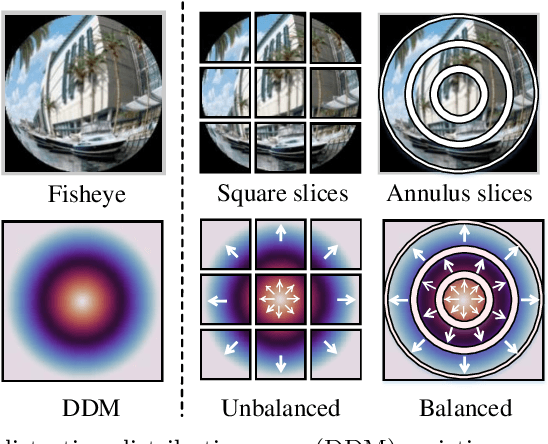
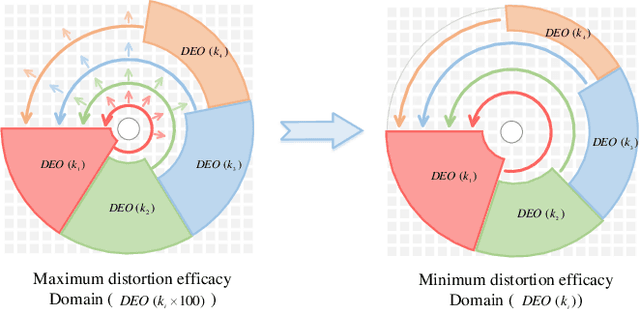
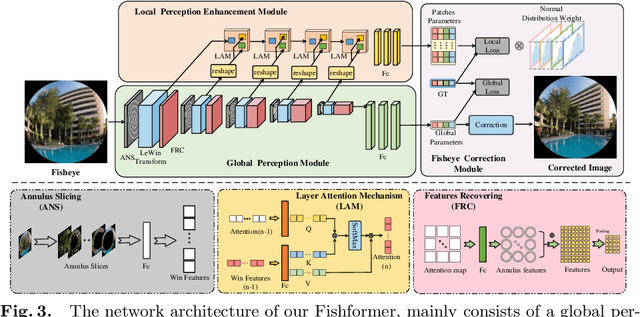
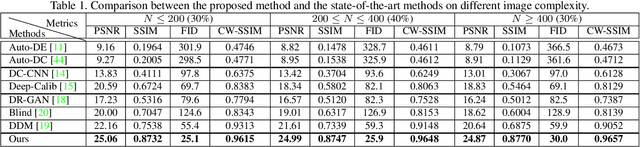
Numerous significant progress on fisheye image rectification has been achieved through CNN. Nevertheless, constrained by a fixed receptive field, the global distribution and the local symmetry of the distortion have not been fully exploited. To leverage these two characteristics, we introduced Fishformer that processes the fisheye image as a sequence to enhance global and local perception. We tuned the Transformer according to the structural properties of fisheye images. First, the uneven distortion distribution in patches generated by the existing square slicing method confuses the network, resulting in difficult training. Therefore, we propose an annulus slicing method to maintain the consistency of the distortion in each patch, thus perceiving the distortion distribution well. Second, we analyze that different distortion parameters have their own efficacy domains. Hence, the perception of the local area is as important as the global, but Transformer has a weakness for local texture perception. Therefore, we propose a novel layer attention mechanism to enhance the local perception and texture transfer. Our network simultaneously implements global perception and focused local perception decided by the different parameters. Extensive experiments demonstrate that our method provides superior performance compared with state-of-the-art methods.
Progressively Complementary Network for Fisheye Image Rectification Using Appearance Flow
Mar 31, 2021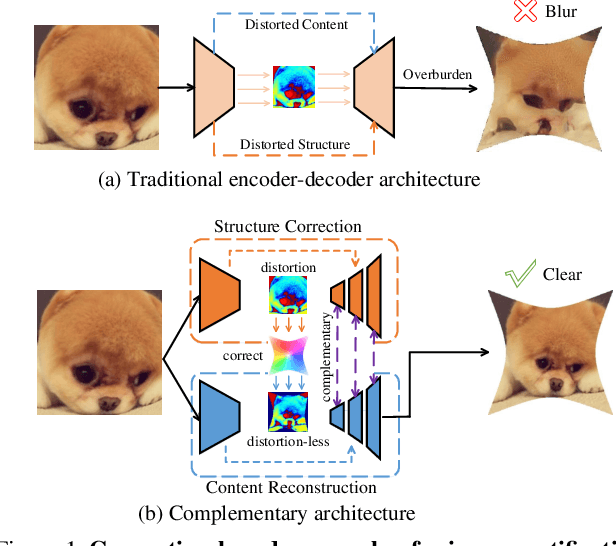
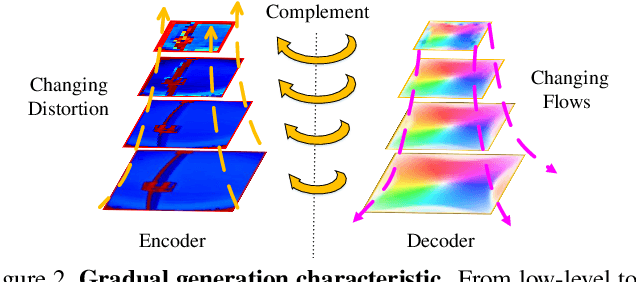
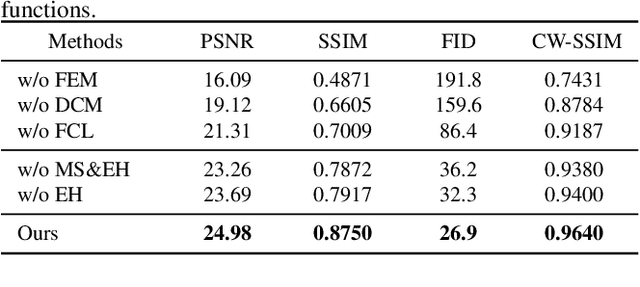
Distortion rectification is often required for fisheye images. The generation-based method is one mainstream solution due to its label-free property, but its naive skip-connection and overburdened decoder will cause blur and incomplete correction. First, the skip-connection directly transfers the image features, which may introduce distortion and cause incomplete correction. Second, the decoder is overburdened during simultaneously reconstructing the content and structure of the image, resulting in vague performance. To solve these two problems, in this paper, we focus on the interpretable correction mechanism of the distortion rectification network and propose a feature-level correction scheme. We embed a correction layer in skip-connection and leverage the appearance flows in different layers to pre-correct the image features. Consequently, the decoder can easily reconstruct a plausible result with the remaining distortion-less information. In addition, we propose a parallel complementary structure. It effectively reduces the burden of the decoder by separating content reconstruction and structure correction. Subjective and objective experiment results on different datasets demonstrate the superiority of our method.