 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Analysis for Visual Object Hallucination in Large Vision-Language Models
May 04, 2025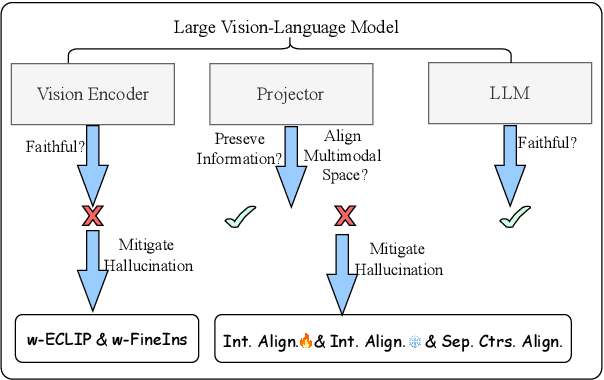
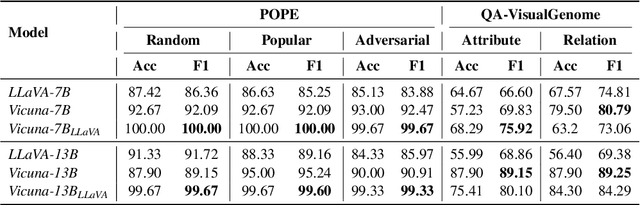

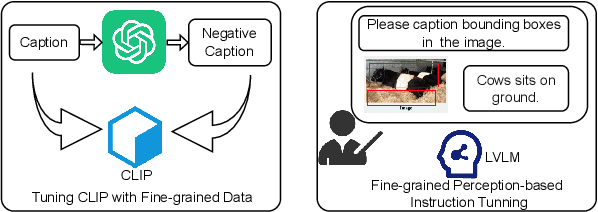
Large Vision-Language Models (LVLMs) demonstrate remarkable capabilities in multimodal tasks, but visual object hallucination remains a persistent issue. It refers to scenarios where models generate inaccurate visual object-related information based on the query input, potentially leading to misinformation and concerns about safety and reliability. Previous works focus on the evaluation and mitigation of visual hallucinations, but the underlying causes have not been comprehensively investigated. In this paper, we analyze each component of LLaVA-like LVLMs -- the large language model, the vision backbone, and the projector -- to identify potential sources of error and their impact. Based on our observations, we propose methods to mitigate hallucination for each problematic component. Additionally, we developed two hallucination benchmarks: QA-VisualGenome, which emphasizes attribute and relation hallucinations, and QA-FB15k, which focuses on cognition-based hallucinations.
Quantifying reliance on external information over parametric knowledge during Retrieval Augmented Generation (RAG) using mechanistic analysis
Oct 01, 2024Retrieval Augmented Generation (RAG) is a widely used approach for leveraging external context in several natural language applications such as question answering and information retrieval. Yet, the exact nature in which a Language Model (LM) leverages this non-parametric memory or retrieved context isn't clearly understood. This paper mechanistically examines the RAG pipeline to highlight that LMs demonstrate a "shortcut'' effect and have a strong bias towards utilizing the retrieved context to answer questions, while relying minimally on model priors. We propose (a) Causal Mediation Analysis; for proving that parametric memory is minimally utilized when answering a question and (b) Attention Contributions and Knockouts for showing the last token residual stream do not get enriched from the subject token in the question, but gets enriched from tokens of RAG-context. We find this pronounced "shortcut'' behaviour to be true across both LLMs (e.g.,LlaMa) and SLMs (e.g., Phi)
From RAGs to rich parameters: Probing how language models utilize external knowledge over parametric information for factual queries
Jun 18, 2024



Retrieval Augmented Generation (RAG) enriches the ability of language models to reason using external context to augment responses for a given user prompt. This approach has risen in popularity due to practical applications in various applications of language models in search, question/answering, and chat-bots. However, the exact nature of how this approach works isn't clearly understood. In this paper, we mechanistically examine the RAG pipeline to highlight that language models take shortcut and have a strong bias towards utilizing only the context information to answer the question, while relying minimally on their parametric memory. We probe this mechanistic behavior in language models with: (i) Causal Mediation Analysis to show that the parametric memory is minimally utilized when answering a question and (ii) Attention Contributions and Knockouts to show that the last token residual stream do not get enriched from the subject token in the question, but gets enriched from other informative tokens in the context. We find this pronounced shortcut behaviour true across both LLaMa and Phi family of models.
DecompX: Explaining Transformers Decisions by Propagating Token Decomposition
Jun 05, 2023



An emerging solution for explaining Transformer-based models is to use vector-based analysis on how the representations are formed. However, providing a faithful vector-based explanation for a multi-layer model could be challenging in three aspects: (1) Incorporating all components into the analysis, (2) Aggregating the layer dynamics to determine the information flow and mixture throughout the entire model, and (3) Identifying the connection between the vector-based analysis and the model's predictions. In this paper, we present DecompX to tackle these challenges. DecompX is based on the construction of decomposed token representations and their successive propagation throughout the model without mixing them in between layers. Additionally, our proposal provides multiple advantages over existing solutions for its inclusion of all encoder components (especially nonlinear feed-forward networks) and the classification head. The former allows acquiring precise vectors while the latter transforms the decomposition into meaningful prediction-based values, eliminating the need for norm- or summation-based vector aggregation. According to the standard faithfulness evaluations, DecompX consistently outperforms existing gradient-based and vector-based approaches on various datasets. Our code is available at https://github.com/mohsenfayyaz/DecompX.
BERT on a Data Diet: Finding Important Examples by Gradient-Based Pruning
Nov 10, 2022Current pre-trained language models rely on large datasets for achieving state-of-the-art performance. However, past research has shown that not all examples in a dataset are equally important during training. In fact, it is sometimes possible to prune a considerable fraction of the training set while maintaining the test performance. Established on standard vision benchmarks, two gradient-based scoring metrics for finding important examples are GraNd and its estimated version, EL2N. In this work, we employ these two metrics for the first time in NLP. We demonstrate that these metrics need to be computed after at least one epoch of fine-tuning and they are not reliable in early steps. Furthermore, we show that by pruning a small portion of the examples with the highest GraNd/EL2N scores, we can not only preserve the test accuracy, but also surpass it. This paper details adjustments and implementation choices which enable GraNd and EL2N to be applied to NLP.
Metaphors in Pre-Trained Language Models: Probing and Generalization Across Datasets and Languages
Mar 26, 2022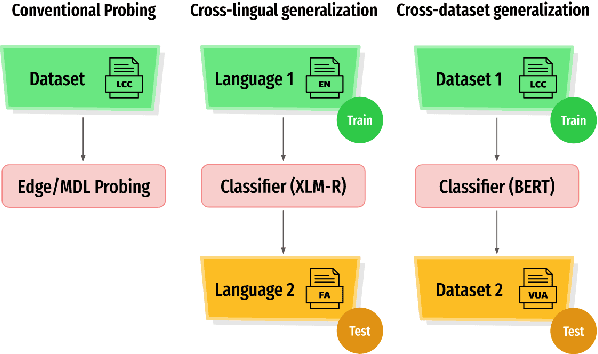

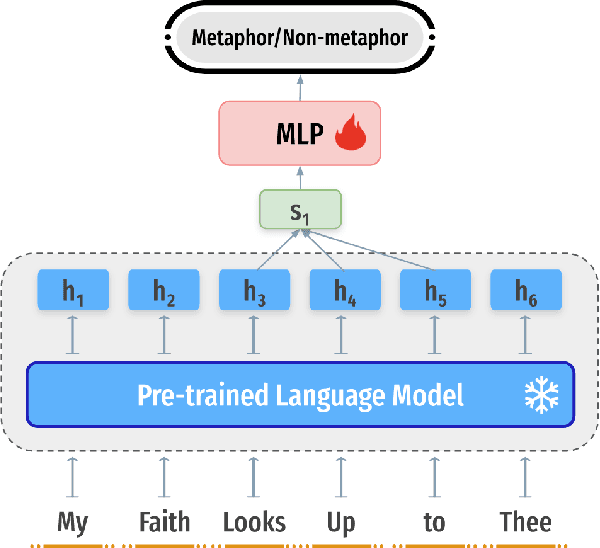
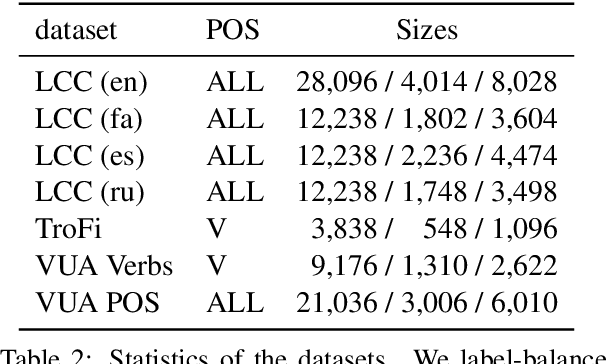
Human languages are full of metaphorical expressions. Metaphors help people understand the world by connecting new concepts and domains to more familiar ones. Large pre-trained language models (PLMs) are therefore assumed to encode metaphorical knowledge useful for NLP systems. In this paper, we investigate this hypothesis for PLMs, by probing metaphoricity information in their encodings, and by measuring the cross-lingual and cross-dataset generalization of this information. We present studies in multiple metaphor detection datasets and in four languages (i.e., English, Spanish, Russian, and Farsi). Our extensive experiments suggest that contextual representations in PLMs do encode metaphorical knowledge, and mostly in their middle layers. The knowledge is transferable between languages and datasets, especially when the annotation is consistent across training and testing sets. Our findings give helpful insights for both cognitive and NLP scientists.
Not All Models Localize Linguistic Knowledge in the Same Place: A Layer-wise Probing on BERToids' Representations
Sep 15, 2021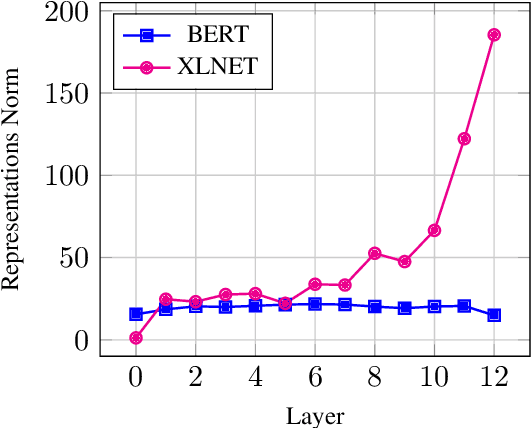

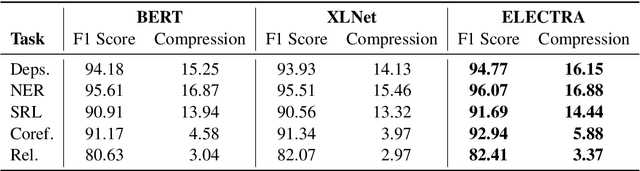
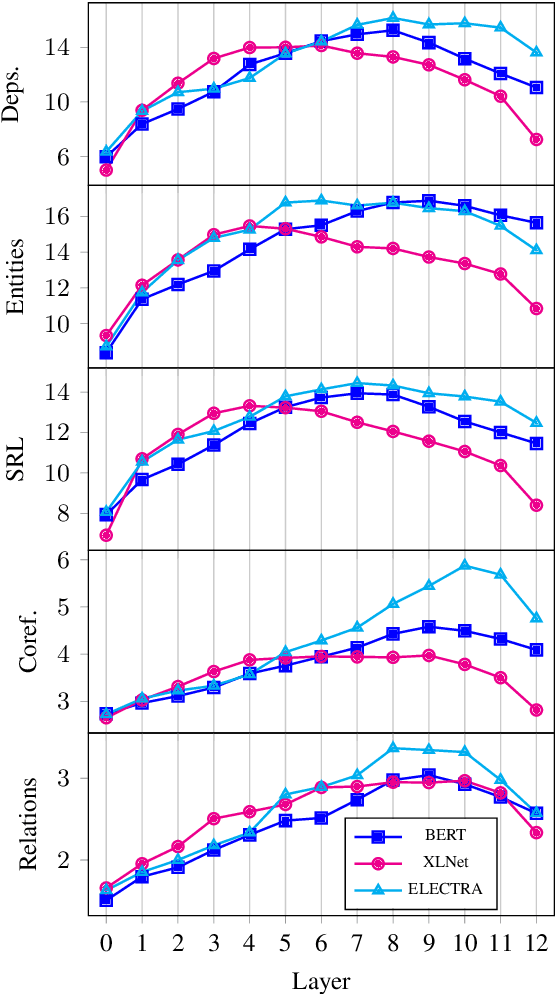
Most of the recent works on probing representations have focused on BERT, with the presumption that the findings might be similar to the other models. In this work, we extend the probing studies to two other models in the family, namely ELECTRA and XLNet, showing that variations in the pre-training objectives or architectural choices can result in different behaviors in encoding linguistic information in the representations. Most notably, we observe that ELECTRA tends to encode linguistic knowledge in the deeper layers, whereas XLNet instead concentrates that in the earlier layers. Also, the former model undergoes a slight change during fine-tuning, whereas the latter experiences significant adjustments. Moreover, we show that drawing conclusions based on the weight mixing evaluation strategy -- which is widely used in the context of layer-wise probing -- can be misleading given the norm disparity of the representations across different layers. Instead, we adopt an alternative information-theoretic probing with minimum description length, which has recently been proven to provide more reliable and informative results.