 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying reliance on external information over parametric knowledge during Retrieval Augmented Generation (RAG) using mechanistic analysis
Oct 01, 2024Retrieval Augmented Generation (RAG) is a widely used approach for leveraging external context in several natural language applications such as question answering and information retrieval. Yet, the exact nature in which a Language Model (LM) leverages this non-parametric memory or retrieved context isn't clearly understood. This paper mechanistically examines the RAG pipeline to highlight that LMs demonstrate a "shortcut'' effect and have a strong bias towards utilizing the retrieved context to answer questions, while relying minimally on model priors. We propose (a) Causal Mediation Analysis; for proving that parametric memory is minimally utilized when answering a question and (b) Attention Contributions and Knockouts for showing the last token residual stream do not get enriched from the subject token in the question, but gets enriched from tokens of RAG-context. We find this pronounced "shortcut'' behaviour to be true across both LLMs (e.g.,LlaMa) and SLMs (e.g., Phi)
From RAGs to rich parameters: Probing how language models utilize external knowledge over parametric information for factual queries
Jun 18, 2024



Retrieval Augmented Generation (RAG) enriches the ability of language models to reason using external context to augment responses for a given user prompt. This approach has risen in popularity due to practical applications in various applications of language models in search, question/answering, and chat-bots. However, the exact nature of how this approach works isn't clearly understood. In this paper, we mechanistically examine the RAG pipeline to highlight that language models take shortcut and have a strong bias towards utilizing only the context information to answer the question, while relying minimally on their parametric memory. We probe this mechanistic behavior in language models with: (i) Causal Mediation Analysis to show that the parametric memory is minimally utilized when answering a question and (ii) Attention Contributions and Knockouts to show that the last token residual stream do not get enriched from the subject token in the question, but gets enriched from other informative tokens in the context. We find this pronounced shortcut behaviour true across both LLaMa and Phi family of models.
Singularity: Planet-Scale, Preemptive and Elastic Scheduling of AI Workloads
Feb 21, 2022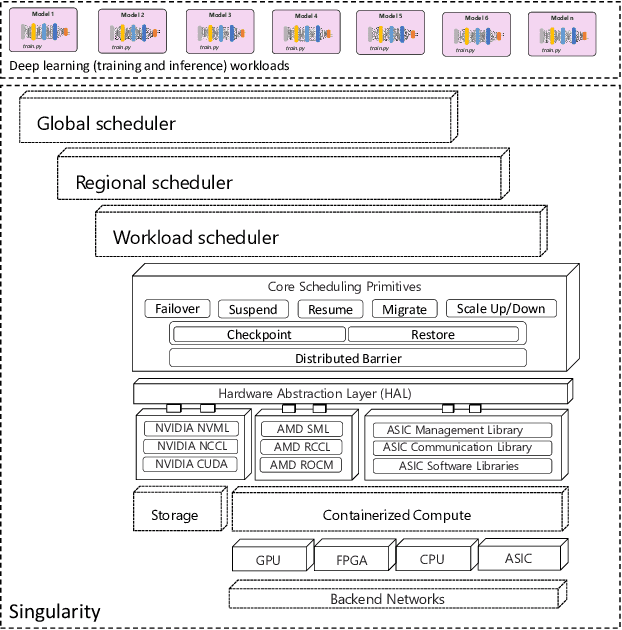
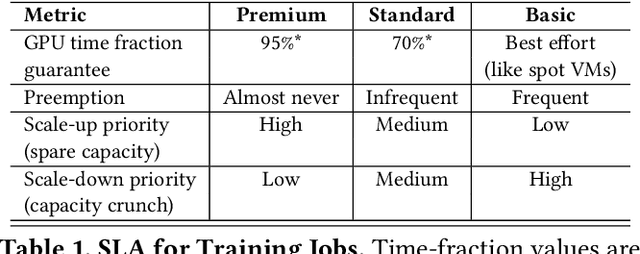
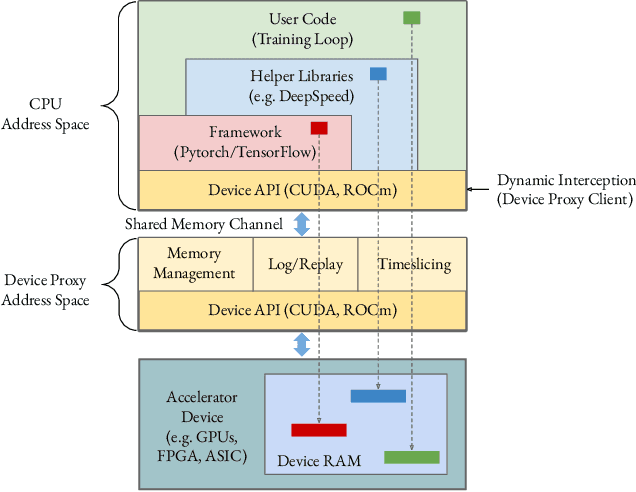
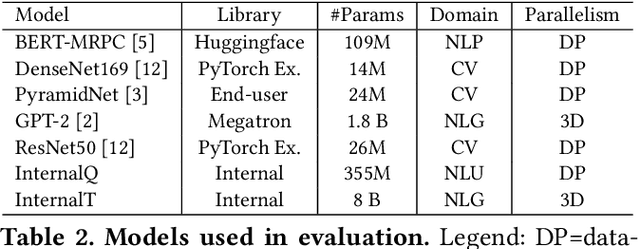
Lowering costs by driving high utilization across deep learning workloads is a crucial lever for cloud providers. We present Singularity, Microsoft's globally distributed scheduling service for highly-efficient and reliable execution of deep learning training and inference workloads. At the heart of Singularity is a novel, workload-aware scheduler that can transparently preempt and elastically scale deep learning workloads to drive high utilization without impacting their correctness or performance, across a global fleet of AI accelerators (e.g., GPUs, FPGAs). All jobs in Singularity are preemptable, migratable, and dynamically resizable (elastic) by default: a live job can be dynamically and transparently (a) preempted and migrated to a different set of nodes, cluster, data center or a region and resumed exactly from the point where the execution was preempted, and (b) resized (i.e., elastically scaled-up/down) on a varying set of accelerators of a given type. Our mechanisms are transparent in that they do not require the user to make any changes to their code or require using any custom libraries that may limit flexibility. Additionally, our approach significantly improves the reliability of deep learning workloads. We show that the resulting efficiency and reliability gains with Singularity are achieved with negligible impact on the steady-state performance. Finally, our design approach is agnostic of DNN architectures and handles a variety of parallelism strategies (e.g., data/pipeline/model parallelism).